







本文转载自:
https://mp.weixin.qq.com/s/bGUvIpcvHfYn3soD9JNMTQ
文章目录

多种模型的效果对比
一、YOLO 版本更迭
YOLO 是被工业界最广泛使用的模型之一,自 2015 年 YOLOv1 发布以来,到 2024 年已发展到第 11 个版本。上篇文章 2025年了,AI算法工程师的核心竞争力是什么?也提到了大家都在用YOLO,但是一些人却完全不懂。
本文的目标是对四个最新的 YOLO 模型(特别是 YOLOv8 到 YOLO11)进行全面且深入的架构比较,使你能够快速掌握每个模型的运行方式及其之间的区别。
- YOLOv8(2023)引入了无锚点检测方法,简化了模型架构并提升了对小目标的检测性能。其统一的多任务框架增强了其在多个计算机视觉领域的适用性。YOLOv8 支持目标检测、实例分割和图像分类任务,并新增了目标跟踪、姿态估计和旋转边界框等功能。

YOLOv8 支持多种视觉任务,成为工业界标配
- YOLOv9(2024)引入了 PGI(可编程梯度信息)框架和 GELAN(广义高效层聚合网络)架构,解决了信息瓶颈问题并提高了轻量级模型的准确性。
- YOLOv10(2024)采用了无 NMS(非极大值抑制)训练,简化了从训练到部署的流程并减少了计算需求。空间-通道解耦下采样和大核卷积的使用显著提升了性能和效率。
- YOLO11 在目标检测、特征提取、实例分割、姿态估计、跟踪和分类等多种计算机视觉任务中表现出色。它代表了实时目标检测技术的重大突破。YOLOv11 新增了 C3k2 模块、SPPF(快速空间金字塔池化)和 C2PSA(并行空间注意力卷积模块),这些组件增强了特征提取和目标检测能力。
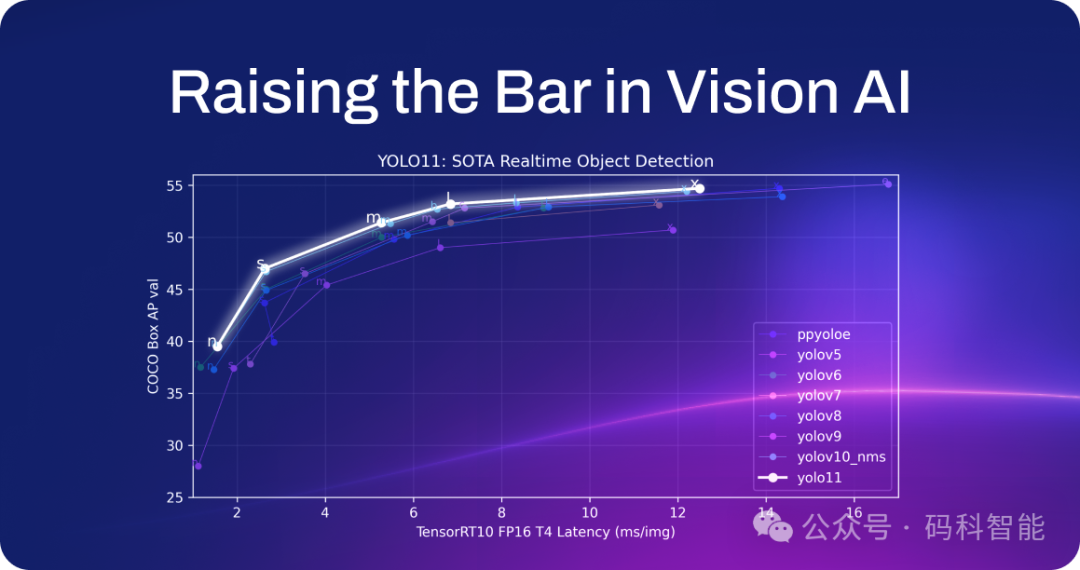
YOLO11实时目标检测速度与精度优势明显
二、变化
1、输入图像的调整
与 YOLOv4 及其前代产品相比,YOLOv8 至 YOLO11 中的输入图像将在保留图像纵横比的同时进行调整。为了保留纵横比,图像将用灰色像素填充。如果输入图像是正方形,则图像将在不填充的情况下进行调整。

Letterbox代码示例如下:
def letterbox(img: np.ndarray, new_size:ImgSize, fill_value: int=114) -> np.ndarray:
aspect_ratio = min(new_size.height / img.shape[1], new_size.width / img.shape[0])
new_size_with_ar = int(img.shape[1] * aspect_ratio), int(img.shape[0] * aspect_ratio)
resized_img = np.asarray(cv2.resize(img, new_size_with_ar))
resized_h, resized_w, _ = resized_img.shape
padded_img = np.full(new_size.get_tuple(), fill_value)
center_x = new_size.width / 2
center_y = new_size.height / 2
x_range_start = int(center_x - (resized_w / 2))
x_range_end = int(center_x + (resized_w / 2))
y_range_start = int(center_y - (resized_h / 2))
y_range_end = int(center_y + (resized_h / 2))
padded_img[y_range_start: y_range_end, x_range_start: x_range_end, :] = resized_img
return padded_img
img = cv2.imread("zidane.jpg")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_lb_mine = letterbox(np.asarray(img_rgb), ImgSize(640, 640))
plt.imshow(img_lb)
2、YOLO系列模型架构
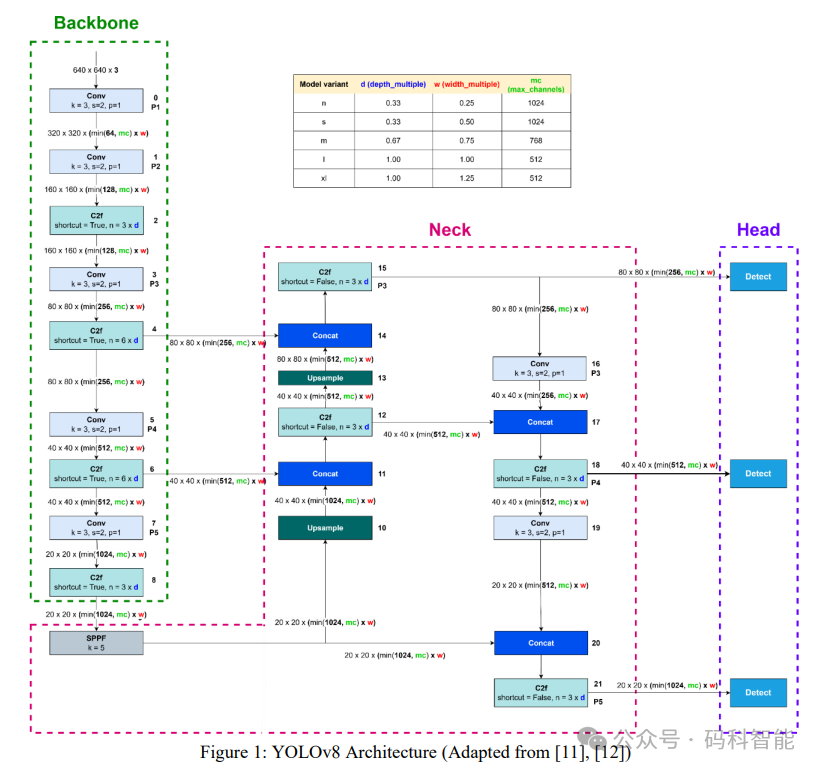
YOLOv8 的架构图示例
YOLOv8 的变体由三个参数决定:depth_multiple、width_multiple 和 max_channels。其中,depth_multiple 参数决定了 C2f 模块中瓶颈块的数量,而 width_multiple 和 max_channels 参数定义了输出通道数。检测头由两个部分组成,分别是分类头(classification head)和回归头(regression head)。分类头用于生成类别概率,而回归头用于生成边界框坐标预测。每个头由两个卷积块组成,后接一个二维卷积层。
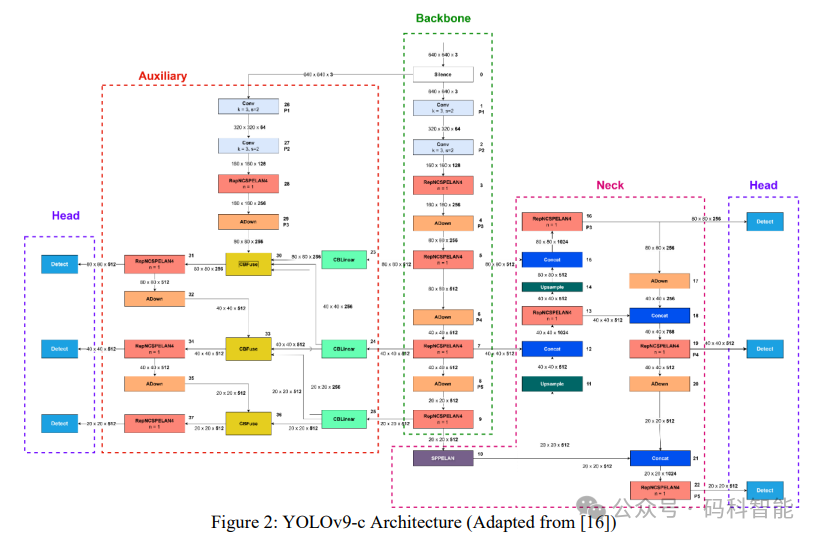
YOLOv9 的架构图
YOLOv9 新增了一个称为“辅助部分”(auxiliary)的模块。该部分用于生成可靠的梯度并更新网络参数。通过提供连接输入数据与输出目标的额外信息,解决了深度学习网络层间信息丢失的问题。辅助部分仅在训练过程中使用,在推理过程中可以移除以加速模型运行,而不会影响准确性。
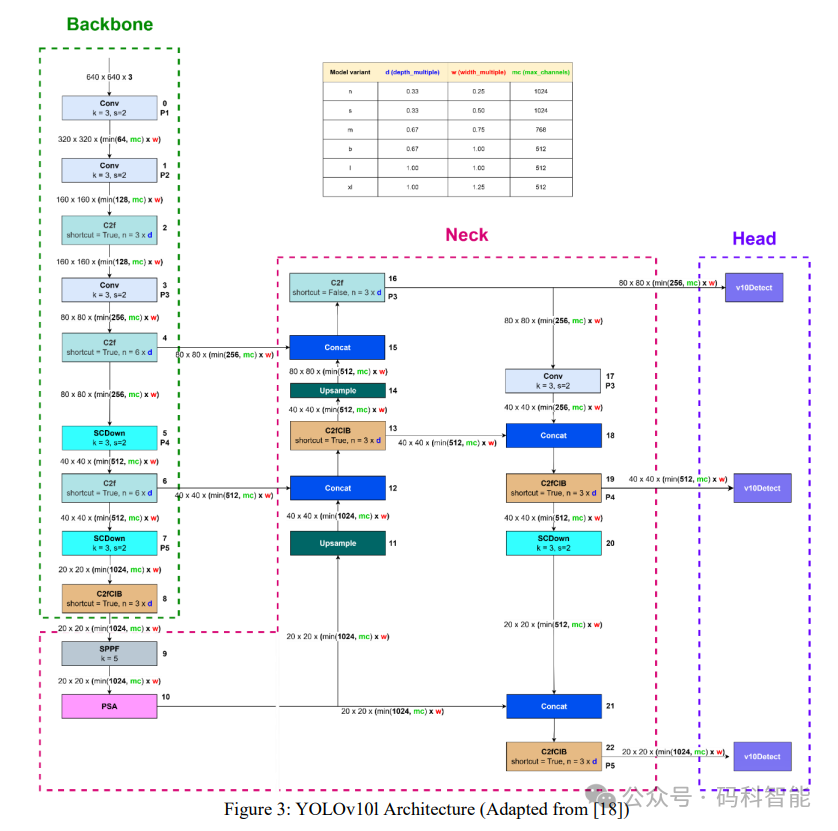
YOLOv10 的架构图
在训练过程中使用两个头:一个头实现一对多分配以提供强监督,另一个头使用一对一匹配。在推理过程中,仅使用一对一匹配的头,从而消除了对 NMS(非极大值抑制)的需求,在不牺牲性能的情况下提高了推理效率。
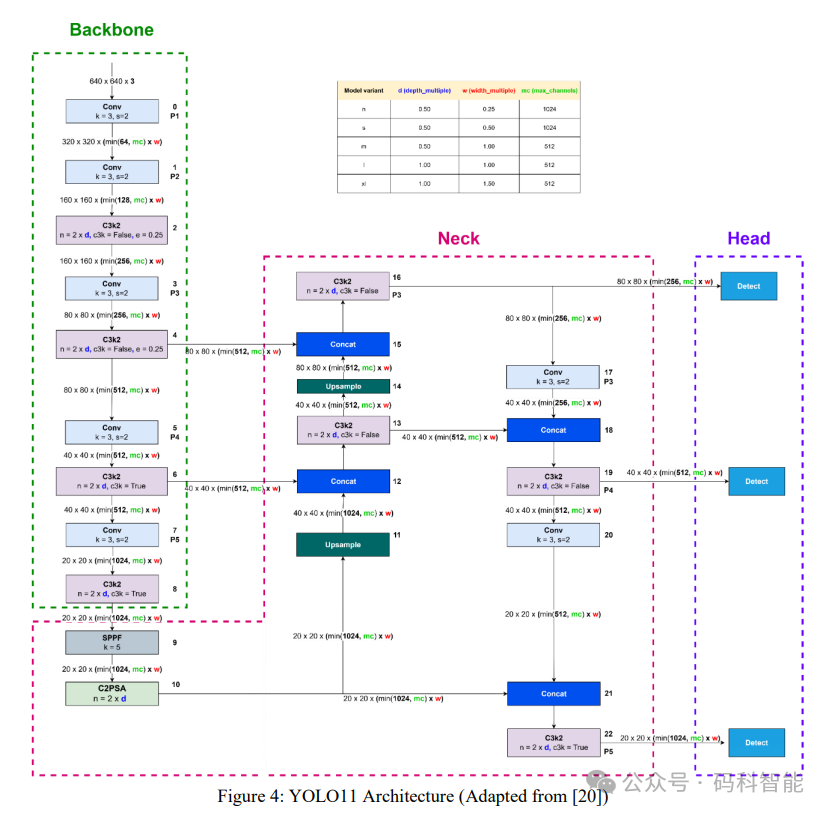
YOLO11 的架构图
引入了一个新模块,即 DWConv(深度可分离卷积模块)。depth_multiple 变量用于确定 C3k2 模块中瓶颈块或 C3k 块的数量,以及 C2PSA 模块中 PSA 块的数量。width_multiple 和 max_channels 变量则用于定义输出通道数。
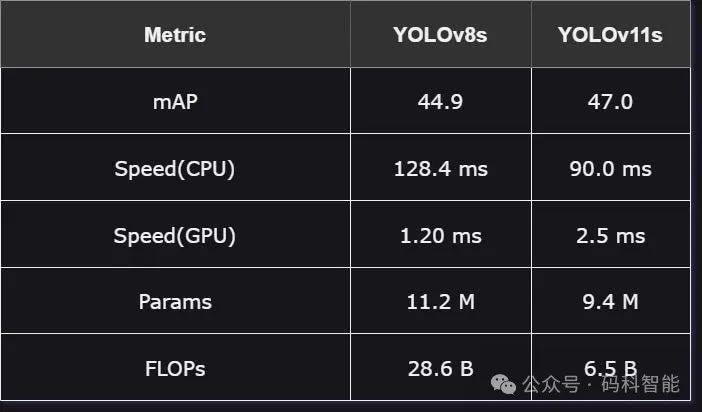
YOLO8 vs 11性能对比
关于YOLO11的具体细节和训练可以参考仅更改一行代码! 一颗彻底改变视觉AI领域的重磅炸弹:YOLOv11
关于上述YOLO几种模型的更详细的网络结构对比可以查阅论文:https://arxiv.org/pdf/2501.13400 。
2025-02-02(日)


















 5361
5361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









