




Fast Vision Transformers with HiLo Attention
论文地址:
https://arxiv.org/abs/2205.13213![]() https://arxiv.org/abs/2205.13213
https://arxiv.org/abs/2205.13213
论文解决的问题:
-
ViTs的实际运行速度慢:
- 现有的ViTs设计依赖于间接指标(如FLOPs),但这些指标并不总能准确反映在实际硬件上的运行速度。
- ViTs在实际应用中,尤其是在移动和边缘设备上,运行速度较慢,限制了其广泛应用。
-
效率与性能的权衡:
- 传统的ViTs在保持高分类准确率的同时,往往伴随着较高的计算成本。
- 需要找到一种方法,在保持或提升模型性能的同时,提高其在实际硬件上的运行效率。
解决方案:
-
直接速度评估原则:
- 提出使用目标平台上的直接速度评估作为设计高效ViTs的原则,确保设计的模型在实际应用中具有更高的吞吐量。
- 通过这种方式,可以更准确地优化模型的实际运行速度。
-
LITv2模型:
- 提出了LITv2模型,这是一个简单而有效的ViT变体,它在不同的模型大小下都表现出优异的性能。
- LITv2的设计考虑了直接速度评估,使其在保持性能的同时,运行速度更快。
-
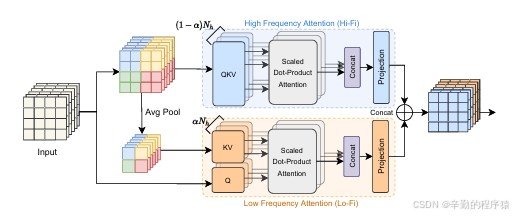
HiLo注意力机制:
- 高频与低频分离:
- 将注意力头分为高频组(Hi)和低频组(Lo),分别处理图像中的高频细节和低频结构信息。
- 这种分离使得模型能够更有效地利用计算资源,提高处理速度。
- 局部窗口内的自注意力(Hi):
- 高频组在每个局部窗口内执行自注意力,捕捉图像中的局部细节和高频信息。
- 局部窗口减少了计算复杂度,提高了效率。
- 全局注意力(Lo):
- 低频组通过在平均池化的低频键和值之间执行全局注意力,编码图像的全局结构和低频信息。
- 全局注意力有助于模型理解图像的整体内容,同时计算成本较低。
- 高频与低频分离:
注意力的适用性问题:
-
多种视觉任务:
- HiLo注意力机制由于其独特的处理方式,适用于图像分类、密集检测、分割等多种视觉任务。
- 它能够根据任务需求,灵活地处理不同层次的信息。
-
跨领域应用:
- HiLo注意力机制可以扩展到视频处理、医学图像分析等领域,其中区分局部细节和全局结构同样重要。
- 在这些领域,HiLo注意力可以帮助模型更好地理解时间序列数据或复杂的医学图像结构。
在目标检测任务中的应用:
-
特征提取:
- HiLo注意力可以集成到目标检测网络的特征提取阶段,增强特征表示,帮助网络更好地捕捉目标的关键特征。
- 在特征提取阶段使用HiLo注意力,可以使得网络更加关注目标的局部细节和全局结构,提高检测精度。
-
注意力模块:
- 在目标检测网络中的注意力模块中应用HiLo注意力,可以替换或补充现有的注意力机制。
- HiLo注意力可以帮助网络更有效地关注目标区域,抑制背景噪声,从而提高检测性能。
-
具体位置:
- 可以在目标检测网络的主干网络之后引入HiLo注意力,用于增强特征图的表达能力。
- 在特征金字塔网络(FPN)的各个层级中使用HiLo注意力,有助于在不同尺度的特征图上保持目标的细节和结构信息。
- 在RPN(Region Proposal Network)或检测头中应用HiLo注意力,可以改善候选区域的生成和最终的边界框回归。
通过这些详细的分析,可以看出HiLo注意力机制不仅解决了ViTs在实际应用中的速度问题,还为多种视觉任务提供了高效的解决方案,特别是在目标检测任务中,它能够显著提升模型的性能和效率。
即插即用代码:
import math
import torch
import torch.nn as nn
class HiLo(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., window_size=2, alpha=0.5):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
head_dim = int(dim/num_heads)
self.dim = dim
# self-attention heads in Lo-Fi
self.l_heads = int(num_heads * alpha)
# token dimension in Lo-Fi
self.l_dim = self.l_heads * head_dim
# self-attention heads in Hi-Fi
self.h_heads = num_heads - self.l_heads
# token dimension in Hi-Fi
self.h_dim = self.h_heads * head_dim
# local window size. The `s` in our paper.
self.ws = window_size
if self.ws == 1:
# ws == 1 is equal to a standard multi-head self-attention
self.h_heads = 0
self.h_dim = 0
self.l_heads = num_heads
self.l_dim = dim
self.scale = qk_scale or head_dim ** -0.5
# Low frequence attention (Lo-Fi)
if self.l_heads > 0:
if self.ws != 1:
self.sr = nn.AvgPool2d(kernel_size=window_size, stride=window_size)
self.l_q = nn.Linear(self.dim, self.l_dim, bias=qkv_bias)
self.l_kv = nn.Linear(self.dim, self.l_dim * 2, bias=qkv_bias)
self.l_proj = nn.Linear(self.l_dim, self.l_dim)
# High frequence attention (Hi-Fi)
if self.h_heads > 0:
self.h_qkv = nn.Linear(self.dim, self.h_dim * 3, bias=qkv_bias)
self.h_proj = nn.Linear(self.h_dim, self.h_dim)
def hifi(self, x):
B, H, W, C = x.shape
h_group, w_group = H // self.ws, W // self.ws
total_groups = h_group * w_group
x = x.reshape(B, h_group, self.ws, w_group, self.ws, C).transpose(2, 3)
qkv = self.h_qkv(x).reshape(B, total_groups, -1, 3, self.h_heads, self.h_dim // self.h_heads).permute(3, 0, 1, 4, 2, 5)
q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
attn = (q @ k.transpose(-2, -1)) * self.scale # B, hw, n_head, ws*ws, ws*ws
attn = attn.softmax(dim=-1)
attn = (attn @ v).transpose(2, 3).reshape(B, h_group, w_group, self.ws, self.ws, self.h_dim)
x = attn.transpose(2, 3).reshape(B, h_group * self.ws, w_group * self.ws, self.h_dim)
x = self.h_proj(x)
return x
def lofi(self, x):
B, H, W, C = x.shape
q = self.l_q(x).reshape(B, H * W, self.l_heads, self.l_dim // self.l_heads).permute(0, 2, 1, 3)
if self.ws > 1:
x_ = x.permute(0, 3, 1, 2)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
kv = self.l_kv(x_).reshape(B, -1, 2, self.l_heads, self.l_dim // self.l_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.l_kv(x).reshape(B, -1, 2, self.l_heads, self.l_dim // self.l_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.l_dim)
x = self.l_proj(x)
return x
def forward(self, x, H, W):
B, N, C = x.shape
x = x.reshape(B, H, W, C)
if self.h_heads == 0:
x = self.lofi(x)
return x.reshape(B, N, C)
if self.l_heads == 0:
x = self.hifi(x)
return x.reshape(B, N, C)
hifi_out = self.hifi(x)
lofi_out = self.lofi(x)
x = torch.cat((hifi_out, lofi_out), dim=-1)
x = x.reshape(B, N, C)
return x
def flops(self, H, W):
# pad the feature map when the height and width cannot be divided by window size
Hp = self.ws * math.ceil(H / self.ws)
Wp = self.ws * math.ceil(W / self.ws)
Np = Hp * Wp
# For Hi-Fi
# qkv
hifi_flops = Np * self.dim * self.h_dim * 3
nW = (Hp // self.ws) * (Wp // self.ws)
window_len = self.ws * self.ws
# q @ k and attn @ v
window_flops = window_len * window_len * self.h_dim * 2
hifi_flops += nW * window_flops
# projection
hifi_flops += Np * self.h_dim * self.h_dim
# for Lo-Fi
# q
lofi_flops = Np * self.dim * self.l_dim
kv_len = (Hp // self.ws) * (Wp // self.ws)
# k, v
lofi_flops += kv_len * self.dim * self.l_dim * 2
# q @ k and attn @ v
lofi_flops += Np * self.l_dim * kv_len * 2
# projection
lofi_flops += Np * self.l_dim * self.l_dim
return hifi_flops + lofi_flops
if __name__ == '__main__':
block = HiLo(dim=128)
input = torch.rand(32, 128, 128)
output = block(input, 16, 8)
print(input.size())
print(output.size())大家对于YOLO改进感兴趣的可以进群了解,群中有答疑,(QQ群:828370883)


















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









