






源自:指挥与控制学报 作者:张婷婷 杨学军 “人工智能技术与咨询” 发布
摘要
针对城市场景下巡飞弹自主协同饱和攻击问题, 将其建模为分布式部分可观测马尔可夫决策过程(Dec-POMDPs) , 设计了确保巡飞弹在极小时间间隔内到达的专用奖励函数, 并结合使用联合权重参数的奖励函数, 采用循环多智能体深度确定性策略梯度算法 (R-MADDPG) 训练巡飞弹自主协同饱和攻击策略, 使用蒙特卡罗方法分析指标成功率. 仿真实验结果表明, 在训练后的决策模型引导下, 巡飞弹执行自主协同饱和攻击的任务成功率为 93.2%, 其中, 机间避撞率为 94.4%、空中突防成功率为 99.5%, 95.3%回合到达最大时间间隔小于 0.4 s.
关键词
巡飞弹, 饱和攻击, R-MADDPG 算法, 自主协同决策, 评估指标





1城市场景下巡飞弹自主协同饱和攻击问题分析


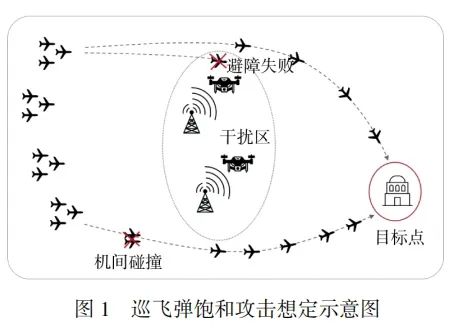

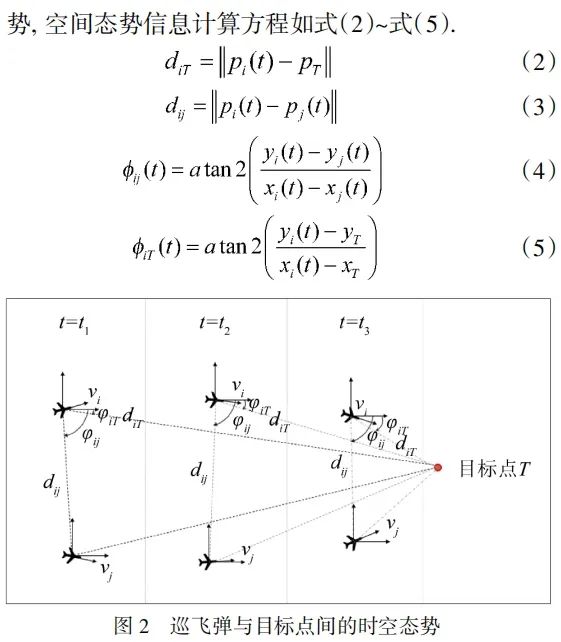

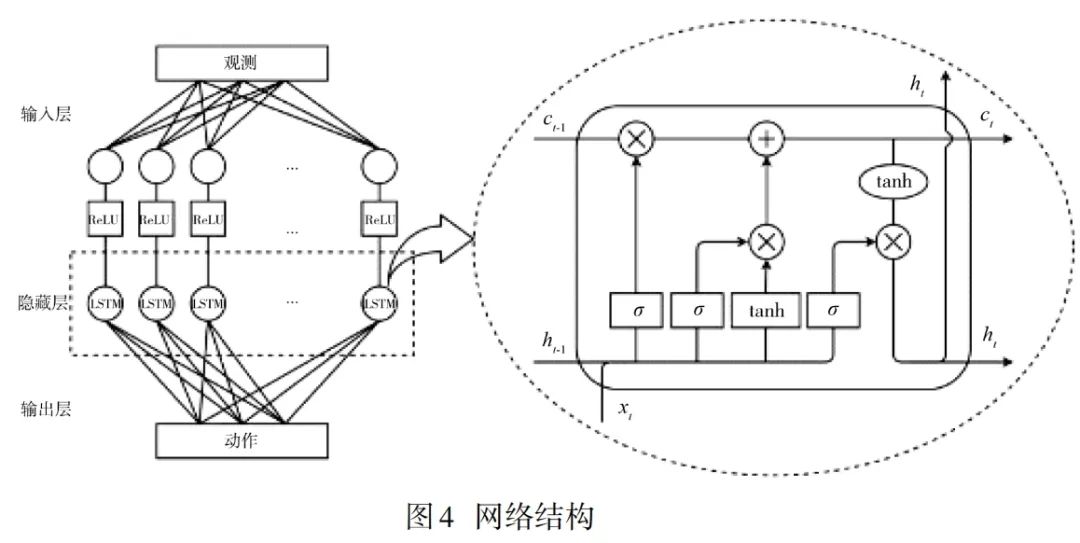
2 巡飞弹自主协同饱和攻击决策模型




3 巡飞弹自主协同饱和攻击策略求解方法




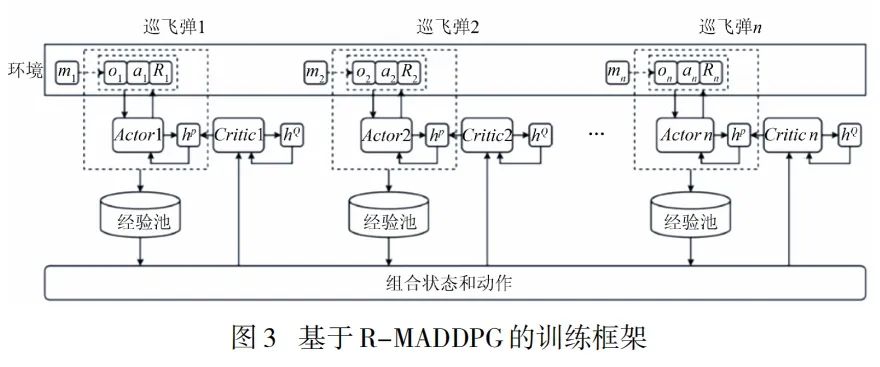

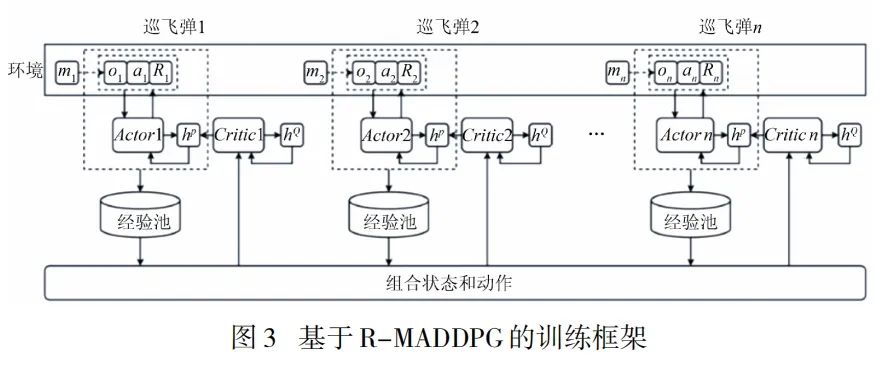









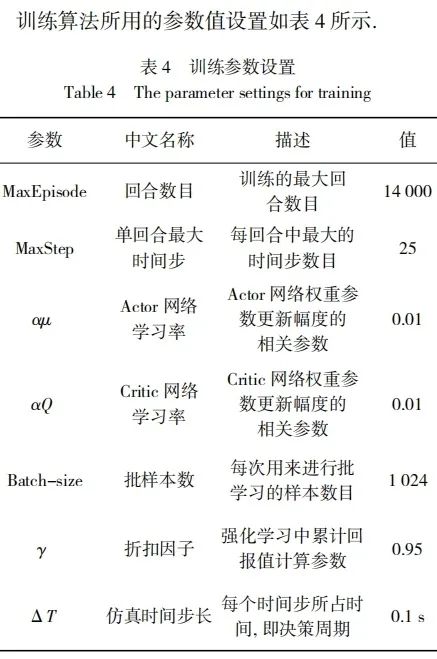
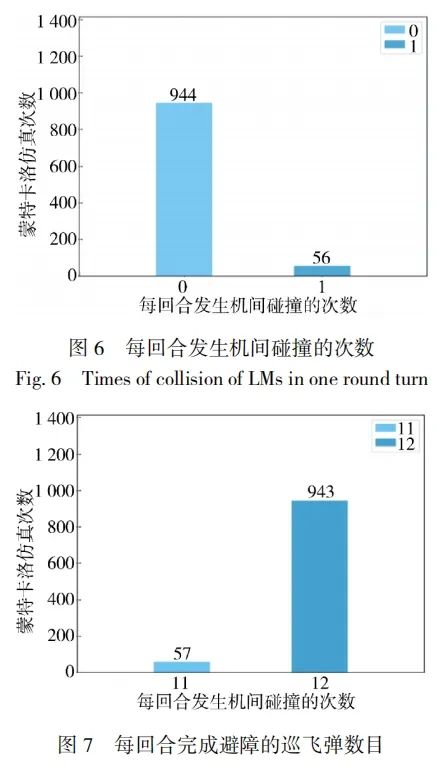
4 仿真验证







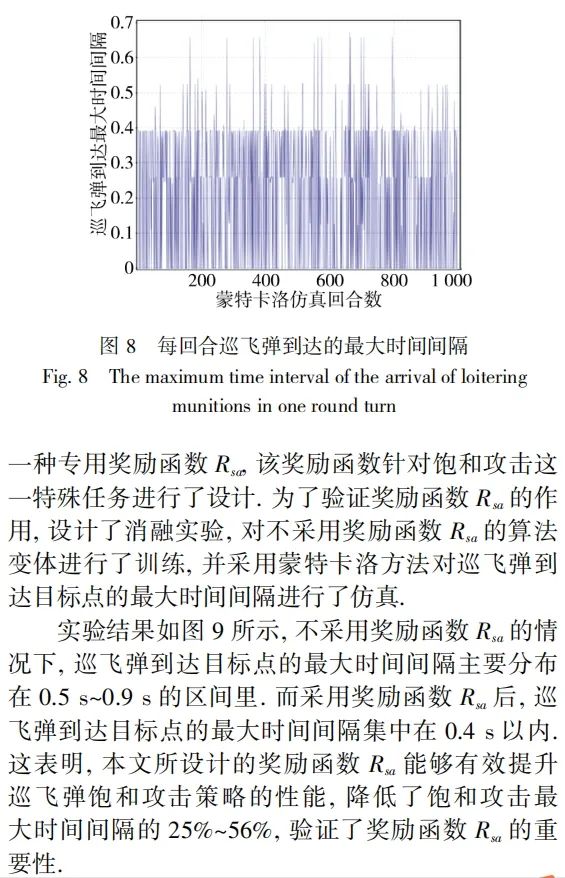
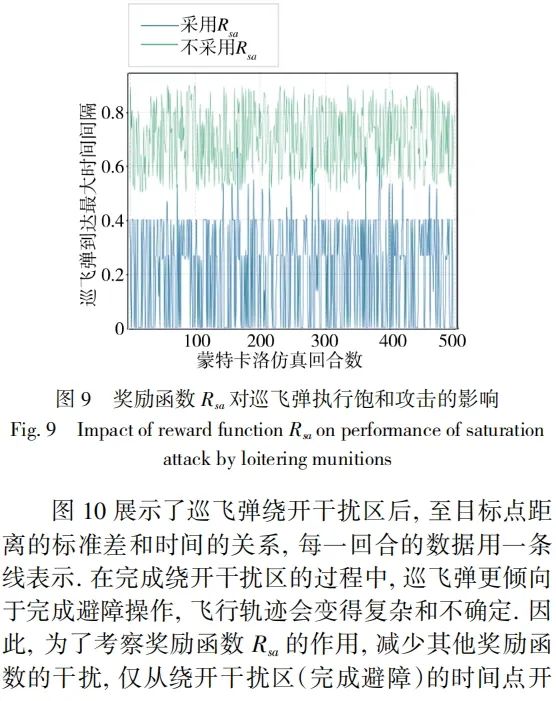
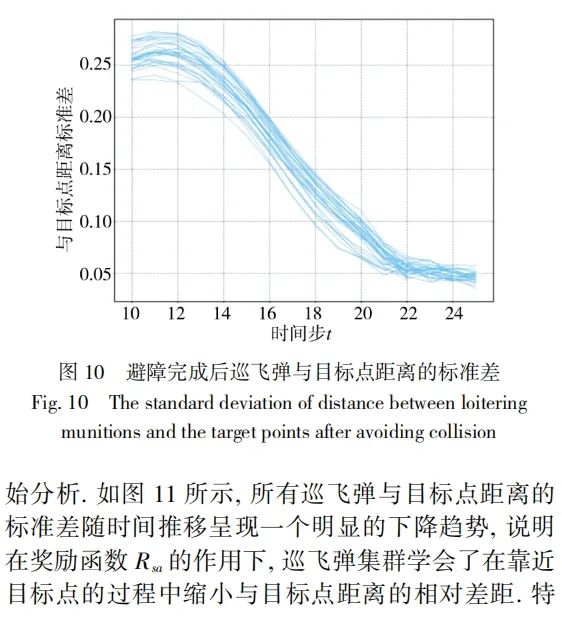
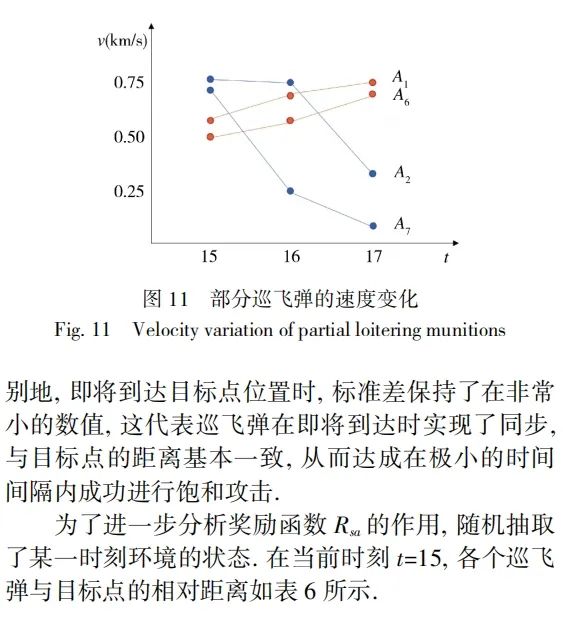
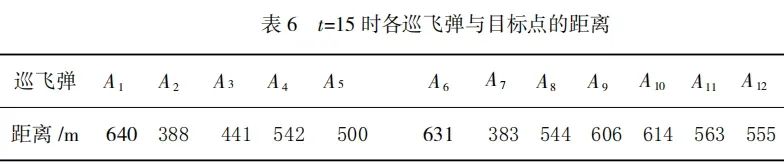

5 结论


声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询” 发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









