







智能文档处理(Intelligent Document Processing,简称 IDP)已成为众多行业将大量非结构化数据转化为结构化、可操作信息的关键工作流程(利用 Gemini 构建 PDF 文档 AI 管道:原理、实现与应用(含代码))。从发票、驾照到各类报告,这些海量的文档数据蕴含着巨大的商业价值,但传统处理方式往往效率低下且准确性难以保证。而谷歌的 Gemini 2.0 模型与开源框架 ExtractThinker 的结合,为解决这一难题带来了新的曙光。
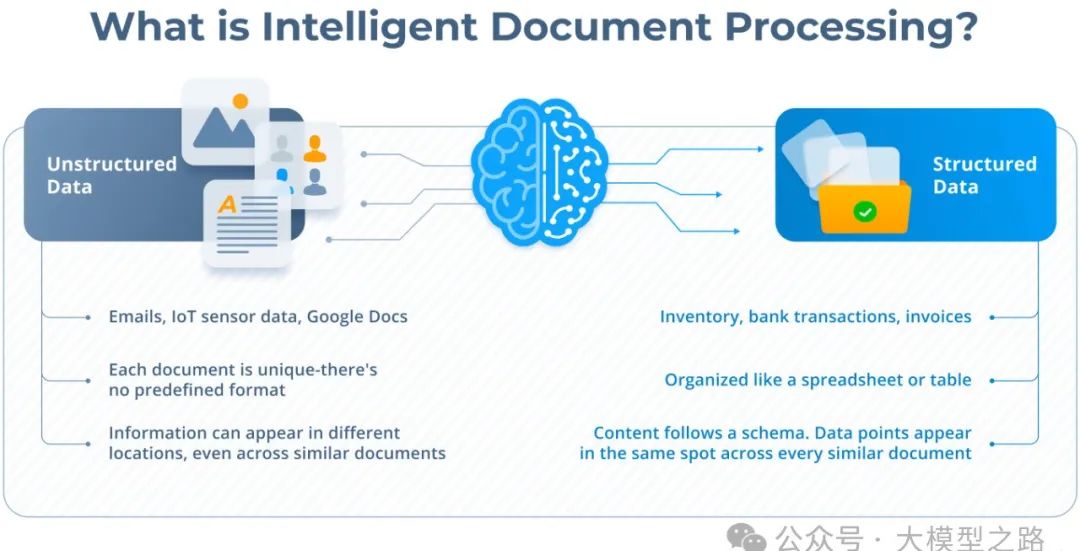
一、智能文档处理的挑战与现状
在传统的 IDP 流程中,将非结构化数据(如发票、驾照和报告等)转化为结构化信息是一项极具挑战性的任务。虽然大型语言模型(LLMs)如今能够直接处理图像和 PDF 文件(ParseStudio:使用统一语法简化PDF文档解析),但仅仅将图像输入到 LLM 中并期望获得完美的结果往往是不现实的。一个强大的 IDP 管道需要结合多种技术和步骤,包括 OCR 或其他布局提取工具(如 Google Document AI、Tesseract 或 PyPDF)、分类以识别文档类型(发票、合同、执照等)、拆分以处理大型组合文件并将其分解为逻辑部分,以及提取以将信息映射到结构化的 Pydantic 模型(如提取发票编号、日期、总金额或解读图表数据)。然而,实现这样一个完整且高效的 IDP 流程并非易事,不同工具之间的协同、数据处理的准确性和效率等都是需要攻克的难题。
二、Google Document AI:IDP 的重要基石
在深入探讨基于 LLM 的提取之前,不得不提及 Google Document AI。它是谷歌云提供的一种解决方案,具备 OCR、结构解析、分类以及专业领域提取器(如发票解析、W2 表格、银行对账单等)等功能。其定价方面,Document OCR 为每 1000 页 1.50 美元(每月上限 500 万页,更高用量有进一步折扣);Form Parser 和 Custom Extractor 为每 1000 页 30 美元(100 万页 / 月后有折扣);Layout Parser 为每 1000 页 10 美元;预训练的专业处理器(如美国驾照解析器或发票解析器)则按每份文档或每页收费(例如,发票解析每 10 页 0.10 美元)。
当使用 ExtractThinker 时,可以将 DocumentLoaderDocumentAI 附加到基于 LLM 的管道中,实现与 Document AI OCR 或表单解析的统一。这种协同作用十分强大:Document AI 可靠地提取文本,而 Gemini 或其他模型则对这些文本(以及图像)进行解读,以生成高级结构化输出。值得注意的是,在使用时应根据实际情况选择合适的处理器,例如在有视觉功能的情况下,首选 Document OCR 并搭配视觉功能;若视觉功能不可用,则可使用 Layout Parser。
三、Gemini 2.0:多模态模型的新突破
Gemini 2.0 (
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3013
3013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











