







从2016年4月底开始接触Flink,到现在已经8个多月了。从了解到熟悉,再到实际开发,这个过程就是我从0到实际开发使用Flink的过程。
上周,我们的Flink流计算程序终于上线了。也算是在实时流计算方面的一个成果。
下面,我将简要介绍下公司如何使用Flink进行流处理的开发。
1、简介
我们主要是针对股票市场,进行实时的流处理,统计出各种相关的指标,并将输出提供给公司的产品用作展示和一些策略的生成。
2、为什么选用Apache Flink ?
公司要求提供的数据以低延迟为首要目标,同时尽可能保证正确性与较低的成本。我们的需求类似于下图中的描述:
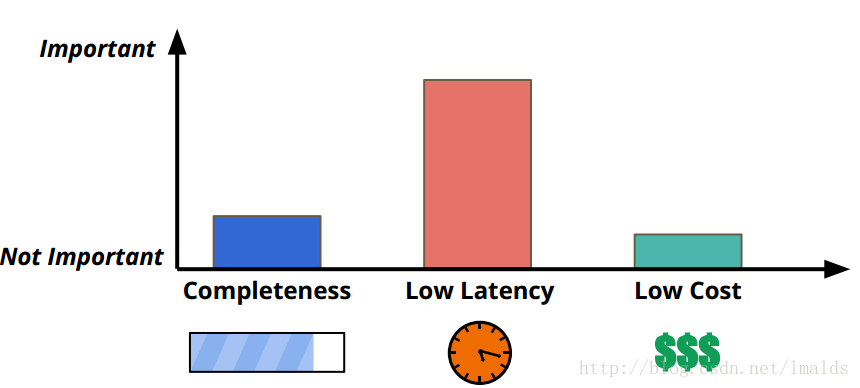
在选型阶段,开源的分布式流处理的框架主要有Storm、Spark Streaming以及Flink等。
1、Spark Streaming: 当时正值Spark非常火爆的时期,但是其micro-batch的本质决定了其提供低延迟的能力相对较弱,不能满足我们的需求,故放弃了Spark。
2、Storm: Storm可是说是低延迟的代表,但是其本身在吞吐量以及不能很好的提供exactly-once的处理(trident又回归批处理了),同时对于session window和state的支持都不够好,因此也没有使用。
3、Flink: 一个非常新(仅听说过)的纯流式计算框架,能够提供低延迟、带状态的操作、提供基于event time的处理,同时支持session window以及处理乱序的能力,使得我们最终选择了Flink。Flink特性:

2、面临的挑战
选择Flink,当时来讲不得不说是一次大胆的尝试,对于Google Cloud DataFlow,Flink算是对其论文实现最好的框架了,但是也是资料最少的一个框架。(当时都不知道国内有哪些公司在用,中文资料更是很少)
学习之初,只有官方文档和源代码,中文的资料当时除了2篇概括性的文章外(深入理解Apache Flink核心技术,新一代大数据处理引擎 Apache Flink),就只有VinoYang’sBlog以及
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3358
3358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









