









文章目录
论文: 《Visual Instruction Tuning》
github: https://github.com/haotian-liu/LLaVA/tree/main
摘要
使用生成的instruction微调LLM以及被证明可以改进zero-shot能力,但是该方案未在多模态领域验证。作者尝试使用GPT-4生成多模态语言-图像数据。通过在这些生成数据上微调,作者引入LLaVA,一个大多模态模型,将用于通用视觉和语言理解的视觉编码器与LLM结合。作者构建两个评估基准,LLaVA展示多模态聊天能力,甚至是未见过的图片/instruction,在一个多模态数据集达到85.1%的相对GPT-4得分,在Science QA数据集微调后,LLaVA与GPT-4结合达到92.53%。
引言
本文贡献如下:
- 多模态指令跟随数据。作者提出一种数据改造流程,使用ChatGPT/GPT-4将图文对转换为指令跟随的格式。
- 大多模态模型(LMM)。作者提出LMM,连接CLIP的视觉编码器与语言解码器,在生成的指令跟随数据集上进行微调,与GPT-4集成后,在Science QA数据集达到SoTA。
- 多模态指令跟随基准。
- 开源。
GPT辅助视觉指令数据生成
一种简单的数据生成方式是:
H
u
m
a
n
:
X
q
,
X
v
,
A
s
s
i
s
t
a
n
t
:
X
c
Human:X_q,X_v,Assistant:X_c
Human:Xq,Xv,Assistant:Xc
该方案虽然成本低,但是缺少多样性及推理深度。
为减缓该问题,作者使用GPT-4或ChatGPT作为老师,为了编码图像为视觉特征用于提示仅支持文本的GPT,作者使用两种类型的表征,如表14上:
1、caption从各种角度描述视觉场景;
2、Bounding box对场景中目标进行定位,每个框编码目标及其空间位置。
这将图像编码为LLM可识别序列。
作者基于COCO数据集将上述表征代替图像输入GPT-4,生成三种指令引导数据,如表14下。对话、细节描述、复杂推理。
作者总共收集158k图文指令引导数据。

视觉instruction微调
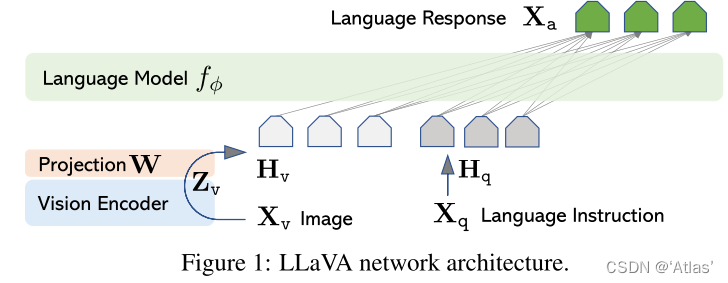
结构
如图1,对于输入图片
X
v
X_v
Xv,作者使用预训练CLIP中视觉encoder ViT-L/14编码为视觉特征
Z
v
Z_v
Zv,作者使用可训练的映射矩阵
W
W
W将
Z
v
Z_v
Zv转换为语言嵌入
t
o
k
e
n
H
v
token H_v
tokenHv,与word embedding具有相同空间维度。
训练
对于每张图片
X
v
X_v
Xv生成多轮对话数据
(
X
q
1
,
X
a
1
,
⋅
⋅
⋅
,
X
q
T
,
X
a
T
)
(X^1_q,X^1_a, · · · ,X^T_q ,X^T_a )
(Xq1,Xa1,⋅⋅⋅,XqT,XaT),对于序列长度为L,计算目标目标回答
X
a
X_a
Xa的可能性,如式3,
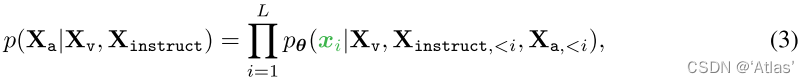
LLaVA模型训练时,使用两阶段instruction微调:
stage1:预训练用于特征对齐。
frozen 视觉编码器、LLM权重,通过训练映射矩阵
W
W
W,最大化式3中似然函数。通过这种方式将图像特征
H
v
H_v
Hv对齐到预训练LLM word embedding。
stage2:端到端微调
frozen视觉编码器,更新LLaVA中映射层级LLM。作者考虑两个特定的用例场景:
Multimodal Chatbot:基于上一节中158K图文数据进行微调。
Science QA:
实验
多模态聊天机器人

如表3,LLaVA提供更全面答复。
量化评估
作者利用GPT-4测试生成回复的质量。具体而言,LLaVA依据图像和问题预测答复,使用GPT-4预测生成结果作为理论上限,将两个响应一起送入GPT-4进行打分评估。考虑到GPT-4输入为图像描述,因此作者使用相对得分。进而创建两个基线评估模型性能。
LLaVA-Bench (COCO)
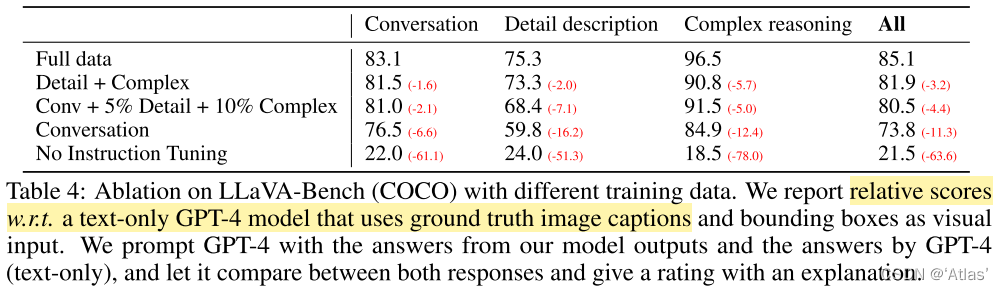
随机选取COCO中30张图,每张图生成三种问题。作者使用不同训练集,研究对模型影响,结果如表4,使用instruction tuning,可大幅提升50个点;增加少量充满细节描述及复杂问题,可提升7个点,同时也提高会话能力的表现。最终使用三种问题达到85.1%。
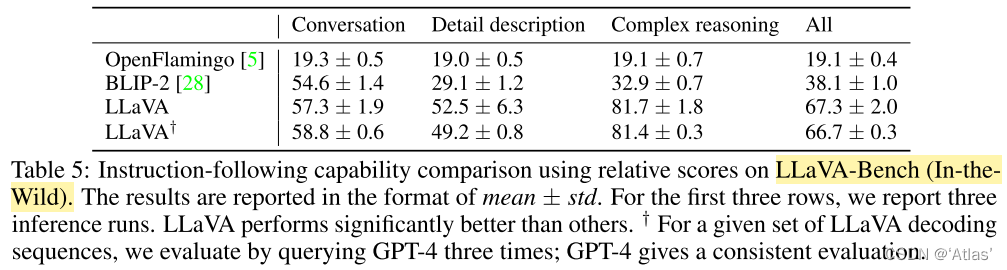
LLaVA-Bench (In-the-Wild)
为测试模型在更有挑战任务中的能力,作者选取24张内容丰富图片及60个问题,在表5中与BLIP、OpenFlamingo进行比较。LLaVA在复杂对话中达到81.7%,总分67.3%。
限制
如表6,作者提供caption与问题相关联的两个实例。图左中,为了回答餐馆名字,模型需要多语言理解能力;描述配菜,模型需要具有从互联网检索相关多模态信息能力。图右中,对于是否有草莓味酸奶回答错误,尽管冰箱中只有草莓和酸奶。

ScienceQA
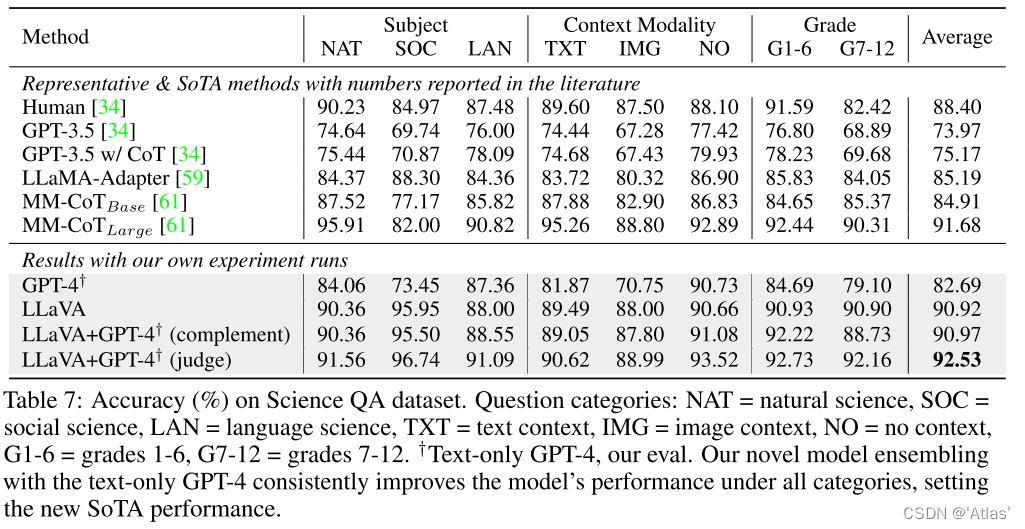
结果如表7,通过12个epoch训练后,达到90.92%准确率,使用GPT-4作为补充,达到90.97%,使用GPT-4从GPT-4与LLaVA输出中挑选最佳答案,达到92.53%。
消融实验
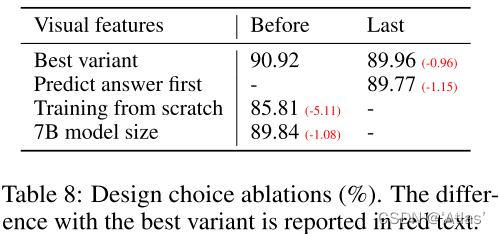
在ScienceQA数据集上消融实验如表8,
使用最后一层视觉特征比前一层特征低0.96%;
验证模型预测推理及答案的先后顺序,先预测答案,需要12个epoch达到89.77%;而先预测推理仅需6个epoch达到89.77%,因此先预测推理可加速拟合。
不使用预训练,模型仅达到85.71%;
作者训练13B模型达到90.92%,使用7B模型仅达到89.84%,说明模型尺寸影响比较大。
结论
本文证明视觉指令微调的有效性。展示一种创建语言-图像指令跟随数据集流程,基于此训练LLaVA,在ScienceQA数据集经过finetune后达到SOTA。















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









