







文章目录
一、关于 LLaVA
LLaVA: Large Language and Vision Assistant
- 主页:https://llava-vl.github.io
- github : https://github.com/haotian-liu/LLaVA
- arxiv | arxiv(LLaVA-1.5) 代码 | 演示 | 数据集 | 模型
威斯康星大学麦迪逊分校 + 微软研究院 + 哥伦比亚大学
🔥[新!] LLaVA-1.5在11个基准上实现了SoTA,只需对原始LLaVA进行简单修改,利用所有公共数据,在单个8-A100节点上约1天内完成训练,并超越了使用十亿级数据的方法。
LLaVA代表了一种新颖的端到端训练的大型多模态模型,它结合了视觉编码器和Vicuna 用于通用视觉和语言理解, 实现令人印象深刻的聊天功能,模仿多模态GPT-4的精神,并在科学QA上设置新的最先进的准确性。
摘要
使用机器生成的 instruction-following 数据的指令调整大型语言模型(LLM)提高了语言领域新任务的 zero-shot 能力,但这一想法在多模态领域的探索较少。
- 多模态指令数据。我们首次尝试使用纯语言的GPT-4来生成多模态语言图像instruction-following数据。
- LLaVA模型。我们介绍了LLaVA(大型语言和视觉助手),这是一种端到端训练的大型多模态模型,连接视觉编码器和LLM以实现通用视觉和语言理解。
- 性能。我们早期的实验表明,LLaVA表现出令人印象深刻的多模型聊天能力,有时在看不见的图像/指令上表现出多模态GPT-4的行为,并在合成的多模态instruction-following数据集上与GPT-4相比产生85.1%的相对分数。
当在科学质量保证上进行微调时,LLaVA和GPT-4的协同作用达到了92.53%的最新准确率。 - 开源。我们公开GPT-4生成的可视化指令调整数据、我们的模型和代码库。
二、Multimodal Instrucion-Following Data
基于COCO数据集,我们与纯语言GPT-4交互,并总共收集158K独特的语言-图像instruction-following样本,分别包括对话中的58K、详细描述中的23K和复杂推理中的77k。请查看LLaVA-Instruct-150K [HuggingFace数据集].
| 数据文件名 | 文件大小 | 样本大小 |
|---|---|---|
| conversation_58k. json | 126 MB | 58K |
| detail_23k.json | 20.5 MB | 23K |
| complex_reasoning_77k.json | 79.6 MB | 77K |
对于每个子集,我们可视化指令和响应的根名词-动词对。对于每个图表,请单击交互式页面的链接以查看频率高于给定数字的名词-动词对。
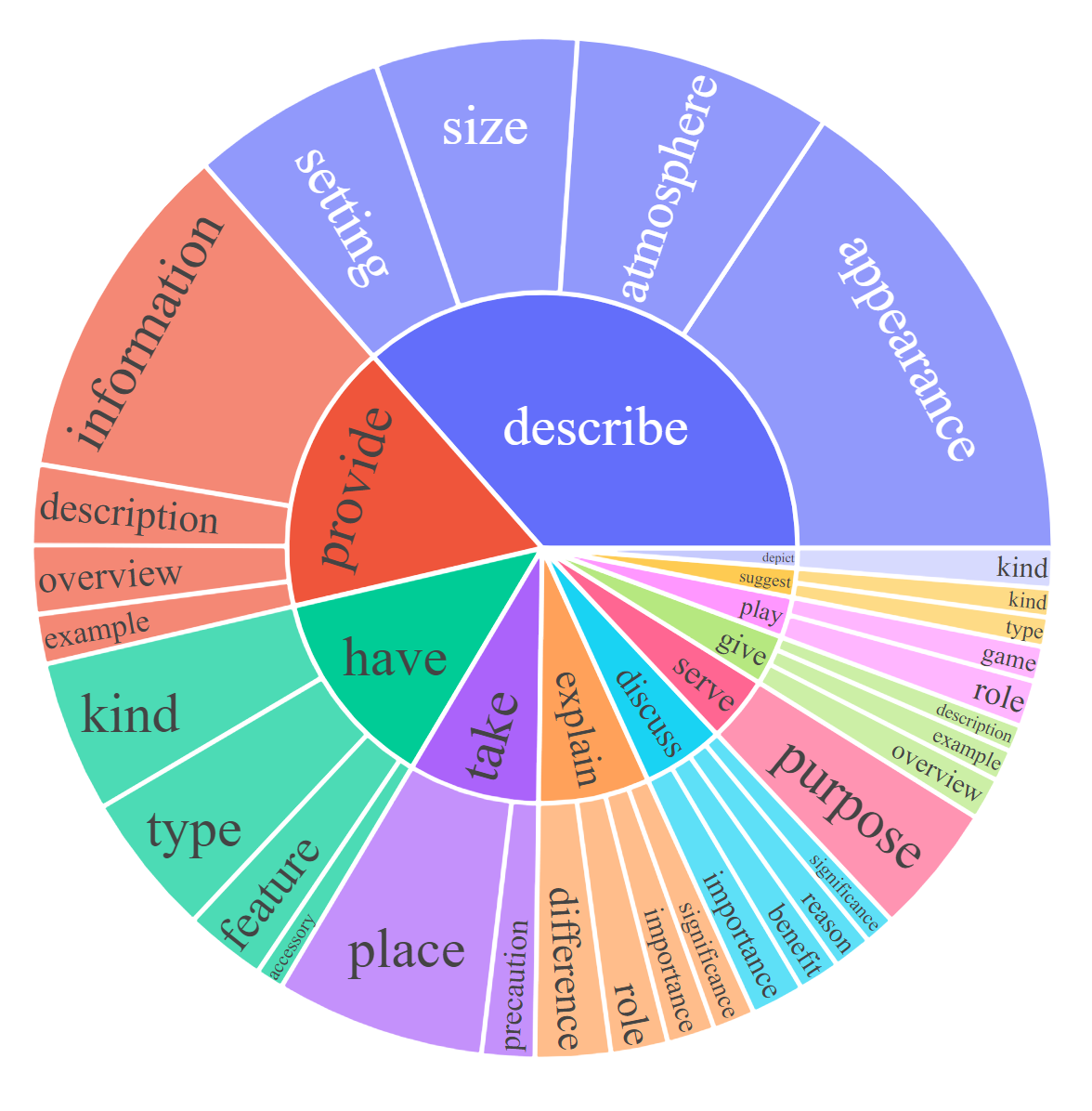 | 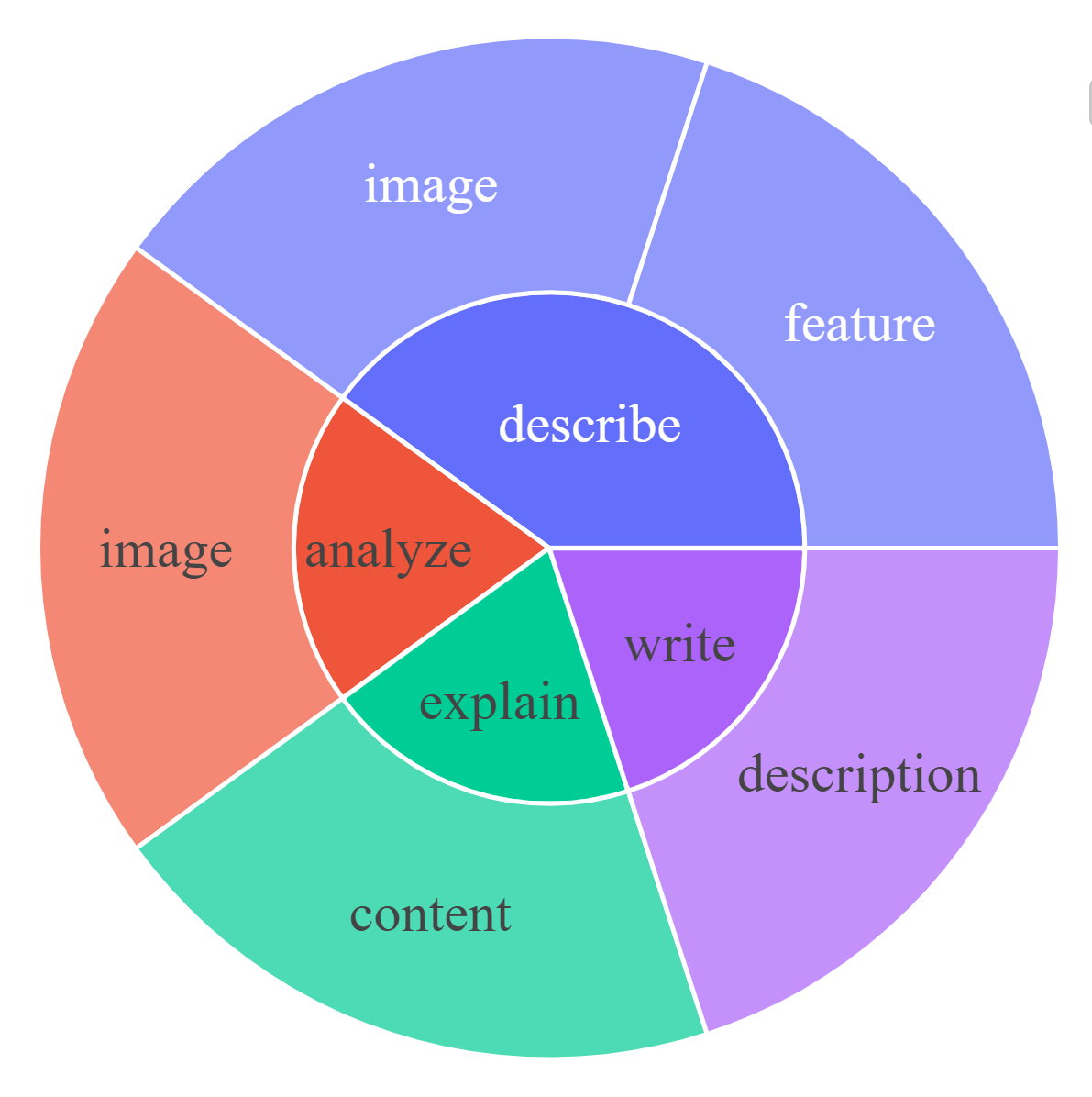 | 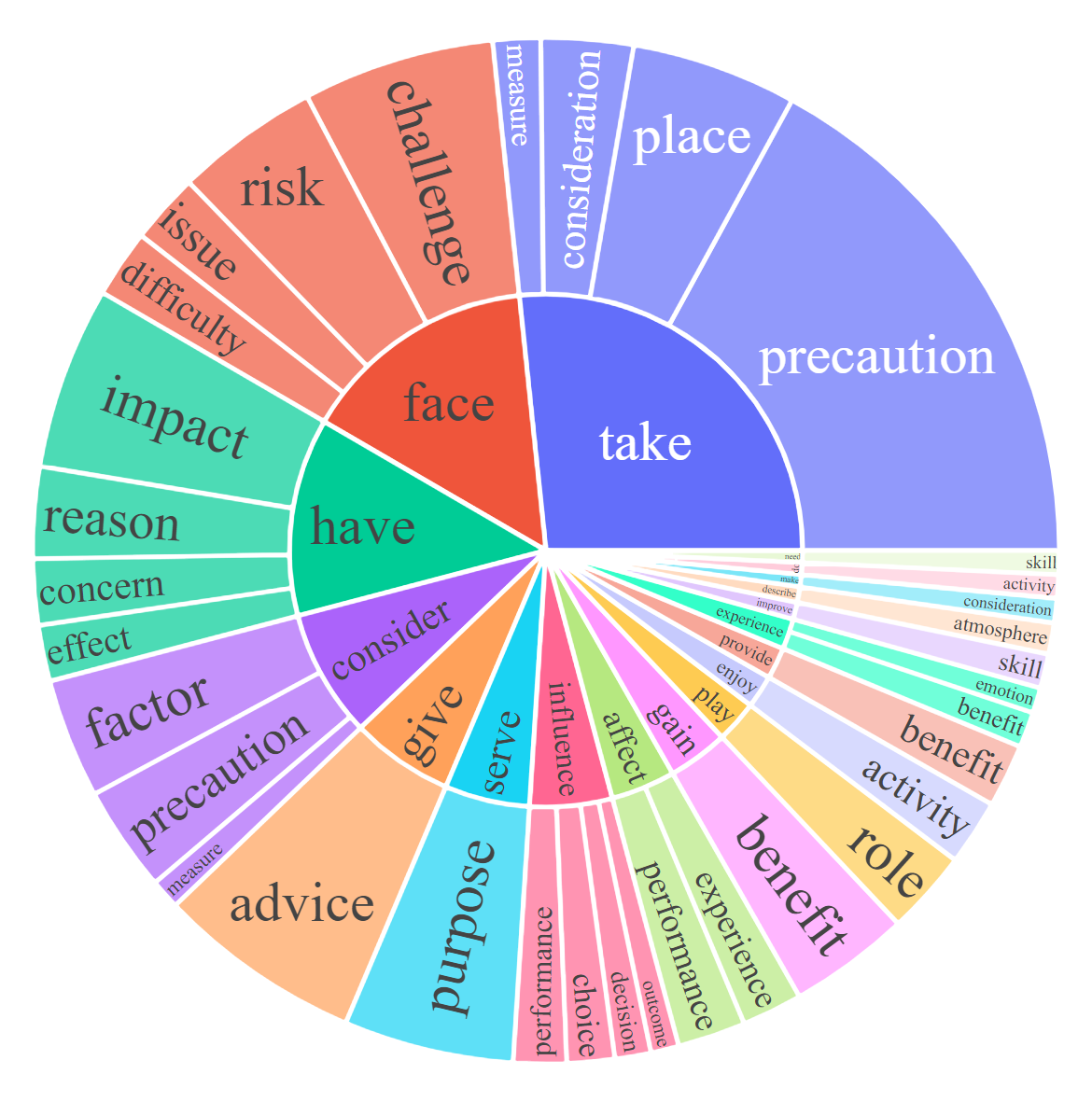 |
|---|---|---|
| 说明:对话[0,20,50] | 说明:详细说明[0] | 说明:复杂推理[0,20,50] |
 |  | 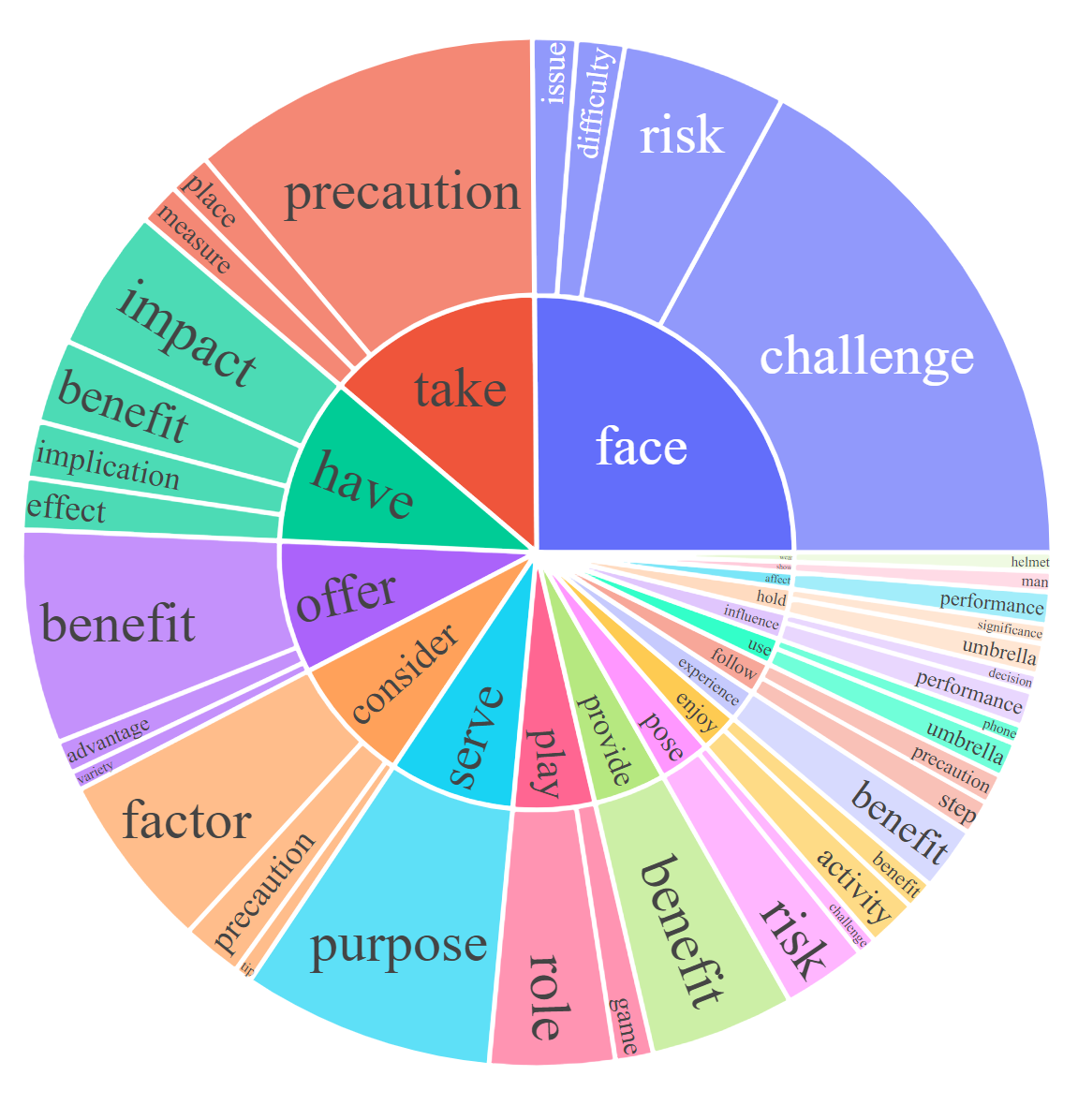 |
| 回应:对话[0,20,50] | 响应:详细说明[0,20,50] | 回应:复杂推理[0,20,50] |
三、LLaVA:大型语言和视觉助手
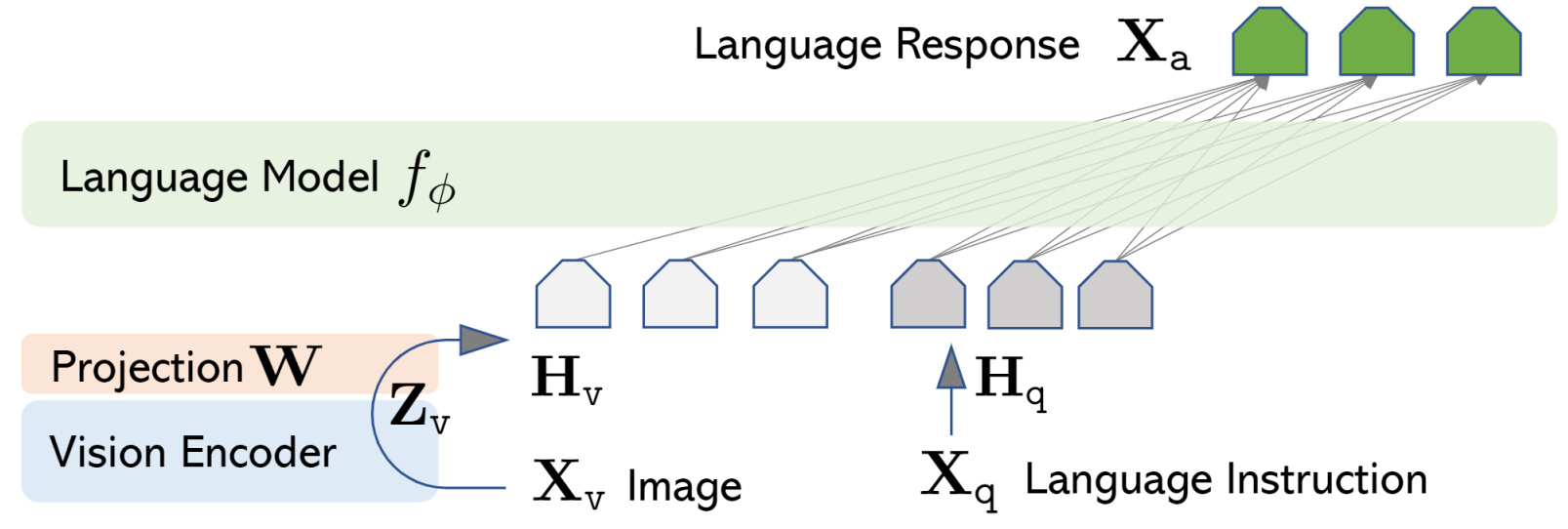
LLaVa使用一个简单的投影矩阵将预训练的 CLIP ViT-L/14 视觉编码器和大型语言模型 Vicuna 连接起来。我们考虑一个两阶段的指令调优过程:
- 第1阶段:特征对齐的预训练。 仅根据CC3M的子集更新投影矩阵。
- 第2阶段:微调端到端。 投影矩阵和LLM都针对两种不同的用途进行了更新:
- 视觉聊天:LLaVA对我们生成的多模态instruction-following数据进行了微调,适用于面向日常用户的应用程序。
- 科学QA:LLaVA在科学领域的多模态推理数据集上进行了微调。
可以查看 [Model Zoo]。
四、性能
1、 视觉聊天:构建多模态GPT-4级聊天机器人
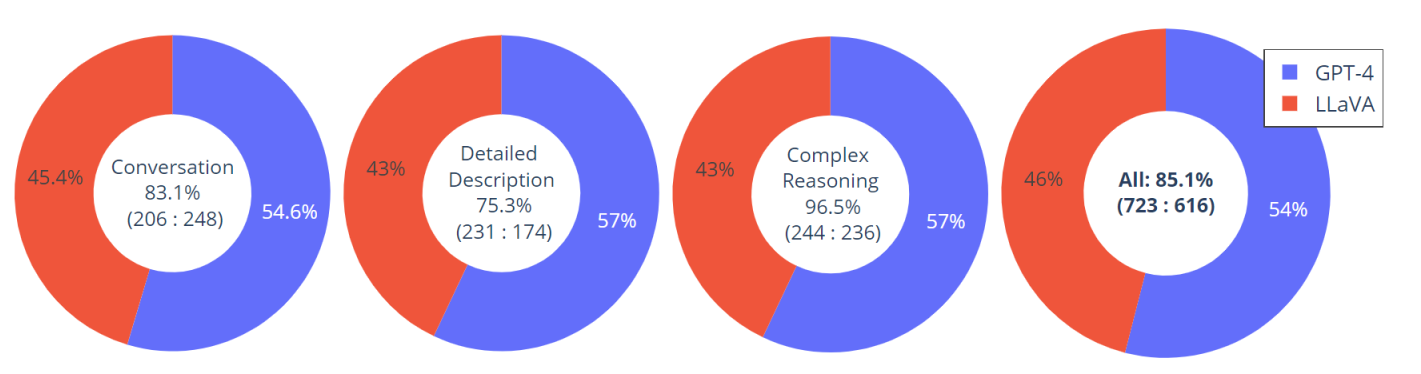
构建了一个包含30个未见图像的评估数据集:每个图像都与三种类型的指令相关联:对话、详细描述和复杂推理。这导致了90个新的语言-图像指令,我们在这些指令上测试LLaVA和GPT-4,并使用GPT-4对它们的响应进行评分,从1分到10分。报告了每种类型的总和分数和相对分数。总体而言,LLaVA与GPT-4相比达到了85.1%的相对分数,表明所提出的自我指导方法在多模态环境中的有效性
2、科学QA:LLaVA与GPT-4协同作用的新SoTA
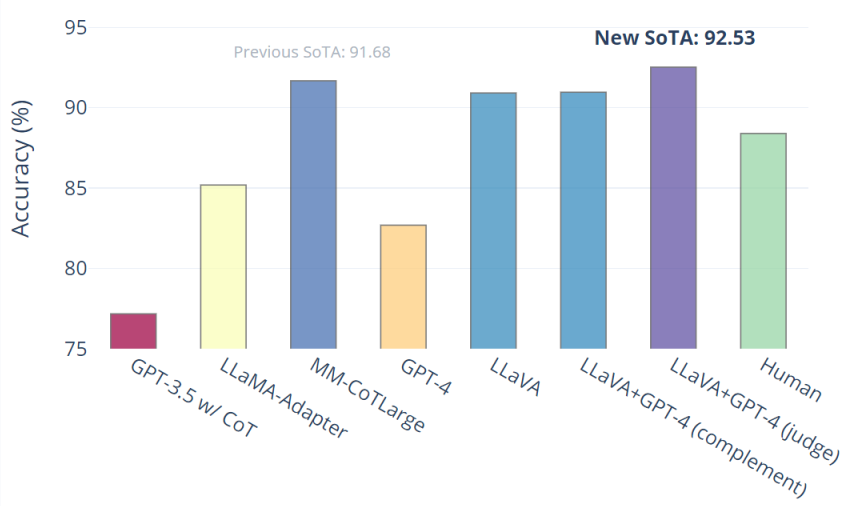
仅LLaVA就达到90.92%。我们使用纯文本GPT-4作为判断,根据自己之前的答案和LLaVA答案预测最终答案。这种GPT-4作为判断方案产生了新的SOTA 92.53%。
五、以下视觉教学示例
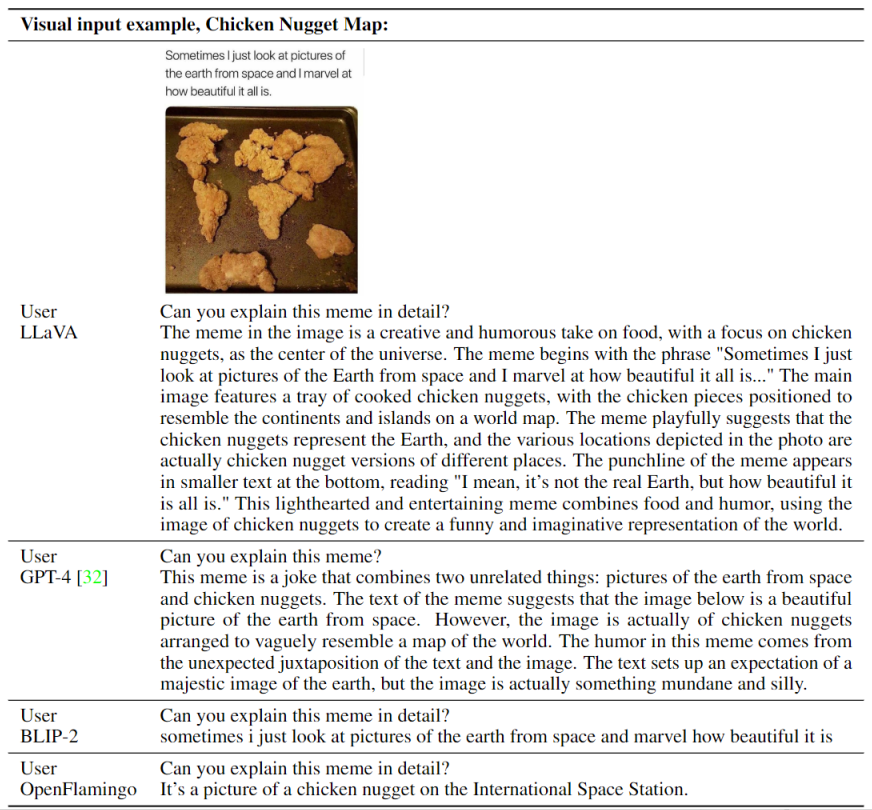
1、基于OpenAI GPT-4技术报告中两个例子的可视化推理

***
2、光学字符识别(OCR)

3、对话示例
用户 :

用户:
Do you know who drew this painting?
LLaVA
The painting depicts a woman, commonly believed to be Mona Lisa, the famous artwork by Leonardo da Vinci. It is a portrait painting that showcases the woman's enigmatic smile and has become one of the most famous and iconic art pieces in the world. The original work is displayed in the Louvre Museum in Paris, and it is known for its intricate details, use of oil paint, and the artist's innovative techniques that contributed to its enduring appeal and mystery.
六、安装
如果您没有使用Linux,请不要继续,请参阅macOS和Windows说明。
1、克隆此存储库并导航到LLaVA文件夹
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
2、安装包
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
3、为训练案例安装附加包
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
升级到最新的代码库
git pull
pip install -e .
# if you see some import errors when you upgrade,
# please try running the command below (without #)
# pip install flash-attn --no-build-isolation --no-cache-dir
使用HuggingFace快速入门
from llava.model.builder import load_pretrained_model
from llava.mm_utils import get_model_name_from_path
from llava.eval.run_llava import eval_model
model_path = "liuhaotian/llava-v1.5-7b"
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path=model_path,
model_base=None,
model_name=get_model_name_from_path(model_path)
)
查看llava/model/builder.py 中的 load_prained_model函数的详细信息。
您还可以使用llava/eval/run_llava.py中的eval_model函数轻松获取输出。通过这样做,您可以在下载此存储库后直接在Colab上使用此代码。
model_path = "liuhaotian/llava-v1.5-7b"
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
args = type('Args', (), {
"model_path": model_path,
"model_base": None,
"model_name": get_model_name_from_path(model_path),
"query": prompt,
"conv_mode": None,
"image_file": image_file,
"sep": ",",
"temperature": 0,
"top_p": None,
"num_beams": 1,
"max_new_tokens": 512
})()
eval_model(args)
LLaVA 权重
请查看我们的 Model Zoo ,了解所有公共LLaVA检查站,以及如何使用重量的说明。
七、Demo
Gradio Web UI
要在本地启动Gradio demo,请逐个运行以下命令。如果您计划启动多个模型工作者来比较不同的检查点,您只需要启动控制器和Web服务器ONCE。
启动控制器
python -m llava.serve.controller --host 0.0.0.0 --port 10000
启动 Gradio Web服务器
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
您刚刚启动了Gradio Web界面。现在,您可以打开打印在屏幕上的URL的Web界面。您可能会注意到模型列表中没有模型。别担心,因为我们还没有启动任何模型工人。当您启动模型工人时,它会自动更新。
启动 SGLang worker
这是为高吞吐量的LLaVA模型提供服务的推荐方法,您需要先安装SGLang。请注意,目前SGLang-LLaVA还不支持4-bit量化,如果您的GPU VRAM有限,请查看带有量化的模型工作者。
pip install "sglang[all]"
您将首先启动一个SGLang后端工作程序,它将在GPU上执行模型。记住您设置的--port,稍后您将使用它。
# Single GPU
CUDA_VISIBLE_DEVICES=0 python3 -m sglang.launch_server --model-path liuhaotian/llava-v1.5-7b --tokenizer-path llava-hf/llava-1.5-7b-hf --port 30000
# Multiple GPUs with tensor parallel
CUDA_VISIBLE_DEVICES=0,1 python3 -m sglang.launch_server --model-path liuhaotian/llava-v1.5-13b --tokenizer-path llava-hf/llava-1.5-13b-hf --port 30000 --tp 2
Tokenizers(临时):llava-hf/llava-1.5-7b-hf,llava-hf/llava-1.5-13b-hf,liuhaotian/llava-v1.6-34b-tokenizer。
然后,您将启动一个LLaVA-SGLang工作人员,该工作人员将在LLaVA控制器和SGLang后端之间进行通信以路由请求。将--sgl-endpoint设置为http://127.0.0.1:port,其中port是您刚刚设置的(默认值:30000)。
python -m llava.serve.sglang_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --sgl-endpoint http://127.0.0.1:30000
加载 model worker
这是在GPU上执行推理的实际 worker 。每个工作人员负责--model-path指定的单个模型。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b
等到该过程完成加载模型,您会看到Uvicorn running on ...。
现在,刷新您的Gradio Web UI,您将在模型列表中看到您刚刚启动的模型。
您可以启动任意数量的工作人员,并在同一Gradio界面中比较不同的模型检查点。
请保持--controller相同,并为每个工作人员修改--port和--worker的不同端口号。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port <different from 40000, say 40001> --worker http://localhost:<change accordingly, i.e. 40001> --model-path <ckpt2>
如果您使用的是带有M1或M2芯片的Apple设备,则可以使用--device来指定mp设备:--device mps。
启动模型 worker(多个GPU,当GPU VRAM<=24GB时)
如果您的GPU的VRAM小于24GB(例如,RTX 3090、RTX 4090等),您可以尝试使用多个GPU运行它。
如果您有多个GPU,我们最新的代码库将自动尝试使用多个GPU。
您可以指定CUDA_VISIBLE_DEVICES使用哪些GPU。下面是使用前两个GPU运行的示例。
CUDA_VISIBLE_DEVICES=0,1 python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b
启动模型 worker(4位、8位推理、量化)
您可以使用量化位(4位、8位)启动模型工作器,这允许您在减少GPU内存占用的情况下运行推理,潜在地允许您在只有12GB VRAM的GPU上运行。
请注意,量化位的推理可能不如全精度模型准确。
只需将--load-4bit或--load-8bit附加到您正在执行的 model worker 命令中。下面是使用4位量化运行的示例。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b --load-4bit
启动模型 worker(LoRA权重,未合并)
您可以启动带有LoRA权重的模型工作器,而不将它们与基本检查点合并,以节省磁盘空间。
会有额外的加载时间,而推理速度与合并的检查点相同。
未合并的LoRA检查点在模型名称中没有lora-merge,并且通常比合并的检查点小得多(小于1GB)(7B为13G,13B为25G)。
要加载未合并的LoRA权重,您只需传递一个附加参数--model-base,它是用于训练LoRA权重的基本LLM。您可以在Model Zoo中检查每个LoRA权重的基本LLM。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1-0719-336px-lora-vicuna-13b-v1.3 --model-base lmsys/vicuna-13b-v1.3
CLI 推理
使用LLaVA聊天图像,无需Gradio界面。它还支持多个GPU,4位和8位量化推理。
通过4位量化,对于我们的LLaVA-1.5-7B,它在单个GPU上使用不到8GB的VRAM。
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-7b \
--image-file "https://llava-vl.github.io/static/images/view.jpg" \
--load-4bit
八、训练
下面是LLaVA v1.5的最新训练配置。对于遗留模型,请暂时参考此版本的自述文件。我们稍后会在单独的文档中添加它们。
LLaVA训练包括两个阶段:
(1)特征对齐阶段:使用LAION-CC-SBU数据集的558K子集将冻结的预训练视觉编码器连接到冻结的LLM;
(2)视觉指令调整阶段:使用150KGPT生成的多模态instruction-following数据,加上来自学术任务的大约515KVQA数据,来教模型遵循多模态指令。
LLaVA在8个具有80GB内存的A100 GPU上训练。要在更少的GPU上训练,您可以相应地减少per_device_train_batch_size并增加gradient_accumulation_steps。
始终保持全局批量大小相同:per_device_train_batch_sizexgradient_accumulation_stepsxnum_gpus。
超参数
我们在微调中使用与Vicuna相似的超参数集。下面提供了用于预训练和微调的两个超参数。
1、预训练
| 超参数 | 全局批量大小 | 学习率 | Epochs | 最大长度 | 权重衰减 |
|---|---|---|---|---|---|
| LLaVA-v1.5-13B | 256 | 1e-3 | 1 | 2048 | 0 |
2、微调
| 超参数 | 全局批量大小 | 学习率 | Epochs | 最大长度 | 权重衰减 |
|---|---|---|---|---|---|
| LLaVA-v1.5-13B | 128 | 2e-5 | 1 | 2048 | 0 |
下载Vicuna检查点(自动)
我们的基本模型Vicuna v1.5是一个指令调整的聊天机器人,当您运行我们提供的训练脚本时,它将自动下载。不需要任何操作。
预训练(特征对齐)
请下载LAION-CC-SBU数据集的558K子集,其中包含我们在此处论文中使用的BLIP字幕。
由于分辨率提高到336像素,在8x A100(80G)上LLaVA-v1.513B预训练大约需要5.5小时。LLaVA-v1.57B大约需要3.5小时。
使用DeepSpeed ZeRO-2的训练脚本:pretrain.sh。
--mm_projector_type mlp2x_gelu–双层MLP视觉语言连接器。--vision_tower openai/clip-vit-large-patch14-336: CLIP ViT-L/14 336px。
视觉指令调整
1、准备数据
请下载最终混合物的注释我们的指令调整数据llava_v1_5_mix665k. json,并从构成数据集中下载图像:
下载完后,将 ./playground/data 数据整理如下
├── coco
│ └── train2017
├── gqa
│ └── images
├── ocr_vqa
│ └── images
├── textvqa
│ └── train_images
└── vg
├── VG_100K
└── VG_100K_2
2、开始训练!
您可以在Model Zoo下载我们的预训练投影仪。
不建议使用遗留投影仪,因为它们可能使用不同版本的代码库进行训练,如果任何选项关闭,模型将无法按我们预期的那样运行/训练。
由于分辨率提高到336像素,在8x A100(80G)上LLaVA-v1.5-13B的视觉指令调整大约需要20小时。在8x A100(40G)上,LLaVA-v1.5-7B大约需要10小时。
使用DeepSpeed ZeRO-3的训练脚本:finetune.sh。
如果您没有足够的GPU内存:
- 使用LoRA:
finetune_lora.sh。我们能够适应8-A100-40G/8-A6000的13B训练,以及8-RTX3090的7B训练。确保per_device_train_batch_size*gradient_accumulation_steps与提供的脚本相同,以获得最佳重现性。 - 将
zero3.json替换为zero3_offload.json.json,这会将一些参数卸载到CPU RAM。这会减慢训练速度。
如果您有兴趣根据自己的任务/数据微调LLaVA模型,请查看Finetune_Custom_Data.md。
需要注意的新选项:
--mm_projector_type mlp2x_gelu–双层MLP视觉语言连接器。--vision_tower openai/clip-vit-large-patch14-336: CLIP ViT-L/14 336px。--image_aspect_ratio pad:这将非正方形图像垫成正方形,而不是裁剪它们;它稍微减少了幻觉。--group_by_modality_length True:这应该仅在您的指令调整数据集同时包含语言(例如ShareGPT)和多模态(例如LLaVA-Instruct)时使用。它使训练采样器在训练期间仅对单一模态(图像或语言)进行采样,我们观察到这可以将训练速度提高约25%,并且不会影响最终结果。
九、评价
在LLaVA-1.5中,我们在一组不同的12个基准上评估模型。为了确保可重复性,我们使用贪婪解码来评估模型。我们不使用波束搜索进行评估,以使推理过程与实时输出的聊天演示一致。
GPT辅助评估
我们的GPT辅助多模态建模评估管道旨在全面了解视觉语言模型的功能。有关详细信息,请参阅我们的论文。
1、生成LLaVA响应
python model_vqa.py \
--model-path ./checkpoints/LLaVA-13B-v0 \
--question-file \
playground/data/coco2014_val_qa_eval/qa90_questions.jsonl \
--image-folder \
/path/to/coco2014_val \
--answers-file \
/path/to/answer-file-our.jsonl
2、评估生成的响应。在我们的例子中,answer-file-ref.jsonl是由纯文本GPT-4(0314)生成的响应,提供了上下文标题/框。
OPENAI_API_KEY="sk-***********************************" python llava/eval/eval_gpt_review_visual.py \
--question playground/data/coco2014_val_qa_eval/qa90_questions.jsonl \
--context llava/eval/table/caps_boxes_coco2014_val_80.jsonl \
--answer-list \
/path/to/answer-file-ref.jsonl \
/path/to/answer-file-our.jsonl \
--rule llava/eval/table/rule.json \
--output /path/to/review.json
3、总结评估结果
python summarize_gpt_review.py
其它
Citation
如果您发现LLaVA对您的研究和应用有用,请使用此BibTeX引用:
@misc{liu2024llavanext,
title={LLaVA-NeXT: Improved reasoning, OCR, and world knowledge},
url={https://llava-vl.github.io/blog/2024-01-30-llava-next/},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae},
month={January},
year={2024}
}
@misc{liu2023improvedllava,
title={Improved Baselines with Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae},
publisher={arXiv:2310.03744},
year={2023},
}
@misc{liu2023llava,
title={Visual Instruction Tuning},
author={Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae},
publisher={NeurIPS},
year={2023},
}
致谢
- Vicuna:我们构建的代码库,以及我们的基本模型Vicuna13B具有惊人的语言能力!
相关项目
对于未来的项目想法,请查看:
- 似乎:一次分割所有地方的一切
- Grounded-Segment-Anything检测,分段,和生成任何东西通过结婚接地恐龙和Segment-任何东西。
2024-07-16(二)



















 2844
2844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











