






一、Yolo11源码下载地址
yolo11官方代码下载:GitHub - ultralytics/ultralytics: Ultralytics YOLO11 🚀
yolo11与训练权重选择: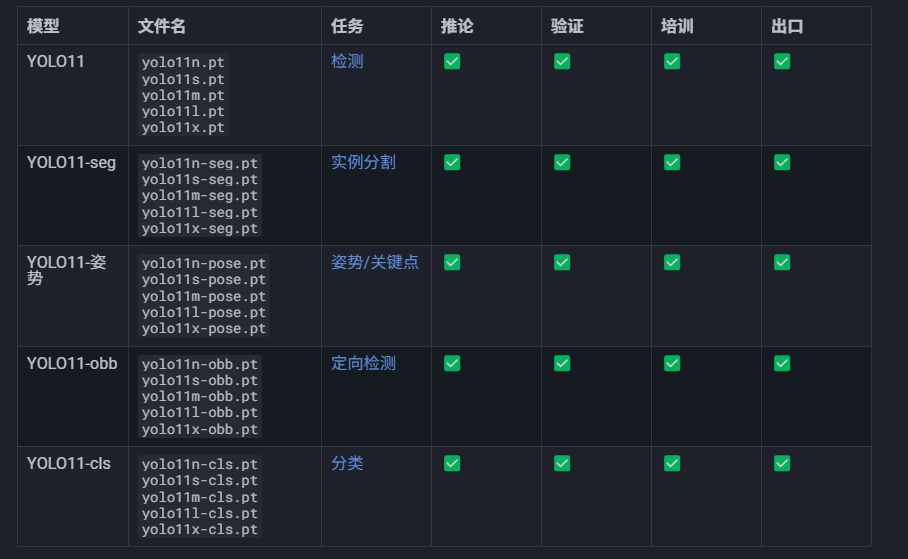
二、准备数据集及数据标注
1、数据标注(打标签)
若下载了anaconda,可直接conda命令行执行,打开labelme工具
激活进入labelme:可以框选、也可以打关键点。图片示例是框选
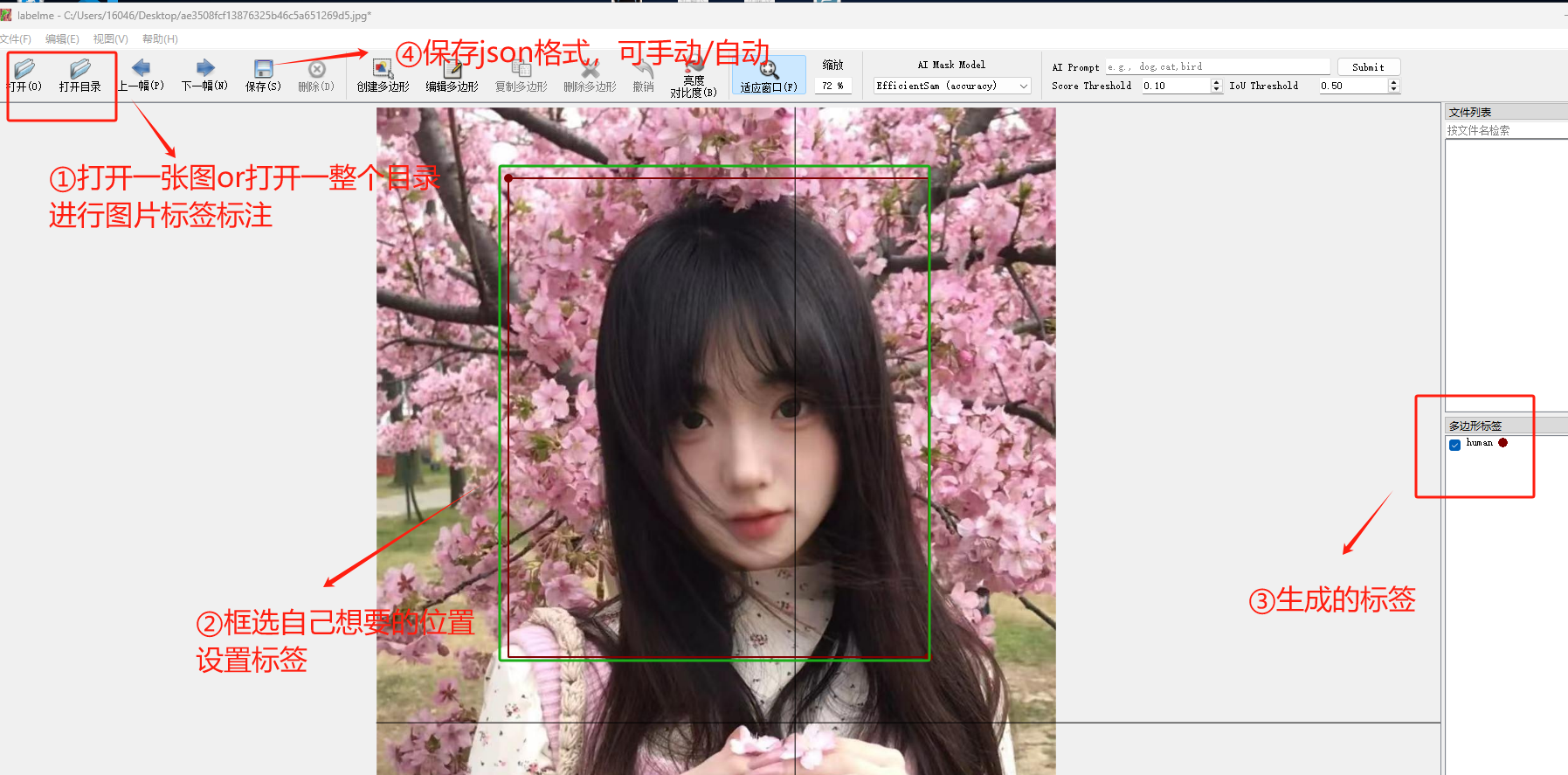
2、json_yolo格式转换
每张图对应json格式的标签保存后,进行格式转换,转换成yolo可直接用的txt格式。批量json文件转换成txt的代码如下:
import os
import json
import shutil
import numpy as np
from tqdm import tqdm
# 数据集根目录
Dataset_root = 'C:/Users/16046/Desktop/json' #替换为你生成好的json格式的文件夹
# 框的类别
bbox_class = ["human"]
# 关键点的类别,有多少类就写多少。
keypoint_class = [
'point1', 'point2', 'point3', 'point4'
]
# 转换后的 TXT 文件保存目录
save_folder = "C:/Users/16046/Desktop/mytxt" #替换为自己的路径
# 确保保存目录存在
os.makedirs(save_folder, exist_ok=True)
def process_single_json(labelme_path, save_folder):
"""
处理单个 JSON 文件,将其转换为 YOLO 格式的 TXT 文件
:param labelme_path: JSON 文件路径
:param save_folder: TXT 文件保存目录
"""
try:
with open(labelme_path, 'r', encoding='utf-8') as f:
labelme = json.load(f)
except Exception as e:
print(f"无法读取文件 {labelme_path}: {e}")
return
img_width = labelme['imageWidth'] # 图像宽度
img_height = labelme['imageHeight'] # 图像高度
# 生成 YOLO 格式的 TXT 文件路径
file_name = os.path.splitext(os.path.basename(labelme_path))[0]
yolo_txt_path = os.path.join(save_folder, file_name + '.txt')
with open(yolo_txt_path, 'w', encoding='utf-8') as f:
for each_ann in labelme['shapes']: # 遍历每个标注
if each_ann['shape_type'] == 'rectangle': # 处理边界框
yolo_str = process_bbox(each_ann, img_width, img_height, labelme['shapes'])
f.write(yolo_str + '\n')
# 复制对应的图像文件到保存目录
image_name = labelme['imagePath']
image_src_path = os.path.join(Dataset_root, image_name)
if os.path.exists(image_src_path):
shutil.copy(image_src_path, save_folder)
print(f'复制图像 {image_name} 到 {save_folder}')
else:
print(f"图像文件不存在,跳过: {image_src_path}")
print(f'{labelme_path} --> {yolo_txt_path} 转换完成')
def process_bbox(bbox_ann, img_width, img_height, all_annotations):
"""
处理单个边界框及其关键点
:param bbox_ann: 边界框标注信息
:param img_width: 图像宽度
:param img_height: 图像高度
:param all_annotations: 所有标注信息
:return: YOLO 格式的字符串
"""
yolo_str = ''
# 框的类别 ID
bbox_class_id = bbox_class.index(bbox_ann['label'])
yolo_str += f'{bbox_class_id} '
# 计算边界框的最小和最大坐标
points = np.array(bbox_ann['points'])
bbox_top_left_x = int(np.min(points[:, 0]))
bbox_bottom_right_x = int(np.max(points[:, 0]))
bbox_top_left_y = int(np.min(points[:, 1]))
bbox_bottom_right_y = int(np.max(points[:, 1]))
# 框中心点的归一化坐标和归一化宽高
bbox_center_x_norm = (bbox_top_left_x + bbox_bottom_right_x) / 2 / img_width
bbox_center_y_norm = (bbox_top_left_y + bbox_bottom_right_y) / 2 / img_height
bbox_width_norm = (bbox_bottom_right_x - bbox_top_left_x) / img_width
bbox_height_norm = (bbox_bottom_right_y - bbox_top_left_y) / img_height
yolo_str += f'{bbox_center_x_norm:.5f} {bbox_center_y_norm:.5f} {bbox_width_norm:.5f} {bbox_height_norm:.5f} '
# 处理关键点
bbox_keypoints_dict = process_keypoints(bbox_top_left_x, bbox_bottom_right_x, bbox_top_left_y, bbox_bottom_right_y, all_annotations, img_width, img_height)
for keypoint in keypoint_class:
if keypoint in bbox_keypoints_dict:
keypoint_x_norm, keypoint_y_norm, visibility = bbox_keypoints_dict[keypoint]
yolo_str += f'{keypoint_x_norm:.5f} {keypoint_y_norm:.5f} {visibility} '
else:
yolo_str += '0 0 0 ' # 如果没有该关键点,写入 0
return yolo_str
def process_keypoints(bbox_top_left_x, bbox_bottom_right_x, bbox_top_left_y, bbox_bottom_right_y, all_annotations, img_width, img_height):
bbox_keypoints_dict = {}
for each_ann in all_annotations:
if each_ann['shape_type'] == 'point': # 筛选出关键点标注
x = int(each_ann['points'][0][0])
y = int(each_ann['points'][0][1])
label = each_ann['label']
if (bbox_top_left_x < x < bbox_bottom_right_x) and (bbox_top_left_y < y < bbox_bottom_right_y):
keypoint_x_norm = x / img_width
keypoint_y_norm = y / img_height
bbox_keypoints_dict[label] = [keypoint_x_norm, keypoint_y_norm, 2] # 2-可见不遮挡
print(f"Keypoint {label} at ({x}, {y}) normalized to ({keypoint_x_norm}, {keypoint_y_norm})")
return bbox_keypoints_dict
# 遍历 JSON 文件并处理
for labelme_path in os.listdir(Dataset_root):
if labelme_path.endswith('.json'):
full_path = os.path.join(Dataset_root, labelme_path)
process_single_json(full_path, save_folder)
print(f'YOLO 格式的 TXT 标注文件已保存至 {save_folder}')3、数据集文件夹结构
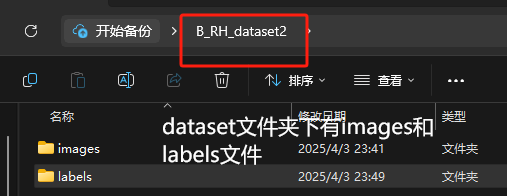
images文件夹存放你的图片,里面的子文件夹通过python代码可以进行按比例划分。labels文件夹是采用labelimg打的对应每张图片的标签,格式是txt格式。
自定义数据集结构:
dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/ # 可选
└── labels/
├── train/
├── val/
└── test/
import os
import shutil
import random
# 原始文件路径 (替换成你自己的路径)
image_folder = "C:/Users/16046/Desktop/png" # PNG 图片所在文件夹
label_folder = "C:/Users\/16046/Desktop/label" # JSON 转换后的 YOLO txt 标签所在文件夹
# 目标数据集结构
dataset_root = "C:/Users/Desktop/dataset" #生成的根文件夹dataset 替换成你自己的路径
image_train_dir = os.path.join(dataset_root, "images/train")
image_val_dir = os.path.join(dataset_root, "images/val")
label_train_dir = os.path.join(dataset_root, "labels/train")
label_val_dir = os.path.join(dataset_root, "labels/val")
# 创建数据集目录
for dir_path in [image_train_dir, image_val_dir, label_train_dir, label_val_dir]:
os.makedirs(dir_path, exist_ok=True)
# 获取所有图片名称(假设 PNG 文件和 TXT 标签名称一致)
image_files = [f for f in os.listdir(image_folder) if f.endswith(".png")]
random.shuffle(image_files) # 打乱数据
# 数据集划分比例
train_ratio = 0.8
num_train = int(len(image_files) * train_ratio)
# 划分数据集
train_files = image_files[:num_train]
val_files = image_files[num_train:]
# 复制文件到对应目录
for file_list, img_dest, lbl_dest in [(train_files, image_train_dir, label_train_dir),
(val_files, image_val_dir, label_val_dir)]:
for img_file in file_list:
# 复制图片
shutil.copy(os.path.join(image_folder, img_file), os.path.join(img_dest, img_file))
# 复制对应的标签
label_file = img_file.replace(".png", ".txt")
label_src = os.path.join(label_folder, label_file)
if os.path.exists(label_src): # 确保标签文件存在
shutil.copy(label_src, os.path.join(lbl_dest, label_file))
print("数据集划分完成!")划分好之后,大概会生成类似的文件夹目录
4. 生成data.yaml文件
最后还需要自己写一份data.yaml文件放在dataset文件夹下。
该文件格式类似于:
# 数据集配置
path: /path/to/dataset # 数据集的根目录
train: images/train # 训练集图片路径
val: images/val # 验证集图片路径
# 类别信息
nc: 3 # 类别数量
names: ['class1', 'class2', 'class3'] # 类别名称
三、yolo环境配置
1、pytorch环境安装
YOLOV8全环境配置教程(图文教程,30分钟可配置完成!!)_yolov8环境配置-CSDN博客
2、其他依赖库安装
pip install requirement.txt
# Ultralytics requirements
# Example: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.3.0
numpy==1.24.4 # pinned by Snyk to avoid a vulnerability
opencv-python>=4.6.0
pillow>=7.1.2
pyyaml>=5.3.1
requests>=2.23.0
scipy>=1.4.1
tqdm>=4.64.0
# Logging -------------------------------------
# tensorboard>=2.13.0
# dvclive>=2.12.0
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=7.0 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
py-cpuinfo # display CPU info
thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3 # training augmentations
# pycocotools>=2.0.6 # COCO mAP
# roboflow
3、yolo11训练
新建一个train.py文件,代码如下:
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# model.load('yolo11n.pt') # 加载预训练权重,改进或者做对比实验时候不建议打开,因为用预训练模型整体精度没有很明显的提升
model = YOLO(model=r'D:\2-Python\1-YOLO\YOLOv11\ultralytics-8.3.2\ultralytics\cfg\models\11\yolo11.yaml')
model.train(data=r'data.yaml',
imgsz=640,
epochs=50,
batch=4,
workers=0,
device='',
optimizer='SGD',
close_mosaic=10,
resume=False,
project='runs/train',
name='exp',
single_cls=False,
cache=False,
)
并且修改自己的配置路径参数
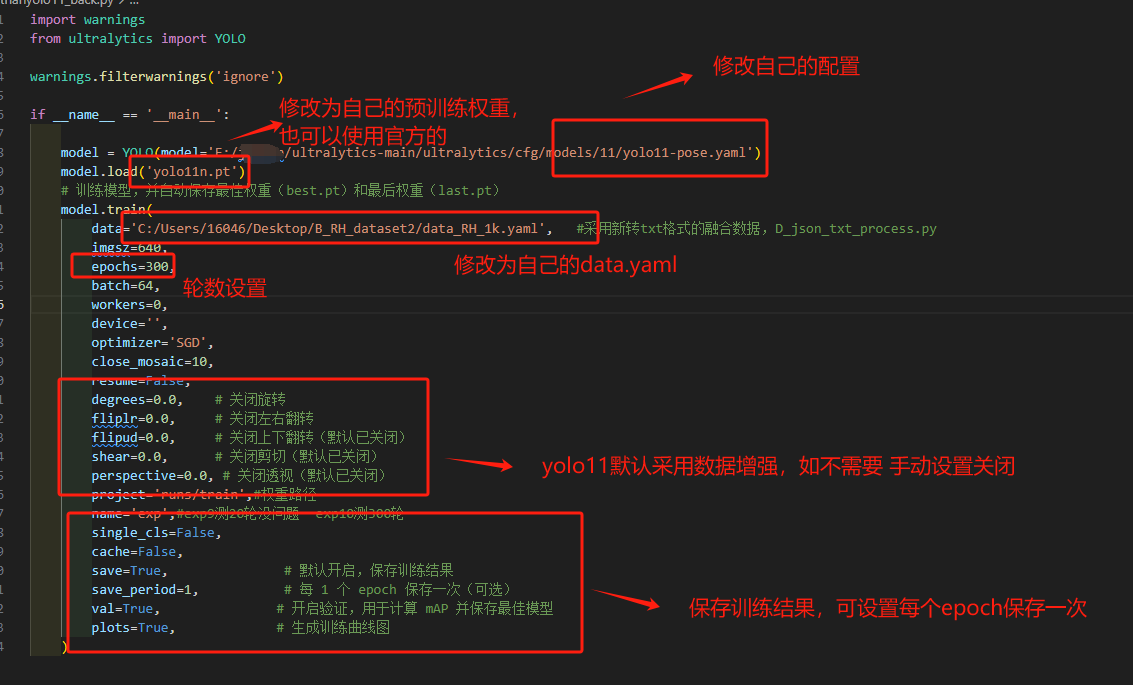

如有需要 可以在ultralytics/cfg/default.yaml路径下修改自己所需的参数
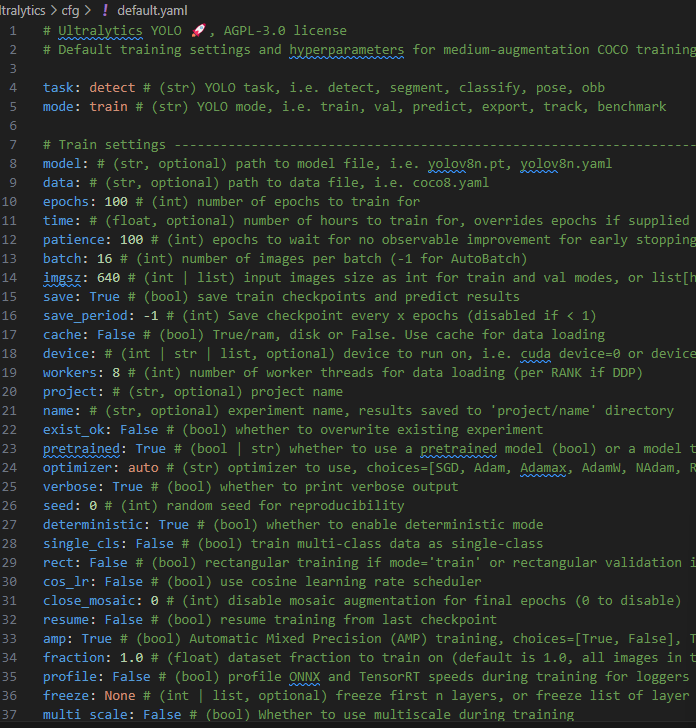
4.yolo11预测
①预测单张图
import cv2
import os
import pandas as pd
import sys
root_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
sys.path.append(root_path)
from ultralytics import YOLO
# 加载模型
#model = YOLO('back_27points.pt') # 加载旧权重
model = YOLO('runs/train/exp8/weights/best.pt') #新权重
#model = YOLO('runs/train/exp8/weights/best.pt')
# image_folder = 'E:/dataset/auto_label'
output_folder = "C:/Users/16046/Desktop/predict2"
image_name = '123.png'
img_path = "C:/Users/3Desktop/output_classified/b"
if not os.path.exists(output_folder):
os.makedirs(output_folder)
img = cv2.imread(os.path.join(img_path, image_name))
# 进行推理
results = model(img)[0]
print(f"Processing {image_name}")
# 保存推理结果到输出文件夹
output_path = os.path.join(output_folder, f"result_{image_name}")
results.save(output_path) # 保存推理结果到输出文件夹②批量预测文件夹的所有图片
class YOLOPredictor:
def __init__(self):
"""
初始化YOLO预测器
"""
self.model_weights = "runs/train/exp10/weights/epoch298.pt"
self.model = YOLO(self.model_weights) # 加载模型权重
def predict_and_save(
self,
image_path: Union[str, Path],
output_dir: Union[str, Path],
output_filename: Optional[str] = None,
save: bool = True
) -> Results:
"""
对单张图片进行预测并保存结果
参数:
image_path: 输入图片路径
output_dir: 输出目录路径
output_filename: 自定义输出文件名 (默认使用输入文件名)
save: 是否保存预测结果图片
返回:
ultralytics的预测结果对象
"""
# 转换路径类型并创建输出目录
image_path = Path(image_path)
output_dir = Path(output_dir)
output_dir.mkdir(parents=True, exist_ok=True)
# 读取图片
img = cv2.imread(str(image_path))
if img is None:
raise FileNotFoundError(f"无法读取图片: {image_path}")
# 执行预测
results = self.model(img)[0]
print(f"处理完成: {image_path.name}")
# 保存结果
if save:
output_name = output_filename or f"pred_{image_path.name}"
output_path = output_dir / output_name
results.save(str(output_path))
print(f"结果已保存至: {output_path}")
return results
def batch_predict(
self,
input_dir: Union[str, Path],
output_dir: Union[str, Path],
extensions: List[str] = ['.jpg', '.jpeg', '.png']
) -> None:
"""
批量处理文件夹中的所有图片
参数:
input_dir: 输入图片文件夹路径
output_dir: 输出目录路径
extensions: 支持的图片扩展名列表
"""
input_dir = Path(input_dir)
output_dir = Path(output_dir)
if not input_dir.exists():
raise FileNotFoundError(f"输入目录不存在: {input_dir}")
# 获取所有符合条件的图片文件
image_files = []
for ext in extensions:
image_files.extend(list(input_dir.glob(f'*{ext}')))
print(f"发现 {len(image_files)} 张待处理图片")
for img_path in image_files:
try:
self.predict_and_save(
image_path=img_path,
output_dir=output_dir,
output_filename=f"pred_{img_path.name}", # 保持原文件名,前面加pred_
save=True
)
except Exception as e:
print(f"处理图片 {img_path.name} 时出错: {str(e)}")
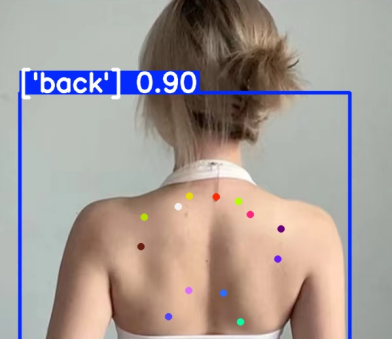
四、结果预测展示
这里我做的是关键点检测。
五、总结
yolo11是个好东西。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









