







 超级会员免费看
超级会员免费看
 本文介绍了如何使用NVIDIA的NeMo框架快速实现ASR语音识别和TTS语音合成。通过NeMo的Quartznet模型进行ASR推理与训练,详细讲解了数据集制作、模型训练与评估。同时,对于TTS部分,文章涵盖了Tacotron2模型的训练过程,包括生成频谱图和使用Hifigan声码器合成语音。
本文介绍了如何使用NVIDIA的NeMo框架快速实现ASR语音识别和TTS语音合成。通过NeMo的Quartznet模型进行ASR推理与训练,详细讲解了数据集制作、模型训练与评估。同时,对于TTS部分,文章涵盖了Tacotron2模型的训练过程,包括生成频谱图和使用Hifigan声码器合成语音。
本文转自语音之家分享
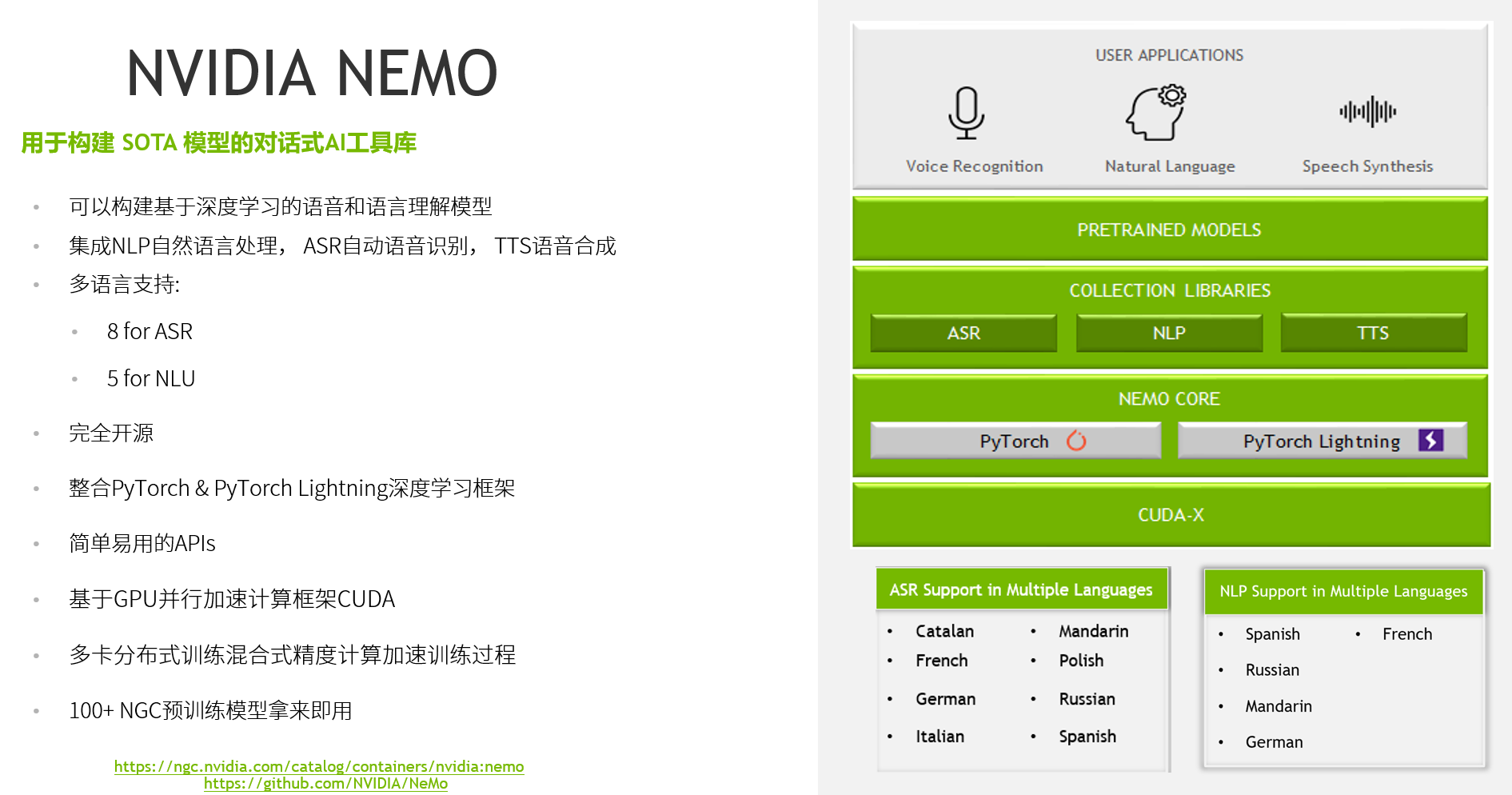
关于 NVIDIA NeMo
- 官网:https://developer.nvidia.com/nvidia-nemo
- github : https://github.com/NVIDIA/NeMo
- 官方文档:https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/starthere/intro.html
- pre-trained models : https://catalog.ngc.nvidia.com/models
NVIDIA NeMo™ is an open-source framework for developers to build and train state-of-the-art conversational AI models.
NVIDIA NeMo是NVIDIA AI平台的一部分,是一个用于构建新的最先进对话式AI模型的工具包。
NeMo为自动语音识别(ASR)、自然语言处理(NLP)和文本到语音(TTS)合成模型提供了单独的集合。
每个集合都由预构建的模块组成,这些模块包括训练数据所需的一切。每个模块都可以轻松定制、扩展和组合,以创建新的对话式AI模型架构。
对话式AI架构通常很大,需要大量数据和计算进行训练。NeMo使用PyTorch Lightning进行简单高效的多GPU/多节点混合精度训练。
通过NeMo快速实现ASR语音识别模型

推理
0 导入NeMo及asr工具类
import nemo
import nemo.collections.asr as nemo_asr
[NeMo W 2023-02-28 19:08:05 experimental:27] Module <class 'nemo.collections.asr.models.audio_to_audio_model.AudioToAudioModel'> is experimental, not ready for production and is not fully supported. Use at your own risk.
################################################################################
### WARNING, path does not exist: KALDI_ROOT=/mnt/matylda5/iveselyk/Tools/kaldi-trunk
### (please add 'export KALDI_ROOT=<your_path>' in your $HOME/.profile)
### (or run as: KALDI_ROOT=<your_path> python <your_script>.py)
################################################################################
[NeMo W 2023-02-28 19:08:06 experimental:27] Module <class 'nemo.collections.asr.modules.audio_modules.SpectrogramToMultichannelFeatures'> is experimental, not ready for production and is not fully supported. Use at your own risk.
[NeMo W 2023-02-28 19:08:06 nemo_logging:349] /root/miniconda3/lib/python3.8/site-packages/torch/jit/annotations.py:296: UserWarning: TorchScript will treat type annotations of Tensor dtype-specific subtypes as if they are normal Tensors. dtype constraints are not enforced in compilation either.
warnings.warn("TorchScript will treat type annotations of Tensor "
[NeMo W 2023-02-28 19:08:06 experimental:27] Module <class 'nemo.collections.asr.data.audio_to_audio.BaseAudioDataset'> is experimental, not ready for production and is not fully supported. Use at your own risk.
[NeMo W 2023-02-28 19:08:06 experimental:27] Module <class 'nemo.collections.asr.data.audio_to_audio.AudioToTargetDataset'> is experimental, not ready for production and is not fully supported. Use at your own risk.
[NeMo W 2023-02-28 19:08:06 experimental:27] Module <class 'nemo.collections.asr.data.audio_to_audio.AudioToTargetWithReferenceDataset'> is experimental, not ready for production and is not fully supported. Use at your own risk.
[NeMo W 2023-02-28 19:08:06 experimental:27] Module <class 'nemo.collections.asr.data.audio_to_audio.AudioToTargetWithEmbeddingDataset'> is experimental, not ready for production and is not fully supported. Use at your own risk.
[NeMo W 2023-02-28 19:08:06 experimental:27] Module <class 'nemo.collections.asr.models.enhancement_models.EncMaskDecAudioToAudioModel'> is experimental, not ready for production and is not fully supported. Use at your own risk.
1.1 加载Quartznet自动语音识别模型
quartznet = nemo_asr.models.EncDecCTCModel.restore_from("stt_zh_quartznet15x5.nemo")# 加载中文预训练模型并实例化
[NeMo W 2023-02-28 19:13:45 modelPT:156] If you intend to do training or fine-tuning, please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.
Train config :
manifest_filepath: /home/jbalam/aishell_exp/models/manifest.train
sample_rate: 16000
labels:
- ' '
- ''''
- A
- B
- C
...
- 'Y'
- Z
- 㶧
- 䶮
- 一
- 丁
- 七
- 万
- 丈
...
- 龌
- 龙
- 龚
- 龟
- 𫖯
- 𫚉
batch_size: 32
trim_silence: true
normalize: false
max_duration: 16.7
shuffle: true
is_tarred: false
tarred_audio_filepaths: null
tarred_shard_strategy: scatter
[NeMo W 2023-02-28 19:13:45 modelPT:163] If you intend to do validation, please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s).
Validation config :
manifest_filepath: /home/jbalam/aishell_exp/models/dev.json
sample_rate: 16000
normalize: false
labels:
- ' '
- ''''
- A
- B
- C
...
- 'Y'
- Z
- 㶧
- 䶮
- 一
- 丁
- 七
- 万
- 丈
- 三
...
- 龊
- 龌
- 龙
- 龚
- 龟
- 𫖯
- 𫚉
batch_size: 32
shuffle: false
[NeMo I 2023-02-28 19:13:45 features:267] PADDING: 16
[NeMo I 2023-02-28 19:13:49 save_restore_connector:243] Model EncDecCTCModel was successfully restored from /root/Speechhome/stt_zh_quartznet15x5.nemo.
1.2 传入音频文件 — 进行语音识别
asr_result = quartznet.transcribe(paths2audio_files=["/root/testdata/cat_t.wav"]) # 调用transcribe函数测试预训练模型识别效果
print(asr_result)
Transcribing: 0%| | 0/1 [00:00<?, ?it/s]
['请指出哪张序列号的图片是猫']
1.3 使用ASR_mertrics工具库对预训练模型识别结果计算准确率
from ASR_metrics import utils as metrics
s1 = "请指出哪张序列号的图片是猫"#指定正确答案
s2 = " ".join(asr_result)#识别结果
print("字错率:{}".format(metrics.calculate_cer(s1,s2)))#计算字错率cer
print("准确率:{}".format(1-metrics.calculate_cer(s1,s2)))#计算准确率accuracy
训练
2 采集数据制作数据集
2.1 录制语音文件:
- 录制语音文件,文件类型需统一转换为wav格式,采样率建议在16000-44100HZ 、单声道。
- 通过录音软件Audacity录制:Ubuntu系统安装=>sudo apt install audacity
- windows系统可用此网址下载安装:https://www.onlinedown.net/soft/46359.htm
2.2 制作数据清单格式要求:

# 导入librosa音频工具包获取音频时长,用于制作语音数据集
import librosa
time = librosa.get_duration(filename="/root/testdata/all6.wav")
print(time)
4.458231292517007
2.3 加载数据清单
#将制作好的json格式的数据清单加载进来
train_manifest = "/root/manifest/train_manifest.json"
val_manifest = "/root/manifest/test_manifest.json"
2.4 加载quartznet配置文件
# 使用YAML读取quartznet模型配置文件
try:
from ruamel.yaml import YAML
except ModuleNotFoundError:
from ruamel_yaml import YAML
config_path ="/root/config/quartznet_15x5_zh.yaml"
yaml = YAML(typ='safe')
with open(config_path) as f:
params = yaml.load(f)
print(params)
{'name': 'QuartzNet15x5', 'model': {'sample_rate': 16000, 'repeat': 5, 'dropout': 0.0, 'separable': True, 'labels': [' ', "'", 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '㶧', '䶮', '一', '丁', '七', '万', '丈', '三', '上', '下', '不', '与', '丐', '丑', '专', '且', '丕', '世', '丘', '丙', '业', '丛', '东', '丝', '丞', '丢', '两', ... '龙', '龚', '龟', '𫖯', '𫚉'], 'batch_size': 32, 'trim_silence': True, 'normalize': False, 'max_duration': 16.7, 'shuffle': True, 'is_tarred': False, 'tarred_audio_filepaths': None}, 'validation_ds': {'manifest_filepath': '???', 'sample_rate': 16000, 'normalize': False, 'labels': [' ', "'", 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '㶧', '䶮', '一', '丁', '七', '万', '丈', '三', '上', '下', '不', '与', '丐', '丑', '专', '且', '丕', '世', '丘', '丙', '业', '丛', '东', '丝', '丞', '丢', '两', '严', '丧', '个', '丫', '中', '丰', '串', '临', '丸', '丹', '为', '主',
...
'麓', '麝', '麟', '麦', '麸', '麻', '麾', '黄', '黍', '黎', '黏', '黑', '黔', '默', '黛', '黝', '黟', '黯', '鼎', '鼓', '鼠', '鼬', '鼹', '鼻', '鼾', '齐', '齿', '龃', '龄', '龅', '龈', '龉', '龊', '龌', '龙', '龚', '龟', '𫖯', '𫚉'], 'batch_size': 32, 'shuffle': True}, 'preprocessor': {'cls': 'nemo.collections.asr.modules.AudioToMelSpectrogramPreprocessor', 'params': {'normalize': 'per_feature', 'window_size': 0.02, 'sample_rate': 16000, 'window_stride': 0.01, 'window': 'hann', 'features': 64, 'n_fft': 512, 'frame_splicing': 1, 'dither': 1e-05, 'stft_conv': False}}, 'spec_augment': {'cls': 'nemo.collections.asr.modules.SpectrogramAugmentation', 'params': {'rect_freq': 50, 'rect_masks': 5, 'rect_time': 120}}, 'encoder': {'cls': 'nemo.collections.asr.modules.ConvASREncoder', 'params': {'feat_in': 64, 'activation': 'relu', 'conv_mask': True, 'jasper': [{'dilation': [1], 'dropout': 0.0, 'filters': 256, 'kernel': [33], 'repeat': 1, 'residual': False, 'separable': True, 'stride': [2]}, {'dilation': [1], 'dropout': 0.0, 'filters': 256, 'kernel': [33], 'repeat': 5, 'residual': True, 'separable': True, 'stride': [1]},
...
{'dilation': [2], 'dropout': 0.0, 'filters': 512, 'kernel': [87], 'repeat': 1, 'residual': False, 'separable': True, 'stride': [1]}, {'dilation': [1], 'dropout': 0.0, 'filters': 1024, 'kernel': [1], 'repeat': 1, 'residual': False, 'stride': [1]}]}}, 'decoder': {'cls': 'nemo.collections.asr.modules.ConvASRDecoder', 'params': {'feat_in': 1024, 'num_classes': 5206, 'vocabulary': [' ', "'", 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '㶧', '䶮', '一', '丁', '七', '万', '丈', '三', '上', '下', '不', '与', '丐', '丑', '专', '且', '丕', '世', '丘', '丙', '业', '丛', '东', '丝', '丞', '丢', '两', '严', '丧', '个', '丫', '中', '丰', '串', '临', '丸', '丹', '为', '主', '丽', '举', '乃', '久', '么', '义', '之', '乌', '乍', '乎', '乏', '乐', '乒', '乓', '乔', '乖', '乘', '乙',
...
'鼎', '鼓', '鼠', '鼬', '鼹', '鼻', '鼾', '齐', '齿', '龃', '龄', '龅', '龈', '龉', '龊', '龌', '龙', '龚', '龟', '𫖯', '𫚉']}}, 'optim': {'name': 'novograd', 'lr': 0.01, 'betas': [0.8, 0.5], 'weight_decay': 0.001, 'sched': {'name': 'CosineAnnealing', 'warmup_steps': None, 'warmup_ratio': None, 'min_lr': 0.0, 'last_epoch': -1}}}, 'trainer': {'gpus': 0, 'max_epochs': 5, 'max_steps': None, 'num_nodes': 1, 'accelerator': 'ddp', 'accumulate_grad_batches': 1, 'checkpoint_callback': False, 'logger': False, 'log_every_n_steps': 1, 'val_check_interval': 1.0}, 'exp_manager': {'exp_dir': None, 'name': 'QuartzNet15x5', 'create_tensorboard_logger': True, 'create_checkpoint_callback': True, 'create_wandb_logger': False, 'wandb_logger_kwargs': {'name': None, 'project': None}}, 'hydra': {'run': {'dir': '.'}, 'job_logging': {'root': {'handlers': None}}}}
2.5 将数据清单传给配置文件
params['model']['train_ds']['manifest_filepath']=train_manifest
params['model']['validation_ds']['manifest_filepath']=val_manifest
3 训练模型
3.1 使用迁移学习的方法训练模型
quartznet.setup_training_data(train_data_config=params['model']['train_ds'])
quartznet.setup_validation_data(val_data_config=params['model']['validation_ds'])
import pytorch_lightning as pl
trainer = pl.Trainer(gpus=1,max_epochs=8)
trainer.fit(quartznet)#调用‘fit’方法开始训练
[NeMo I 2023-02-28 19:26:12 collections:193] Dataset loaded with 28 files totalling 0.04 hours
[NeMo I 2023-02-28 19:26:12 collections:194] 0 files were filtered totalling 0.00 hours
[NeMo I 2023-02-28 19:26:15 collections:193] Dataset loaded with 4 files totalling 0.01 hours
[NeMo I 2023-02-28 19:26:15 collections:194] 0 files were filtered totalling 0.00 hours
[NeMo W 2023-02-28 19:26:15 nemo_logging:349] /root/miniconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py:441: LightningDeprecationWarning: Setting `Trainer(gpus=1)` is deprecated in v1.7 and will be removed in v2.0. Please use `Trainer(accelerator='gpu', devices=1)` instead.
rank_zero_deprecation(
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
[NeMo I 2023-02-28 19:26:15 modelPT:616] Optimizer config = Novograd (
Parameter Group 0
amsgrad: False
betas: [0.8, 0.5]
eps: 1e-08
grad_averaging: False
lr: 0.01
weight_decay: 0.001
)
[NeMo I 2023-02-28 19:26:15 lr_scheduler:910] Scheduler "<nemo.core.optim.lr_scheduler.CosineAnnealing object at 0x7fa72aebb7c0>"
will be used during training (effective maximum steps = 8) -
Parameters :
(warmup_steps: null
warmup_ratio: null
min_lr: 0.0
last_epoch: -1
max_steps: 8
)
| Name | Type | Params
------------------------------------------------------------------------
0 | preprocessor | AudioToMelSpectrogramPreprocessor | 0
1 | encoder | ConvASREncoder | 18.9 M
2 | decoder | ConvASRDecoder | 5.3 M
3 | loss | CTCLoss | 0
4 | spec_augmentation | SpectrogramAugmentation | 0
5 | _wer | WER | 0
------------------------------------------------------------------------
24.2 M Trainable params
0 Non-trainable params
24.2 M Total params
96.927 Total estimated model params size (MB)
Sanity Checking: 0it [00:00, ?it/s]
[NeMo W 2023-02-28 19:26:18 nemo_logging:349] /root/miniconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:488: PossibleUserWarning: Your `val_dataloader`'s sampler has shuffling enabled, it is strongly recommended that you turn shuffling off for val/test/predict dataloaders.
rank_zero_warn(
[NeMo W 2023-02-28 19:26:18 nemo_logging:349] /root/miniconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:224: PossibleUserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 8 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
[NeMo W 2023-02-28 19:26:20 nemo_logging:349] /root/miniconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:224: PossibleUserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 8 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
[NeMo W 2023-02-28 19:26:20 nemo_logging:349] /root/miniconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:1595: PossibleUserWarning: The number of training batches (1) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
rank_zero_warn(
Training: 0it [00:00, ?it/s]
Validation: 0it [00:00, ?it/s]
…
Validation: 0it [00:00, ?it/s]
`Trainer.fit` stopped: `max_epochs=8` reached.
3.2模型的保存
quartznet.save_to("7th_asr_model_try.nemo")# 将训练好的模型保存为.nemo格式
3.3将训练好的模型进行重载
try_model_1 = nemo_asr.models.EncDecCTCModel.restore_from("7th_asr_model_try.nemo")#对模型进行重新加载
[NeMo W 2023-02-28 19:28:40 modelPT:156] If you intend to do training or fine-tuning, please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.
Train config :
manifest_filepath: /root/manifest/train_manifest.json
sample_rate: 16000
labels:
- ' '
- ''''
- A
- B
- C
...
- 'Y'
- Z
- 㶧
- 䶮
- 一
- 丁
- 七
...
- 龙
- 龚
- 龟
- 𫖯
- 𫚉
batch_size: 32
trim_silence: true
normalize: false
max_duration: 16.7
shuffle: true
is_tarred: false
tarred_audio_filepaths: null
[NeMo W 2023-02-28 19:28:40 modelPT:163] If you intend to do validation, please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s).
Validation config :
manifest_filepath: /root/manifest/test_manifest.json
sample_rate: 16000
normalize: false
labels:
- ' '
- ''''
- A
- B
- C
...
- 'Y'
- Z
- 㶧
- 䶮
- 一
- 丁
- 七
- 万
- 丈
...
- 龚
- 龟
- 𫖯
- 𫚉
batch_size: 32
shuffle: true
[NeMo I 2023-02-28 19:28:40 features:267] PADDING: 16
[NeMo I 2023-02-28 19:28:43 save_restore_connector:243] Model EncDecCTCModel was successfully restored from /root/Speechhome/7th_asr_model_try.nemo.
3.4 对自定义训练模型进行推理
print(try_model_1.transcribe(paths2audio_files=['/root/testdata/cat_t.wav',
'/root/testdata/dog_t.wav',],batch_size=4))
Transcribing: 0%| | 0/1 [00:00<?, ?it/s]
['请指出哪张序列号的图片猫', '请指出哪张序列号的图片是狗']
TTS语音合成模型
训练
0 导入nemo工具库及tts工具类
import nemo
import nemo.collections.tts as nemo_tts
from nemo.collections.tts.models import Tacotron2Model
from matplotlib.pyplot import imshow
from matplotlib import pyplot as plt
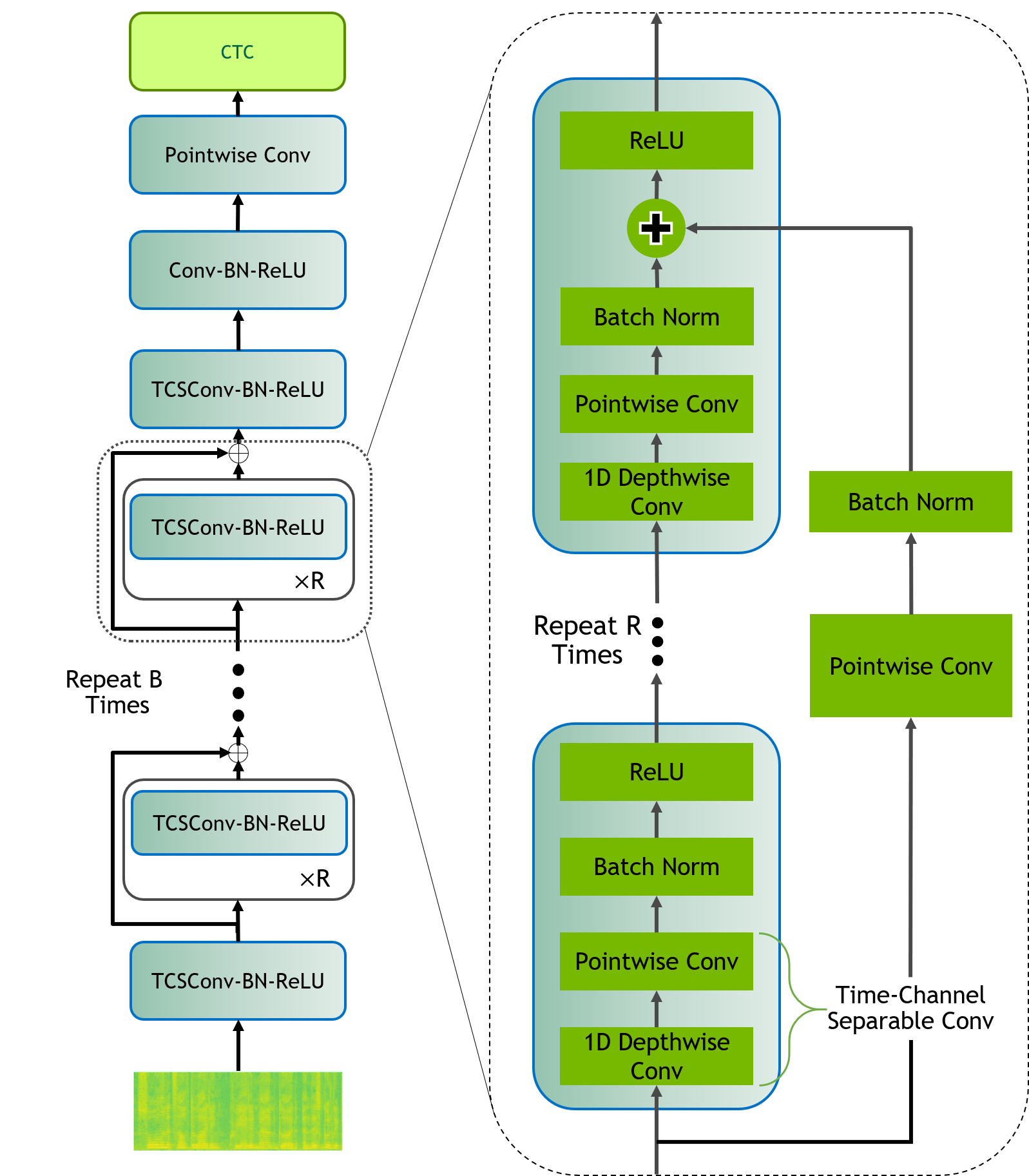
1.0 Tacotron2模型结构
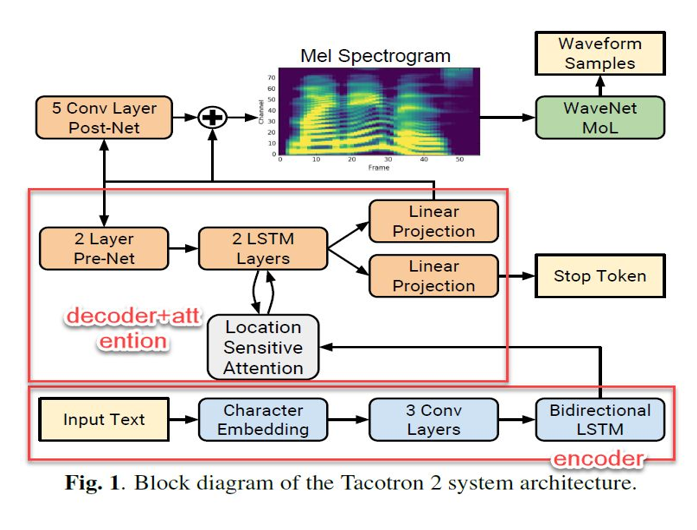
1.1 了解tacotron2.py训练脚本的代码结构

1.2 了解Tacotron2模型配置文件


1.3 录制语音文件:
- 录制语音文件,文件类型需统一转换为wav格式,采样率建议在44100HZ 、单声道。
- 通过录音软件Audacity录制:Ubuntu系统安装=>sudo apt install audacity

2.1 使用训练脚本设置相关参数进行训练:
- 指定训练集路径:
train_dataset=/root/manifest/train_manifest_tts.json - 指定验证集路径:
validation_datasets=/root/manifest/test_manifest_tts.json - 指定训练次数:
trainer.max_epochs=2500
! HYDRA_FULL_ERROR=1 \
python tacotron2.py train_dataset=/root/manifest/train_tts_6th.json \
validation_datasets=/root/manifest/test_tts_6th.json \
trainer.max_epochs=2500 \
trainer.accelerator=null \
trainer.check_val_every_n_epoch=1
2022-05-04 11:07:03.685414: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-05-04 11:07:03.685463: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
################################################################################
### WARNING, path does not exist: KALDI_ROOT=/mnt/matylda5/iveselyk/Tools/kaldi-trunk
### (please add 'export KALDI_ROOT=<your_path>' in your $HOME/.profile)
### (or run as: KALDI_ROOT=<your_path> python <your_script>.py)
################################################################################
[NeMo W 2022-05-04 11:07:06 experimental:27] Module <class 'nemo.collections.asr.data.audio_to_text_dali._AudioTextDALIDataset'> is experimental, not ready for production and is not fully supported. Use at your own risk.
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
[NeMo I 2022-05-04 11:07:07 exp_manager:220] Experiments will be logged at /root/nemo_experiments/Tacotron2/2022-05-04_11-07-07
[NeMo I 2022-05-04 11:07:07 exp_manager:569] TensorboardLogger has been set up
[NeMo W 2022-05-04 11:07:07 nemo_logging:349] /root/anaconda3/lib/python3.8/site-packages/pytorch_lightning/callbacks/model_checkpoint.py:240: LightningDeprecationWarning: `ModelCheckpoint(every_n_val_epochs)` is deprecated in v1.4 and will be removed in v1.6. Please use `every_n_epochs` instead.
rank_zero_deprecation(
[NeMo I 2022-05-04 11:07:07 collections:173] Dataset loaded with 6 files totalling 0.01 hours
[NeMo I 2022-05-04 11:07:07 collections:174] 0 files were filtered totalling 0.00 hours
[NeMo I 2022-05-04 11:07:07 collections:173] Dataset loaded with 1 files totalling 0.00 hours
[NeMo I 2022-05-04 11:07:07 collections:174] 0 files were filtered totalling 0.00 hours
[NeMo I 2022-05-04 11:07:07 features:262] PADDING: 16
[NeMo I 2022-05-04 11:07:07 features:279] STFT using torch
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
[NeMo I 2022-05-04 11:07:11 modelPT:544] Optimizer config = Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 0.001
weight_decay: 1e-06
)
[NeMo I 2022-05-04 11:07:11 lr_scheduler:621] Scheduler "<nemo.core.optim.lr_scheduler.CosineAnnealing object at 0x7f5841a11d90>"
will be used during training (effective maximum steps = 3000) -
Parameters :
(min_lr: 1.0e-05
max_steps: 3000
)
| Name | Type | Params
------------------------------------------------------------------
0 | audio_to_melspec_precessor | FilterbankFeatures | 0
1 | text_embedding | Embedding | 35.3 K
2 | encoder | Encoder | 5.5 M
3 | decoder | Decoder | 18.3 M
4 | postnet | Postnet | 4.3 M
5 | loss | Tacotron2Loss | 0
------------------------------------------------------------------
28.2 M Trainable params
0 Non-trainable params
28.2 M Total params
112.611 Total estimated model params size (MB)
Validation sanity check: 0%| | 0/1 [00:00<?, ?it/s][NeMo W 2022-05-04 11:07:12 patch_utils:49] torch.stft() signature has been updated for PyTorch 1.7+
Please update PyTorch to remain compatible with later versions of NeMo.
[NeMo W 2022-05-04 11:07:13 nemo_logging:349] /root/anaconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/data_loading.py:326: UserWarning: The number of training samples (1) is smaller than the logging interval Trainer(log_every_n_steps=200). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
rank_zero_warn(
Epoch 0: 0%| | 0/2 [00:00<00:00, 5343.06it/s][NeMo W 2022-05-04 11:07:15 nemo_logging:349] /root/anaconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/logger_connector/result.py:405: LightningDeprecationWarning: One of the returned values {'progress_bar'} has a `grad_fn`. We will detach it automatically but this behaviour will change in v1.6. Please detach it manually: `return {'loss': ..., 'something': something.detach()}`
warning_cache.deprecation(
Epoch 0: 50%|██████▌ | 1/2 [00:02<00:01, 1.50s/it, loss=83.5, v_num=7-07]
Validating: 0it [00:00, ?it/s][A
Validating: 0%| | 0/1 [00:00<?, ?it/s][A
Epoch 0: 100%|█████████████| 2/2 [00:04<00:00, 1.57s/it, loss=83.5, v_num=7-07][A
[AEpoch 0, global step 0: val_loss reached 1037.62341 (best 1037.62341), saving model to "/root/nemo_experiments/Tacotron2/2022-05-04_11-07-07/checkpoints/Tacotron2--val_loss=1037.6234-epoch=0.ckpt" as top 3
[NeMo W 2022-05-04 11:07:19 nemo_logging:349] /root/anaconda3/lib/python3.8/site-packages/pytorch_lightning/trainer/callback_hook.py:102: LightningDeprecationWarning: The signature of `Callback.on_train_epoch_end` has changed in v1.3. `outputs` parameter has been removed. Support for the old signature will be removed in v1.5
warning_cache.deprecation(
Epoch 1: 50%|██████▌ | 1/2 [00:02<00:01, 1.48s/it, loss=73.7, v_num=7-07]
Validating: 0it [00:00, ?it/s][A
Validating: 0%| | 0/1 [00:00<?, ?it/s][A[NeMo W 2022-05-04 11:07:29 tacotron2:341] Reached max decoder steps 5000.
Epoch 1: 100%|█████████████| 2/2 [00:10<00:00, 3.65s/it, loss=73.7, v_num=7-07][A
[AEpoch 4, global step 4: val_loss reached 10.16900 (best 9.90571), saving model to "/root/nemo_experiments/Tacotron2/2022-05-04_11-07-07/checkpoints/Tacotron2--val_loss=10.1690-epoch=4.ckpt" as top 3
Epoch 5: 50%|██████▌ | 1/2 [00:03<00:01, 1.70s/it, loss=36.9, v_num=7-07]
Validating: 0it [00:00, ?it/s][A
Validating: 0%| | 0/1 [00:00<?, ?it/s][A[NeMo W 2022-05-04 11:08:23 tacotron2:341] Reached max decoder steps 5000.
Epoch 5: 100%|█████████████| 2/2 [00:11<00:00, 3.96s/it, loss=36.9, v_num=7-07][A
...
[AEpoch 2249, global step 2249: val_loss was not in top 3
Epoch 2250: 50%|████▌ | 1/2 [00:03<00:01, 1.75s/it, loss=0.249, v_num=7-07]
Validating: 0it [00:00, ?it/s][A
Validating: 0%| | 0/1 [00:00<?, ?it/s][A
2.2在指定路径中加载训练后的Tacotron2模型用来生成文字对应的频谱图
model = Tacotron2Model.restore_from("Tacotron2a.nemo")
[NeMo I 2023-02-28 19:43:29 features:267] PADDING: 16
[NeMo I 2023-02-28 19:43:32 save_restore_connector:243] Model Tacotron2Model was successfully restored from /root/Speechhome/Tacotron2a.nemo.
2.3加载Hifigan声码器模型用于将频谱图转化成语音文件
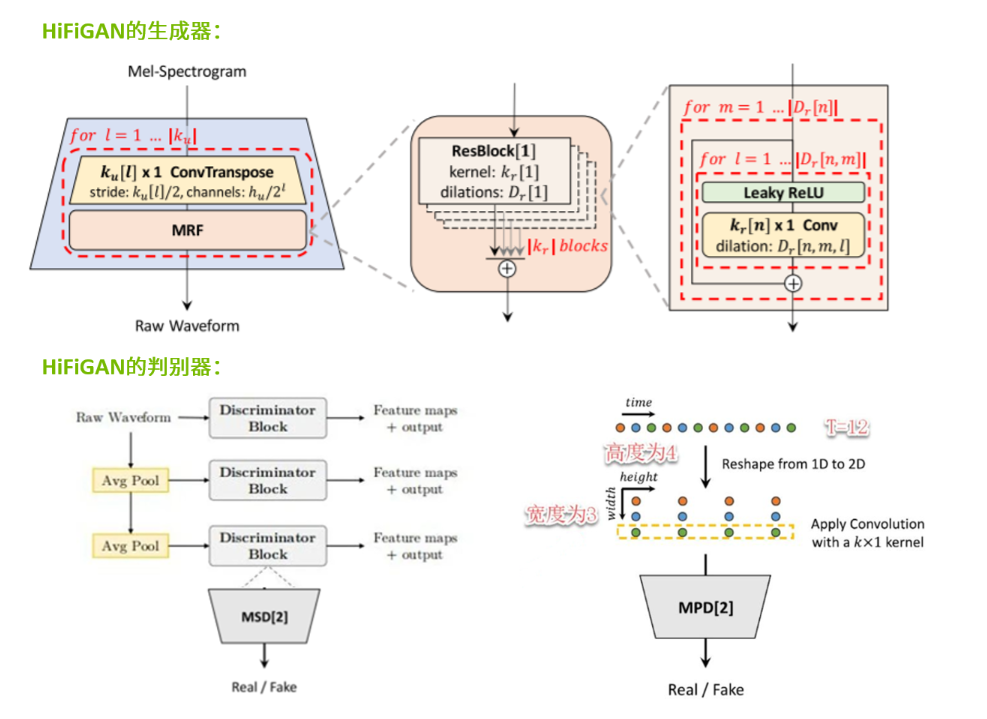
from nemo.collections.tts.models import HifiGanModel
vocoder = HifiGanModel.from_pretrained(model_name="tts_hifigan")
[NeMo I 2023-02-28 19:48:11 cloud:56] Found existing object /root/.cache/torch/NeMo/NeMo_1.15.0/tts_hifigan/e6da322f0f7e7dcf3f1900a9229a7e69/tts_hifigan.nemo.
[NeMo I 2023-02-28 19:48:11 cloud:62] Re-using file from: /root/.cache/torch/NeMo/NeMo_1.15.0/tts_hifigan/e6da322f0f7e7dcf3f1900a9229a7e69/tts_hifigan.nemo
[NeMo I 2023-02-28 19:48:11 common:913] Instantiating model from pre-trained checkpoint
[NeMo I 2023-02-28 19:48:13 features:267] PADDING: 0
[NeMo I 2023-02-28 19:48:13 features:267] PADDING: 0
[NeMo I 2023-02-28 19:48:15 save_restore_connector:243] Model HifiGanModel was successfully restored from /root/.cache/torch/NeMo/NeMo_1.15.0/tts_hifigan/e6da322f0f7e7dcf3f1900a9229a7e69/tts_hifigan.nemo.
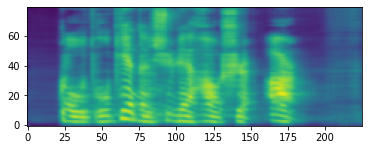
2.4 输入需要进行语音合成的文字生成对应的频谱图
text = "狗图片的序列号是2"
tokens = model.parse(text)
spectrogram = model.generate_spectrogram(tokens = tokens)
%matplotlib inline
imshow(spectrogram.cpu().detach().numpy()[0,...], origin="lower")
plt.show()
[NeMo W 2023-02-28 19:49:18 tacotron2:145] parse() is meant to be called in eval mode.
2.5 通过声码器将频谱图转化为语音音频并播放
audio = vocoder.convert_spectrogram_to_audio(spec=spectrogram)
import IPython
IPython.display.Audio(audio.to('cpu').detach().numpy(), rate=22050)

















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









