







文章目录
一、关于 UI-TARS
- github : https://github.com/bytedance/UI-TARS
- Paper : UI-TARS: Pioneering Automated GUI Interaction with Native Agents
https://arxiv.org/abs/2501.12326 - 🤗Hugging Face 模型|📑论文|🖥️UI-TARS-desktop | 🏄中间场景(浏览器自动化)|🫨Discord
我们还提供UI-TARS-desktop版本,可以在您的本地个人设备上运行,要使用它,请访问 https://github.com/bytedance/UI-TARS-desktop。
要在Web自动化中使用UI-TARS,您可以参考开源项目Midsite.js。
⚠️重要公告:GGUF模型性能
GGUF模型经历了量化,但不幸的是,它的性能无法保证。因此,我们决定将其降级。
💡替代解决方案:
您可以使用**云部署或[本地部署vLLM]**(如果您有足够的GPU资源)。
我们感谢您的理解和耐心,因为我们努力确保获得最佳体验。
概览
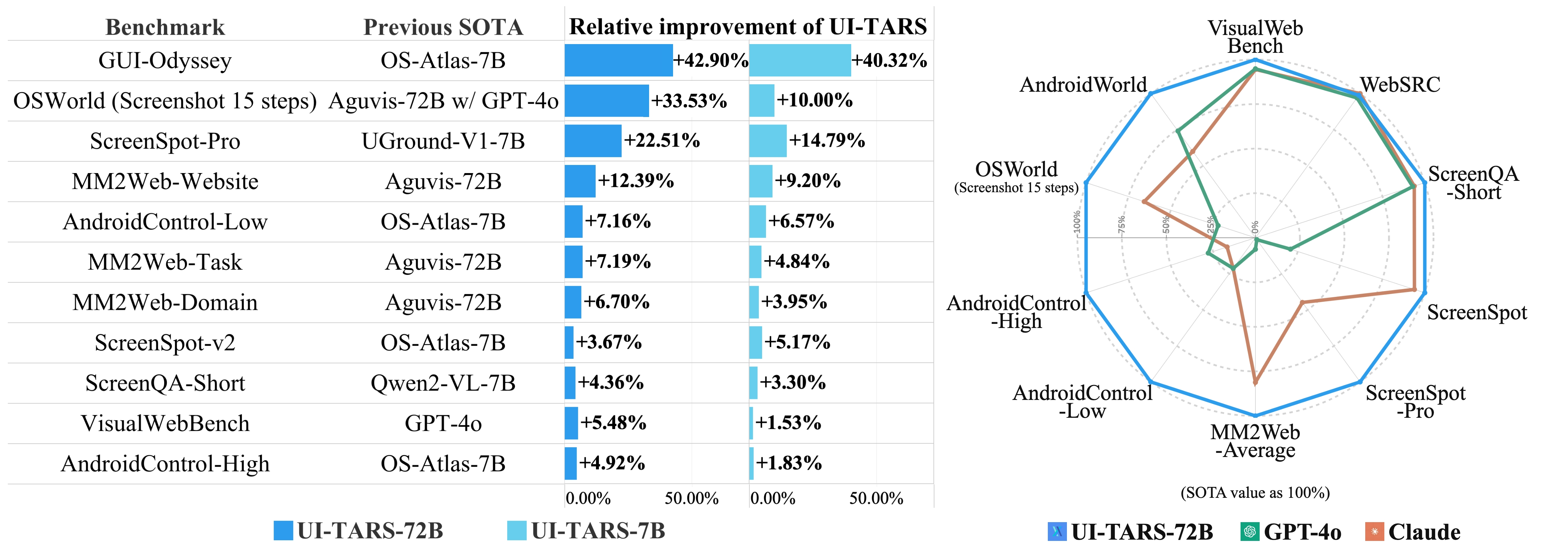
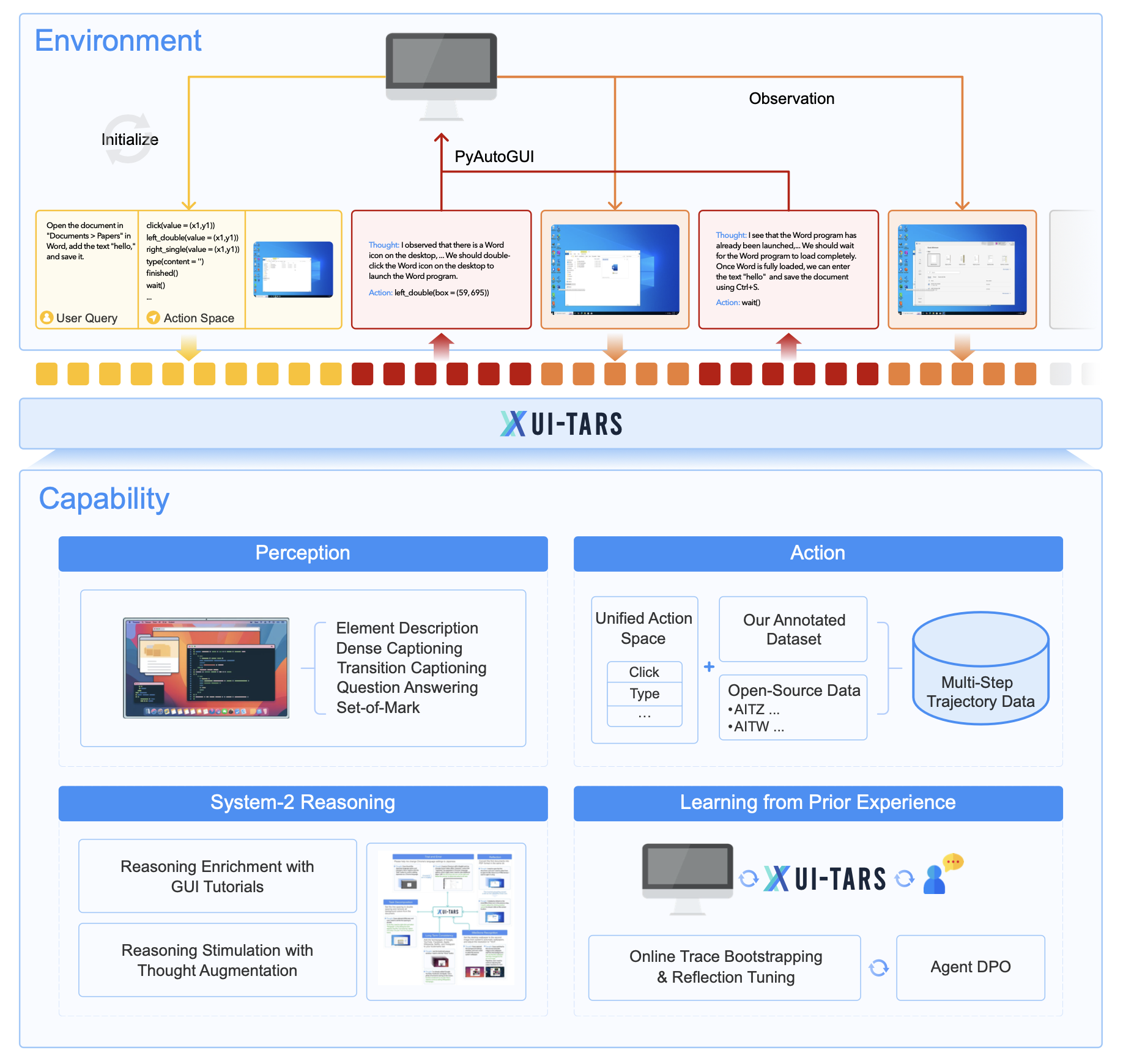
核心功能
知觉
- 全面的GUI理解:处理多模态输入(文本、图像、交互)以建立对界面的连贯理解。
- 实时交互:持续监控动态GUI并实时准确响应变化。
行动
- 统一操作空间:跨平台(桌面、移动和Web)的标准化操作定义。
- 特定于平台的操作:支持热键、长按和特定于平台的手势等附加操作。
推理
- 系统1和系统2推理:将快速、直观的响应与针对复杂任务的深思熟虑的高级计划相结合。
- 任务分解和反射:支持多步骤规划、反射和纠错,以实现稳健的任务执行。
记忆
- 短期记忆:捕捉特定于任务的上下文以获得情境感知。
- 长期记忆:保留历史互动和知识,以改进决策。
能力
- 跨平台交互:通过统一的操作框架支持桌面、移动和Web环境。
- 多步骤任务执行:经过训练,可以通过多步骤轨迹和推理来处理复杂的任务。
- 从合成数据和真实数据中学习:结合大规模带注释和合成数据集以提高泛化和稳健性。
二、部署
云部署
我们建议使用HuggingFace推理端点进行快速部署。我们提供两个文档供用户参考:
英文版:GUI模型部署指南
中文版: GUI模型部署教程
本地部署[Transformers ]
我们遵循与Qwen2-VL相同的方式,查看此教程以获取更多详细信息。
本地部署[vLLM]
我们建议使用vLLM进行快速部署和推理,需要使用vllm>=0.6.1。
pip install -U transformers
VLLM_VERSION=0.6.6
CUDA_VERSION=cu124
pip install vllm==${VLLM_VERSION} --extra-index-url https://download.pytorch.org/whl/${CUDA_VERSION}
下载模型
我们在Hugging Face 上提供了三种模型尺寸:2B、7B和72B。为了获得最佳性能,我们建议使用7B-DPO或72B-DPO模型(取决于您的GPU配置):
启动OpenAI API服务
运行以下命令以启动与OpenAI兼容的API服务:
python -m vllm.entrypoints.openai.api_server --served-model-name ui-tars --model <path to your model>
然后你可以使用聊天API如下与gui提示符(从移动或计算机中选择)和base64编码的本地图像(见OpenAI API协议文档了解更多细节),你也可以使用它在UI-TARS-desktop:
import base64
from openai import OpenAI
instruction = "search for today's weather"
screenshot_path = "screenshot.png"
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key="empty",
)
***
## Below is the prompt for mobile
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
***
## Output Format
```\nThought: ...
Action: ...\n```
***
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
left_double(start_box='<|box_start|>(x1,y1)<|box_end|>')
right_single(start_box='<|box_start|>(x1,y1)<|box_end|>')
drag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
hotkey(key='')
type(content='') #If you want to submit your input, use \"\
\" at the end of `content`.
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
call_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.
***
## Note
- Use Chinese in `Thought` part.
- Summarize your next action (with its target element) in one sentence in `Thought` part.
***
## User Instruction
"""
with open(screenshot_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
response = client.chat.completions.create(
model="ui-tars",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt + instruction},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{encoded_string}"}},
],
},
],
frequency_penalty=1,
max_tokens=128,
)
print(response.choices[0].message.content)
对于单步接地任务或对Seeclick等接地数据集的推断,请参阅以下脚本:
import base64
from openai import OpenAI
instruction = "search for today's weather"
screenshot_path = "screenshot.png"
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key="empty",
)
***
## Below is the prompt for mobile
prompt = r"""Output only the coordinate of one point in your response. What element matches the following task: """
with open(screenshot_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
response = client.chat.completions.create(
model="ui-tars",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{encoded_string}"}},
{"type": "text", "text": prompt + instruction}
],
},
],
frequency_penalty=1,
max_tokens=128,
)
print(response.choices[0].message.content)
提示模板
我们目前为稳定运行和性能提供了两个提示模板,一个用于移动场景,一个用于个人电脑场景。
- 手机提示模板:
## Below is the prompt for mobile
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
***
## Output Format
```\nThought: ...
Action: ...\n```
***
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
long_press(start_box='<|box_start|>(x1,y1)<|box_end|>', time='')
type(content='')
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
press_home()
press_back()
finished(content='') # Submit the task regardless of whether it succeeds or fails.
***
## Note
- Use English in `Thought` part.
- Write a small plan and finally summarize your next action (with its target element) in one sentence in `Thought` part.
***
## User Instruction
"""
- 计算机提示模板:
## Below is the prompt for computer
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
***
## Output Format
```\nThought: ...
Action: ...\n```
***
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
left_double(start_box='<|box_start|>(x1,y1)<|box_end|>')
right_single(start_box='<|box_start|>(x1,y1)<|box_end|>')
drag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
hotkey(key='')
type(content='') #If you want to submit your input, use \"\
\" at the end of `content`.
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
call_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.
***
## Note
- Use Chinese in `Thought` part.
- Summarize your next action (with its target element) in one sentence in `Thought` part.
***
## User Instruction
"""
本地部署 [Ollama]
Ollama will be coming soon. Please be patient and wait~ 😊
推理结果解释
坐标映射
该模型生成表示相对位置的2D坐标输出。要将这些值转换为图像相对坐标,请将每个组件除以1000以获得[0,1]范围内的值。Action所需的绝对坐标可以通过以下方式计算:
- X absolute = X relative × image width
- Y absolute = Y relative × image height
例如,给定屏幕尺寸:1920×1080,模型生成坐标输出为(235,512),X绝对值为round(1920*235/1000)=451,Y绝对值为round(1080*512/1000)=553,绝对坐标为(451,553)
三、用于桌面和Web自动化
要在桌面中体验用户界面-tars代理,您可以参考 UI-TARS-desktop 。我们建议在桌面上使用7B/72BDPO模型。
Midsite. js是一个开源的web自动化SDK,已经支持了UI-TARS模型,开发者可以使用javascript和自然语言来控制浏览器,有关设置模型的更多详细信息,请参见本指南。
四、表现
Perception Capabilty Evaluation
| Model | VisualWebBench | WebSRC | SQAshort |
|---|---|---|---|
| Qwen2-VL-7B | 73.3 | 81.8 | 84.9 |
| Qwen-VL-Max | 74.1 | 91.1 | 78.6 |
| Gemini-1.5-Pro | 75.4 | 88.9 | 82.2 |
| UIX-Qwen2-7B | 75.9 | 82.9 | 78.8 |
| Claude-3.5-Sonnet | 78.2 | 90.4 | 83.1 |
| GPT-4o | 78.5 | 87.7 | 82.3 |
| UI-TARS-2B | 72.9 | 89.2 | 86.4 |
| UI-TARS-7B | 79.7 | 93.6 | 87.7 |
| UI-TARS-72B | 82.8 | 89.3 | 88.6 |
Grounding Capability Evaluation
- ScreenSpot Pro
| Agent Model | Dev-Text | Dev-Icon | Dev-Avg | Creative-Text | Creative-Icon | Creative-Avg | CAD-Text | CAD-Icon | CAD-Avg | Scientific-Text | Scientific-Icon | Scientific-Avg | Office-Text | Office-Icon | Office-Avg | OS-Text | OS-Icon | OS-Avg | Avg-Text | Avg-Icon | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| QwenVL-7B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 0.0 | 0.4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.0 | 0.1 |
| GPT-4o | 1.3 | 0.0 | 0.7 | 1.0 | 0.0 | 0.6 | 2.0 | 0.0 | 1.5 | 2.1 | 0.0 | 1.2 | 1.1 | 0.0 | 0.9 | 0.0 | 0.0 | 0.0 | 1.3 | 0.0 | 0.8 |
| SeeClick | 0.6 | 0.0 | 0.3 | 1.0 | 0.0 | 0.6 | 2.5 | 0.0 | 1.9 | 3.5 | 0.0 | 2.0 | 1.1 | 0.0 | 0.9 | 2.8 | 0.0 | 1.5 | 1.8 | 0.0 | 1.1 |
| Qwen2-VL-7B | 2.6 | 0.0 | 1.3 | 1.5 | 0.0 | 0.9 | 0.5 | 0.0 | 0.4 | 6.3 | 0.0 | 3.5 | 3.4 | 1.9 | 3.0 | 0.9 | 0.0 | 0.5 | 2.5 | 0.2 | 1.6 |
| OS-Atlas-4B | 7.1 | 0.0 | 3.7 | 3.0 | 1.4 | 2.3 | 2.0 | 0.0 | 1.5 | 9.0 | 5.5 | 7.5 | 5.1 | 3.8 | 4.8 | 5.6 | 0.0 | 3.1 | 5.0 | 1.7 | 3.7 |
| ShowUI-2B | 16.9 | 1.4 | 9.4 | 9.1 | 0.0 | 5.3 | 2.5 | 0.0 | 1.9 | 13.2 | 7.3 | 10.6 | 15.3 | 7.5 | 13.5 | 10.3 | 2.2 | 6.6 | 10.8 | 2.6 | 7.7 |
| CogAgent-18B | 14.9 | 0.7 | 8.0 | 9.6 | 0.0 | 5.6 | 7.1 | 3.1 | 6.1 | 22.2 | 1.8 | 13.4 | 13.0 | 0.0 | 10.0 | 5.6 | 0.0 | 3.1 | 12.0 | 0.8 | 7.7 |
| Aria-UI | 16.2 | 0.0 | 8.4 | 23.7 | 2.1 | 14.7 | 7.6 | 1.6 | 6.1 | 27.1 | 6.4 | 18.1 | 20.3 | 1.9 | 16.1 | 4.7 | 0.0 | 2.6 | 17.1 | 2.0 | 11.3 |
| UGround-7B | 26.6 | 2.1 | 14.7 | 27.3 | 2.8 | 17.0 | 14.2 | 1.6 | 11.1 | 31.9 | 2.7 | 19.3 | 31.6 | 11.3 | 27.0 | 17.8 | 0.0 | 9.7 | 25.0 | 2.8 | 16.5 |
| Claude Computer Use | 22.0 | 3.9 | 12.6 | 25.9 | 3.4 | 16.8 | 14.5 | 3.7 | 11.9 | 33.9 | 15.8 | 25.8 | 30.1 | 16.3 | 26.9 | 11.0 | 4.5 | 8.1 | 23.4 | 7.1 | 17.1 |
| OS-Atlas-7B | 33.1 | 1.4 | 17.7 | 28.8 | 2.8 | 17.9 | 12.2 | 4.7 | 10.3 | 37.5 | 7.3 | 24.4 | 33.9 | 5.7 | 27.4 | 27.1 | 4.5 | 16.8 | 28.1 | 4.0 | 18.9 |
| UGround-V1-7B | - | - | 35.5 | - | - | 27.8 | - | - | 13.5 | - | - | 38.8 | - | - | 48.8 | - | - | 26.1 | - | - | 31.1 |
| UI-TARS-2B | 47.4 | 4.1 | 26.4 | 42.9 | 6.3 | 27.6 | 17.8 | 4.7 | 14.6 | 56.9 | 17.3 | 39.8 | 50.3 | 17.0 | 42.6 | 21.5 | 5.6 | 14.3 | 39.6 | 8.4 | 27.7 |
| UI-TARS-7B | 58.4 | 12.4 | 36.1 | 50.0 | 9.1 | 32.8 | 20.8 | 9.4 | 18.0 | 63.9 | 31.8 | 50.0 | 63.3 | 20.8 | 53.5 | 30.8 | 16.9 | 24.5 | 47.8 | 16.2 | 35.7 |
| UI-TARS-72B | 63.0 | 17.3 | 40.8 | 57.1 | 15.4 | 39.6 | 18.8 | 12.5 | 17.2 | 64.6 | 20.9 | 45.7 | 63.3 | 26.4 | 54.8 | 42.1 | 15.7 | 30.1 | 50.9 | 17.5 | 38.1 |
- ScreenSpot
| Method | Mobile-Text | Mobile-Icon/Widget | Desktop-Text | Desktop-Icon/Widget | Web-Text | Web-Icon/Widget | Avg |
|---|---|---|---|---|---|---|---|
| Agent Framework | |||||||
| GPT-4 (SeeClick) | 76.6 | 55.5 | 68.0 | 28.6 | 40.9 | 23.3 | 48.8 |
| GPT-4 (OmniParser) | 93.9 | 57.0 | 91.3 | 63.6 | 81.3 | 51.0 | 73.0 |
| GPT-4 (UGround-7B) | 90.1 | 70.3 | 87.1 | 55.7 | 85.7 | 64.6 | 75.6 |
| GPT-4o (SeeClick) | 81.0 | 59.8 | 69.6 | 33.6 | 43.9 | 26.2 | 52.3 |
| GPT-4o (UGround-7B) | 93.4 | 76.9 | 92.8 | 67.9 | 88.7 | 68.9 | 81.4 |
| Agent Model | |||||||
| GPT-4 | 22.6 | 24.5 | 20.2 | 11.8 | 9.2 | 8.8 | 16.2 |
| GPT-4o | 20.2 | 24.9 | 21.1 | 23.6 | 12.2 | 7.8 | 18.3 |
| CogAgent | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | 47.4 |
| SeeClick | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| Qwen2-VL | 75.5 | 60.7 | 76.3 | 54.3 | 35.2 | 25.7 | 55.3 |
| UGround-7B | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| Aguvis-G-7B | 88.3 | 78.2 | 88.1 | 70.7 | 85.7 | 74.8 | 81.8 |
| OS-Atlas-7B | 93.0 | 72.9 | 91.8 | 62.9 | 90.9 | 74.3 | 82.5 |
| Claude Computer Use | - | - | - | - | - | - | 83.0 |
| Gemini 2.0 (Project Mariner) | - | - | - | - | - | - | 84.0 |
| Aguvis-7B | 95.6 | 77.7 | 93.8 | 67.1 | 88.3 | 75.2 | 84.4 |
| Aguvis-72B | 94.5 | 85.2 | 95.4 | 77.9 | 91.3 | 85.9 | 89.2 |
| Our Model | |||||||
| UI-TARS-2B | 93.0 | 75.5 | 90.7 | 68.6 | 84.3 | 74.8 | 82.3 |
| UI-TARS-7B | 94.5 | 85.2 | 95.9 | 85.7 | 90.0 | 83.5 | 89.5 |
| UI-TARS-72B | 94.9 | 82.5 | 89.7 | 88.6 | 88.7 | 85.0 | 88.4 |
- ScreenSpot v2
| Method | Mobile-Text | Mobile-Icon/Widget | Desktop-Text | Desktop-Icon/Widget | Web-Text | Web-Icon/Widget | Avg |
|---|---|---|---|---|---|---|---|
| Agent Framework | |||||||
| GPT-4o (SeeClick) | 85.2 | 58.8 | 79.9 | 37.1 | 72.7 | 30.1 | 63.6 |
| GPT-4o (OS-Atlas-4B) | 95.5 | 75.8 | 79.4 | 49.3 | 90.2 | 66.5 | 79.1 |
| GPT-4o (OS-Atlas-7B) | 96.2 | 83.4 | 89.7 | 69.3 | 94.0 | 79.8 | 87.1 |
| Agent Model | |||||||
| SeeClick | 78.4 | 50.7 | 70.1 | 29.3 | 55.2 | 32.5 | 55.1 |
| OS-Atlas-4B | 87.2 | 59.7 | 72.7 | 46.4 | 85.9 | 63.1 | 71.9 |
| OS-Atlas-7B | 95.2 | 75.8 | 90.7 | 63.6 | 90.6 | 77.3 | 84.1 |
| Our Model | |||||||
| UI-TARS-2B | 95.2 | 79.1 | 90.7 | 68.6 | 87.2 | 78.3 | 84.7 |
| UI-TARS-7B | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 |
| UI-TARS-72B | 94.8 | 86.3 | 91.2 | 87.9 | 91.5 | 87.7 | 90.3 |
Offline Agent Capability Evaluation
- Multimodal Mind2Web
| Method | Cross-Task Ele.Acc | Cross-Task Op.F1 | Cross-Task Step SR | Cross-Website Ele.Acc | Cross-Website Op.F1 | Cross-Website Step SR | Cross-Domain Ele.Acc | Cross-Domain Op.F1 | Cross-Domain Step SR |
|---|---|---|---|---|---|---|---|---|---|
| Agent Framework | |||||||||
| GPT-4o (SeeClick) | 32.1 | - | - | 33.1 | - | - | 33.5 | - | - |
| GPT-4o (UGround) | 47.7 | - | - | 46.0 | - | - | 46.6 | - | - |
| GPT-4o (Aria-UI) | 57.6 | - | - | 57.7 | - | - | 61.4 | - | - |
| GPT-4V (OmniParser) | 42.4 | 87.6 | 39.4 | 41.0 | 84.8 | 36.5 | 45.5 | 85.7 | 42.0 |
| Agent Model | |||||||||
| GPT-4o | 5.7 | 77.2 | 4.3 | 5.7 | 79.0 | 3.9 | 5.5 | 86.4 | 4.5 |
| GPT-4 (SOM) | 29.6 | - | 20.3 | 20.1 | - | 13.9 | 27.0 | - | 23.7 |
| GPT-3.5 (Text-only) | 19.4 | 59.2 | 16.8 | 14.9 | 56.5 | 14.1 | 25.2 | 57.9 | 24.1 |
| GPT-4 (Text-only) | 40.8 | 63.1 | 32.3 | 30.2 | 61.0 | 27.0 | 35.4 | 61.9 | 29.7 |
| Claude | 62.7 | 84.7 | 53.5 | 59.5 | 79.6 | 47.7 | 64.5 | 85.4 | 56.4 |
| Aguvis-7B | 64.2 | 89.8 | 60.4 | 60.7 | 88.1 | 54.6 | 60.4 | 89.2 | 56.6 |
| CogAgent | - | - | 62.3 | - | - | 54.0 | - | - | 59.4 |
| Aguvis-72B | 69.5 | 90.8 | 64.0 | 62.6 | 88.6 | 56.5 | 63.5 | 88.5 | 58.2 |
| Our Model | |||||||||
| UI-TARS-2B | 62.3 | 90.0 | 56.3 | 58.5 | 87.2 | 50.8 | 58.8 | 89.6 | 52.3 |
| UI-TARS-7B | 73.1 | 92.2 | 67.1 | 68.2 | 90.9 | 61.7 | 66.6 | 90.9 | 60.5 |
| UI-TARS-72B | 74.7 | 92.5 | 68.6 | 72.4 | 91.2 | 63.5 | 68.9 | 91.8 | 62.1 |
- Android Control and GUI Odyssey
| Agent Models | AndroidControl-Low Type | AndroidControl-Low Grounding | AndroidControl-Low SR | AndroidControl-High Type | AndroidControl-High Grounding | AndroidControl-High SR | GUIOdyssey Type | GUIOdyssey Grounding | GUIOdyssey SR |
|---|---|---|---|---|---|---|---|---|---|
| Claude | 74.3 | 0.0 | 19.4 | 63.7 | 0.0 | 12.5 | 60.9 | 0.0 | 3.1 |
| GPT-4o | 74.3 | 0.0 | 19.4 | 66.3 | 0.0 | 20.8 | 34.3 | 0.0 | 3.3 |
| SeeClick | 93.0 | 73.4 | 75.0 | 82.9 | 62.9 | 59.1 | 71.0 | 52.4 | 53.9 |
| InternVL-2-4B | 90.9 | 84.1 | 80.1 | 84.1 | 72.7 | 66.7 | 82.1 | 55.5 | 51.5 |
| Qwen2-VL-7B | 91.9 | 86.5 | 82.6 | 83.8 | 77.7 | 69.7 | 83.5 | 65.9 | 60.2 |
| Aria-UI | – | 87.7 | 67.3 | – | 43.2 | 10.2 | – | 86.8 | 36.5 |
| OS-Atlas-4B | 91.9 | 83.8 | 80.6 | 84.7 | 73.8 | 67.5 | 83.5 | 61.4 | 56.4 |
| OS-Atlas-7B | 93.6 | 88.0 | 85.2 | 85.2 | 78.5 | 71.2 | 84.5 | 67.8 | 62.0 |
| Aguvis-7B | – | – | 80.5 | – | – | 61.5 | – | – | – |
| Aguvis-72B | – | – | 84.4 | – | – | 66.4 | – | – | – |
| UI-TARS-2B | 98.1 | 87.3 | 89.3 | 81.2 | 78.4 | 68.9 | 93.9 | 86.8 | 83.4 |
| UI-TARS-7B | 98.0 | 89.3 | 90.8 | 83.7 | 80.5 | 72.5 | 94.6 | 90.1 | 87.0 |
| UI-TARS-72B | 98.1 | 89.9 | 91.3 | 85.2 | 81.5 | 74.7 | 95.4 | 91.4 | 88.6 |
Online Agent Capability Evaluation
| Method | OSWorld (Online) | AndroidWorld (Online) |
|---|---|---|
| Agent Framework | ||
| GPT-4o (UGround) | - | 32.8 |
| GPT-4o (Aria-UI) | 15.2 | 44.8 |
| GPT-4o (Aguvis-7B) | 14.8 | 37.1 |
| GPT-4o (Aguvis-72B) | 17.0 | - |
| GPT-4o (OS-Atlas-7B) | 14.6 | - |
| Agent Model | ||
| GPT-4o | 5.0 | 34.5 (SoM) |
| Gemini-Pro-1.5 | 5.4 | 22.8 (SoM) |
| Aguvis-72B | 10.3 | 26.1 |
| Claude Computer-Use | 14.9 (15 steps) | 27.9 |
| Claude Computer-Use | 22.0 (50 steps) | - |
| Our Model | ||
| UI-TARS-7B-SFT | 17.7 (15 steps) | 33.0 |
| UI-TARS-7B-DPO | 18.7 (15 steps) | - |
| UI-TARS-72B-SFT | 18.8 (15 steps) | 46.6 |
| UI-TARS-72B-DPO | 22.7 (15 steps) | - |
| UI-TARS-72B-DPO | 24.6 (50 steps) | - |
2025-02-03(一)


















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









