







文章目录
一、关于 Phi-4-multimodal-instruct
模型概述
Phi-4-multimodal-instruct 是一个轻量级开源多模态基础模型,融合了 Phi-3.5 和 4.0 系列模型的语言、视觉及语音研究成果与数据集。
该模型可处理文本、图像和音频输入,生成文本输出,并具备 128K token 的上下文长度。
模型经过增强训练流程,结合了监督微调、直接偏好优化以及 RLHF(人类反馈强化学习)技术,以确保精准的指令遵循能力和安全措施。各模态支持的语言如下:
- 文本:阿拉伯语、中文、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、德语、希伯来语、匈牙利语、意大利语、日语、韩语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、瑞典语、泰语、土耳其语、乌克兰语
- 视觉:英语
- 音频:英语、中文、德语、法语、意大利语、日语、西班牙语、葡萄牙语
相关链接信息
-
Hugging Face:https://huggingface.co/microsoft/Phi-4-multimodal-instruct
-
开发团队:Microsoft Research
-
模型类型:多模态指令微调模型(支持文本/图像/语音输入)
-
📰 Phi-4-multimodal 微软博客: https://aka.ms/phi4-feb2025
-
📖 Phi-4-multimodal 技术报告: https://arxiv.org/abs/2503.01743
-
🏡 Phi 门户: https://aka.ms/phi-4-multimodal/azure
-
👩🍳 Phi 实践指南: https://github.com/microsoft/PhiCookBook
-
🖥️ 体验平台:Azure、GitHub、Nvidia、Huggingface
-
Huggingface 空间:Thoughts Organizer, Stories Come Alive, Phine Speech Translator
-
社交媒体:Twitter | Technical Blog
-
License:MIT License | LICENSE
-
🎉Phi-4 系列模型: [mini-reasoning | reasoning] | [multimodal-instruct | onnx]; [mini-instruct | onnx]
-
License : MIT 许可证
效果演示
观看 Phi-4 Multimodal 如何通过语音分析帮助规划西雅图之旅,展示其先进的音频处理与推荐能力。
视频:https://github.com/nguyenbh/phi4mm-demos/raw/refs/heads/main/clips/Phi-4-multimodal_SeattleTrip.mp4
了解 Phi-4 Multimodal 如何通过视觉输入解决复杂数学问题,展示其图像方程处理与求解能力。
https://github.com/nguyenbh/phi4mm-demos/raw/refs/heads/main/clips/Phi-4-multimodal_Math.mp4
探索 Phi-4 Mini 作为智能代理的功能,展示其在复杂场景中的推理与任务执行能力。
https://github.com/nguyenbh/phi4mm-demos/raw/refs/heads/main/clips/Phi-4-mini_Agents.mp4
二、使用说明
1、Requirements
Phi-4 系列模型已集成在 transformers 的 4.48.2 版本中。可通过以下命令验证当前安装的 transformers 版本:pip list | grep transformers。
建议使用 Python 3.10 运行,所需依赖包示例如下:
flash_attn==2.7.4.post1
torch==2.6.0
transformers==4.48.2
accelerate==1.3.0
soundfile==0.13.1
pillow==11.1.0
scipy==1.15.2
torchvision==0.21.0
backoff==2.2.1
peft==0.13.2
Phi-4-multimodal-instruct 也可在 Azure AI Studio 中使用
2、Tokenizer
Phi-4-multimodal-instruct 支持的最大词汇表大小为 200064 个 token。分词器文件已提供可用于下游微调的占位符 token,但这些 token 也可扩展至模型的最大词汇表容量。
3、输入格式
考虑到训练数据的特性,Phi-4-multimodal-instruct 模型最适合采用如下聊天格式的提示词:
3.1 文本聊天格式
该格式适用于一般对话和指令:
<|system|>You are a helpful assistant.<|end|><|user|>How to explain Internet for a medieval knight?<|end|><|assistant|>
3.2 工具启用的函数调用格式
当用户希望模型基于给定的工具提供函数调用时,会使用此格式。用户应在系统提示中提供可用的工具,并用 <|tool|> 和 <|/tool|> 标记包裹。工具应以 JSON 格式指定,使用 JSON 转储结构。例如:
<|system|>You are a helpful assistant with some tools.<|tool|>[{"name": "get_weather_updates", "description": "Fetches weather updates for a given city using the RapidAPI Weather API.", "parameters": {"city": {"description": "The name of the city for which to retrieve weather information.", "type": "str", "default": "London"}}}]<|/tool|><|end|><|user|>What is the weather like in Paris today?<|end|><|assistant|>
3.3 视觉语言格式
该格式用于带图像的对话场景:
<|user|><|image_1|>Describe the image in detail.<|end|><|assistant|>
若涉及多张图像,用户需在提示词中插入多个图像占位符,如下所示:
<|user|><|image_1|><|image_2|><|image_3|>Summarize the content of the images.<|end|><|assistant|>
3.4 语音语言格式
该格式适用于多种语音和音频任务:
<|user|><|audio_1|>{任务提示}<|end|><|assistant|>
任务提示可根据不同任务而变化。
自动语音识别:
<|user|><|audio_1|>将音频片段转录为文本。<|end|><|assistant|>
自动语音翻译:
<|user|><|audio_1|>将音频翻译为{语言}。<|end|><|assistant|>
带思维链的自动语音翻译:
<|user|><|audio_1|>先将音频转录为文本,再将其翻译为{语言}。使用<sep>作为原始转录和翻译之间的分隔符。<|end|><|assistant|>
语音查询问答:
<|user|><|audio_1|><|end|><|assistant|>
3.5 视觉-语音格式
该格式用于支持图像和音频的对话交互。音频内容可能包含与图像相关的查询:
<|user|><|image_1|><|audio_1|><|end|><|assistant|>
若涉及多张图像,用户需在提示词中插入多个图像占位符,如下所示:
<|user|><|image_1|><|image_2|><|image_3|><|audio_1|><|end|><|assistant|>
视觉部分
- 支持常见RGB/灰度图像格式(如:“.jpg”, “.jpeg”, “.png”, “.ppm”, “.bmp”, “.pgm”, “.tif”, “.tiff”, “.webp”)
- 分辨率取决于GPU显存容量。更高分辨率和更多图像会产生更多token,从而占用更多显存。训练阶段可支持64个图像裁剪区域。若为方形图像,分辨率约为(8448 × 8448)。多图像场景下最多支持64帧,但随着输入帧数增加,需降低单帧分辨率以确保显存容量。
音频部分
- 支持soundfile包能加载的所有音频格式
- 为保持最佳性能,建议音频时长不超过40秒。针对摘要生成任务,建议最大音频时长为30分钟
4、本地加载模型
获取 Phi-4-multimodal-instruct 模型检查点后,用户可以使用此示例代码进行推理。
更多推理示例可在此处查看。
import requests
import torch
import os
import io
from PIL import Image
import soundfile as sf
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from urllib.request import urlopen
# Define model path
model_path = "microsoft/Phi-4-multimodal-instruct"
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
# if you do not use Ampere or later GPUs, change attention to "eager"
_attn_implementation='flash_attention_2',
).cuda()
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
# Define prompt structure
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
# Part 1: Image Processing
print("\n--- IMAGE PROCESSING ---")
image_url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Download and open image
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
# Generate response
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
# Part 2: Audio Processing
print("\n--- AUDIO PROCESSING ---")
audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
speech_prompt = "Transcribe the audio to text, and then translate the audio to French. Use <sep> as a separator between the original transcript and the translation."
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Downlowd and open audio file
audio, samplerate = sf.read(io.BytesIO(urlopen(audio_url).read()))
# Process with the model
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
5、vLLM 推理
用户可以通过以下命令启动服务器
python -m vllm.entrypoints.openai.api_server --model 'microsoft/Phi-4-multimodal-instruct' --dtype auto --trust-remote-code --max-model-len 131072 --enable-lora --max-lora-rank 320 --lora-extra-vocab-size 0 --limit-mm-per-prompt audio=3,image=3 --max-loras 2 --lora-modules speech=<path to speech lora folder> vision=<path to vision lora folder>
speech lora和vision lora文件夹位于vLLM下载的Phi-4-multimodal-instruct文件夹内,您也可以使用以下脚本来查找它们:
from huggingface_hub import snapshot_download
model_path = snapshot_download(repo_id="microsoft/Phi-4-multimodal-instruct")
speech_lora_path = model_path+"/speech-lora"
vision_lora_path = model_path+"/vision-lora"
三、训练
1、微调
另附示例说明如何将语音识别扩展至新语言。
2、模型
- 架构: Phi-4-multimodal-instruct 拥有56亿参数,是一个多模态Transformer模型。该模型以预训练的Phi-4-Mini-Instruct作为骨干语言模型,并集成了先进的视觉和语音编码器与适配器。
- 输入: 支持文本、图像和音频输入,最适合采用聊天格式的提示词。
- 上下文长度: 128K tokens
- GPU配置: 512张A100-80G显卡
- 训练时长: 28天
- 训练数据: 包含5万亿文本token、230万小时语音数据及1.1万亿图文配对token
- 输出: 根据输入生成响应文本
- 训练周期: 2024年12月至2025年1月
- 状态: 这是一个基于离线数据集训练的静态模型,公开数据的截止日期为2024年6月。
- 支持语言:
- 文本:阿拉伯语、中文、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、德语、希伯来语、匈牙利语、意大利语、日语、韩语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、瑞典语、泰语、土耳其语、乌克兰语
- 视觉:英语
- 语音:英语、中文、德语、法语、意大利语、日语、西班牙语、葡萄牙语
- 发布日期: 2025年2月
3、训练数据集
Phi-4-multimodal-instruct 的训练数据包含多种来源,总计 5 万亿文本 token,具体包括以下内容:
1、经过质量筛选的公开文档、精选的高质量教育数据及代码
2、为教授数学、编程、常识推理和世界通用知识(如科学、日常活动、心理理论等)而新创建的合成“教科书式”数据
3、聊天格式的高质量人工标注数据
4、精选的高质量图文交错数据
5、合成及公开的图像、多图像和视频数据
6、经过匿名化处理的内部语音-文本配对数据(含强/弱转录版本)
7、精选的公开高质量语音数据及带任务特定监督的匿名化内部语音数据
8、精选的合成语音数据
9、合成的视觉-语音数据
数据筛选的重点是可能提升模型推理能力的优质内容,公开文档经过过滤以保留符合知识水平要求的部分。例如,英超联赛某日赛果虽可作为大基座模型的训练数据,但这类信息会从 Phi-4-multimodal-instruct 数据中剔除,以便为小尺寸模型保留更多推理能力。数据收集过程涉及从公开文档中提取信息,并重点过滤不良文档和图像。为保护隐私,图像和文本数据源经过处理,移除了训练数据中可能包含的个人信息。
去污染流程包括对数据集进行标准化和分词处理,生成目标数据集与基准数据集的 n-gram 并进行比对。匹配率超过阈值的样本会被标记为污染数据并从数据集中移除。最终生成详细的污染报告,汇总匹配文本、匹配比例及过滤结果以供进一步分析。
4、软件
5、硬件要求
请注意,Phi-4-multimodal-instruct 模型默认使用 flash attention 机制,这需要特定类型的 GPU 硬件才能运行。我们已在以下 GPU 型号上完成测试:
- NVIDIA A100
- NVIDIA A6000
- NVIDIA H100
若您需要在以下设备上运行该模型:
- NVIDIA V100 或更早代际的 GPU:调用
AutoModelForCausalLM.from_pretrained()时需传入参数_attn_implementation="eager"
四、预期用途
1、主要应用场景
该模型旨在广泛支持多语言和多模态的商业及研究用途。它为需要以下功能的通用人工智能系统和应用提供支持:
1、内存/计算受限环境
2、延迟敏感场景
3、强推理能力(特别是数学与逻辑)
4、函数与工具调用
5、通用图像理解
6、光学字符识别
7、图表与表格理解
8、多图像对比
9、多图像或视频片段摘要
10、语音识别
11、语音翻译
12、语音问答
13、语音摘要
14、音频理解
该模型旨在加速语言和多模态模型的研究,作为生成式AI功能的基础构建模块。
2、使用场景考量
该模型并非针对所有下游用途专门设计或评估。开发者在选择使用场景时,应考虑语言模型和多模态模型的常见限制,以及跨语言性能差异,并在特定下游场景(尤其是高风险场景)中使用前,评估并提升准确性、安全性和公平性。
开发者应了解并遵守与其使用场景相关的适用法律法规(包括但不限于隐私、贸易合规法律等)。
本模型卡中的任何内容均不应被解释为对模型发布所依据许可协议的限制或修改。
五、版本说明
本次发布的Phi-4多模态指令模型基于Phi-3系列获得的宝贵用户反馈。此前用户需通过语音识别模型与Mini和Vision模型交互,这要求使用由两个模型组成的处理流程:一个模型将音频转写为文本,另一个模型处理语言或视觉任务。这种流程意味着核心模型无法获取完整的输入信息——例如无法直接感知多说话者、背景噪音,也无法在统一表征空间中同时对齐语音、视觉和语言信息。
Phi-4多模态指令模型通过单个开源模型实现了对文本、视觉和音频的联合训练,所有输入输出均由同一神经网络处理。该模型采用新架构,扩展了高效词汇表,支持多语言和多模态,并运用更优的后训练技术来提升指令跟随和函数调用能力。额外训练数据也使其关键多模态能力获得显著提升。
我们预计Phi-4多模态指令模型将为应用开发者和各类使用场景带来重要价值。感谢大家对Phi-4系列的热情支持,您的反馈对模型演进至关重要。感谢您参与这段旅程!
六、模型质量
点击查看详情
为了评估模型能力,我们使用内部基准测试平台(基准方法详见附录A)将Phi-4-multimodal-instruct与多个模型在各类基准上进行了对比。语言基准测试的详细结果可参考Phi-4-Mini-Instruct模型卡片。以下是该模型在代表性语音和视觉基准测试中的整体质量概览:
1、语音能力
Phi-4多模态指令模型展现出以下语音特性:
- 具备强大的自动语音识别(ASR)和语音翻译(ST)性能,超越专业ASR模型WhisperV3和ST模型SeamlessM4T-v2-Large
- 以6.14%的词错率位居Huggingface OpenASR排行榜首位(截至2025年3月4日,当前最佳模型成绩为6.5%)
- 作为首个开源语音摘要模型,其性能接近GPT4o水平
- 在语音问答任务上与Gemini-1.5-Flash、GPT-4o实时预览版等竞品存在差距,团队正在后续迭代中提升该能力
1.1 语音识别(数值越低越好)
Phi-4-multimodal-instruct 在聚合基准数据集上的表现:
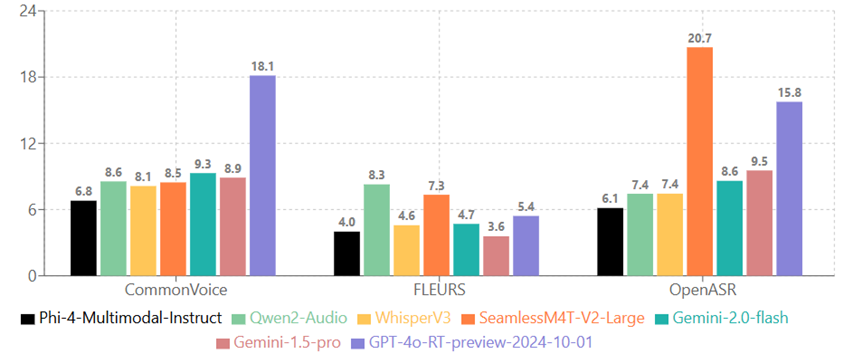
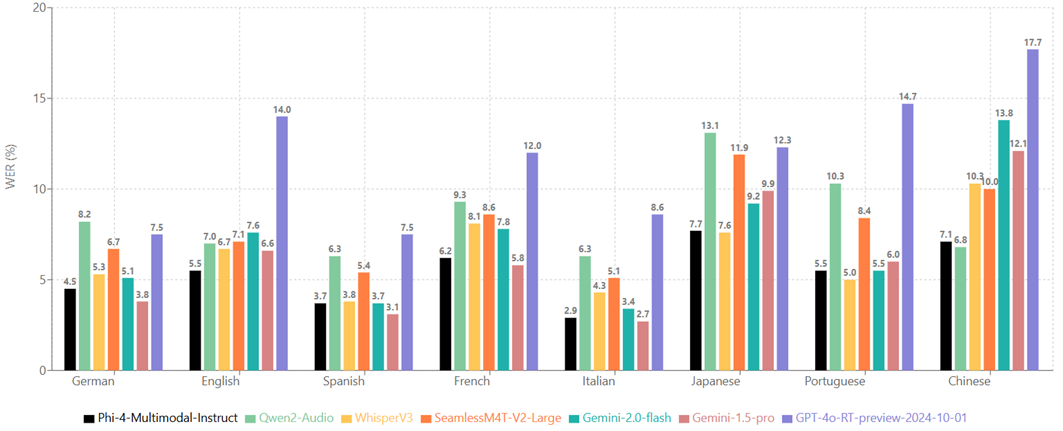
Phi-4-multimodal-instruct 在不同语言上的表现(取 CommonVoice 和 FLEURS 的 WER 平均值):
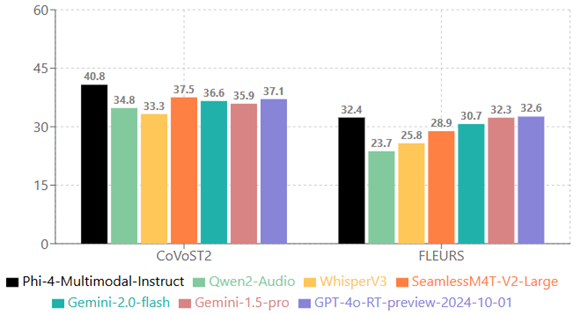
1.2 语音翻译(数值越高越好)
从德语、西班牙语、法语、意大利语、日语、葡萄牙语、中文翻译为英语:
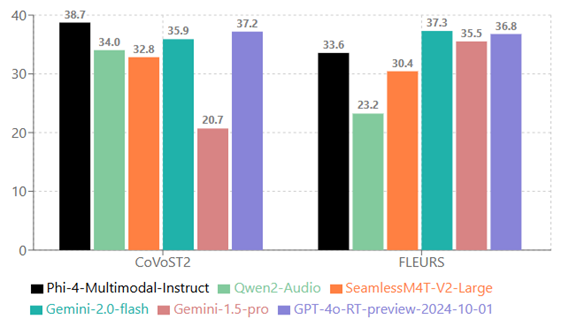
从英语翻译为德语、西班牙语、法语、意大利语、日语、葡萄牙语、中文。请注意WhisperV3不支持此功能:
1.3 语音摘要(数值越高越好)
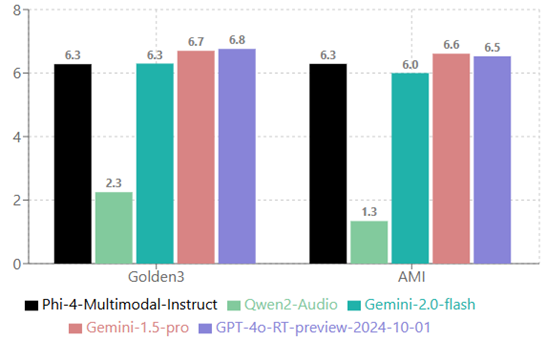
1.4 语音问答
MT bench 分数已放大 10 倍以匹配 MMMLU 的分数范围:
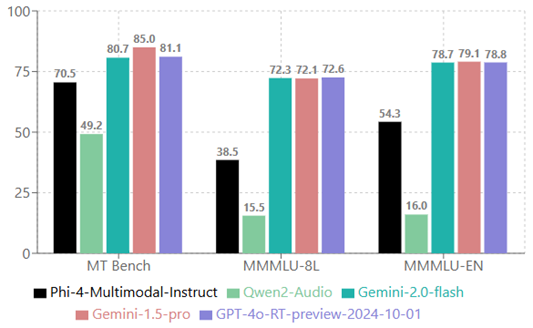
1.5 音频理解
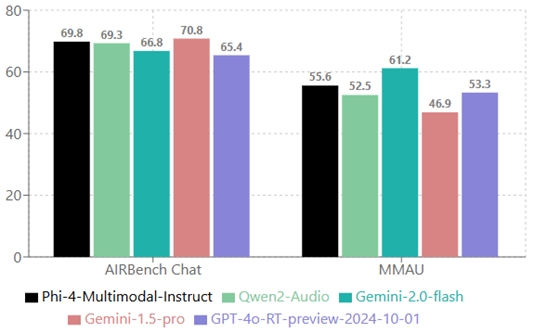
AIR bench 分数经过10倍缩放以匹配MMAU的评分范围:
2、视觉
2.1 视觉-语音任务
Phi-4-multimodal-instruct 能够同时处理图像和音频输入。下表展示了当视觉内容查询采用合成语音时,该模型在图表/表格理解和文档推理任务上的表现质量。与其他支持音频和视觉信号输入的现有全能模型相比,Phi-4-multimodal-instruct 在多项基准测试中均展现出显著优势。
| 基准测试 | Phi-4-multimodal-instruct | InternOmni-7B | Gemini-2.0-Flash-Lite-prv-02-05 | Gemini-2.0-Flash | Gemini-1.5-Pro |
|---|---|---|---|---|---|
| s_AI2D | 68.9 | 53.9 | 62.0 | 69.4 | 67.7 |
| s_ChartQA | 69.0 | 56.1 | 35.5 | 51.3 | 46.9 |
| s_DocVQA | 87.3 | 79.9 | 76.0 | 80.3 | 78.2 |
| s_InfoVQA | 63.7 | 60.3 | 59.4 | 63.6 | 66.1 |
| 平均分 | 72.2 | 62.6 | 58.2 | 66.2 | 64.7 |
2.2 视觉任务
为了评估Phi-4-multimodal-instruct的视觉能力,我们使用内部基准平台将其与多款模型在零样本基准测试上进行了对比。以下是该模型在代表性基准测试中的高质量表现概览:
| 数据集 | Phi-4-multimodal-ins | Phi-3.5-vision-ins | Qwen 2.5-VL-3B-ins | Intern VL 2.5-4B | Qwen 2.5-VL-7B-ins | Intern VL 2.5-8B | Gemini 2.0-Flash Lite-preview-0205 | Gemini2.0-Flash | Claude-3.5-Sonnet-2024-10-22 | Gpt-4o-2024-11-20 |
|---|---|---|---|---|---|---|---|---|---|---|
| 热门综合基准 | ||||||||||
| MMMU | 55.1 | 43.0 | 47.0 | 48.3 | 51.8 | 50.6 | 54.1 | 64.7 | 55.8 | 61.7 |
| MMBench (dev-en) | 86.7 | 81.9 | 84.3 | 86.8 | 87.8 | 88.2 | 85.0 | 90.0 | 86.7 | 89.0 |
| MMMU-Pro (std/vision) | 38.5 | 21.8 | 29.9 | 32.4 | 36.9 | 34.4 | 45.1 | 54.4 | 54.3 | 53.0 |
| 视觉科学推理 | ||||||||||
| ScienceQA Visual (img-test) | 97.5 | 91.3 | 79.4 | 96.2 | 87.7 | 97.3 | 85.0 | 88.3 | 81.2 | 88.2 |
| 视觉数学推理 | ||||||||||
| MathVista (testmini) | 62.4 | 43.9 | 60.8 | 51.2 | 67.8 | 56.7 | 57.6 | 47.2 | 56.9 | 56.1 |
| InterGPS | 48.6 | 36.3 | 48.3 | 53.7 | 52.7 | 54.1 | 57.9 | 65.4 | 47.1 | 49.1 |
| 图表与表格推理 | ||||||||||
| AI2D | 82.3 | 78.1 | 78.4 | 80.0 | 82.6 | 83.0 | 77.6 | 82.1 | 70.6 | 83.8 |
| ChartQA | 81.4 | 81.8 | 80.0 | 79.1 | 85.0 | 81.0 | 73.0 | 79.0 | 78.4 | 75.1 |
| DocVQA | 93.2 | 69.3 | 93.9 | 91.6 | 95.7 | 93.0 | 91.2 | 92.1 | 95.2 | 90.9 |
| InfoVQA | 72.7 | 36.6 | 77.1 | 72.1 | 82.6 | 77.6 | 73.0 | 77.8 | 74.3 | 71.9 |
| 文档智能 | ||||||||||
| TextVQA (val) | 75.6 | 72.0 | 76.8 | 70.9 | 77.7 | 74.8 | 72.9 | 74.4 | 58.6 | 73.1 |
| OCR Bench | 84.4 | 63.8 | 82.2 | 71.6 | 87.7 | 74.8 | 75.7 | 81.0 | 77.0 | 77.7 |
| 物体视觉存在验证 | ||||||||||
| POPE | 85.6 | 86.1 | 87.9 | 89.4 | 87.5 | 89.1 | 87.5 | 88.0 | 82.6 | 86.5 |
| 多图像感知 | ||||||||||
| BLINK | 61.3 | 57.0 | 48.1 | 51.2 | 55.3 | 52.5 | 59.3 | 64.0 | 56.9 | 62.4 |
| Video MME 16 frames | 55.0 | 50.8 | 56.5 | 57.3 | 58.2 | 58.7 | 58.8 | 65.5 | 60.2 | 68.2 |
| 平均分 | 72.0 | 60.9 | 68.7 | 68.8 | 73.1 | 71.1 | 70.2 | 74.3 | 69.1 | 72.4 |
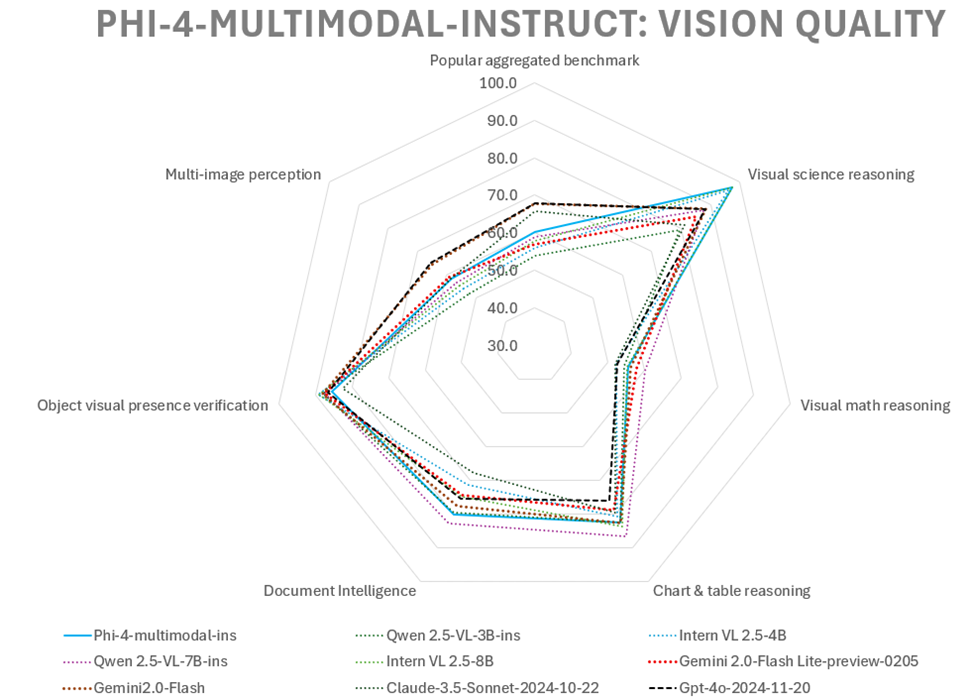
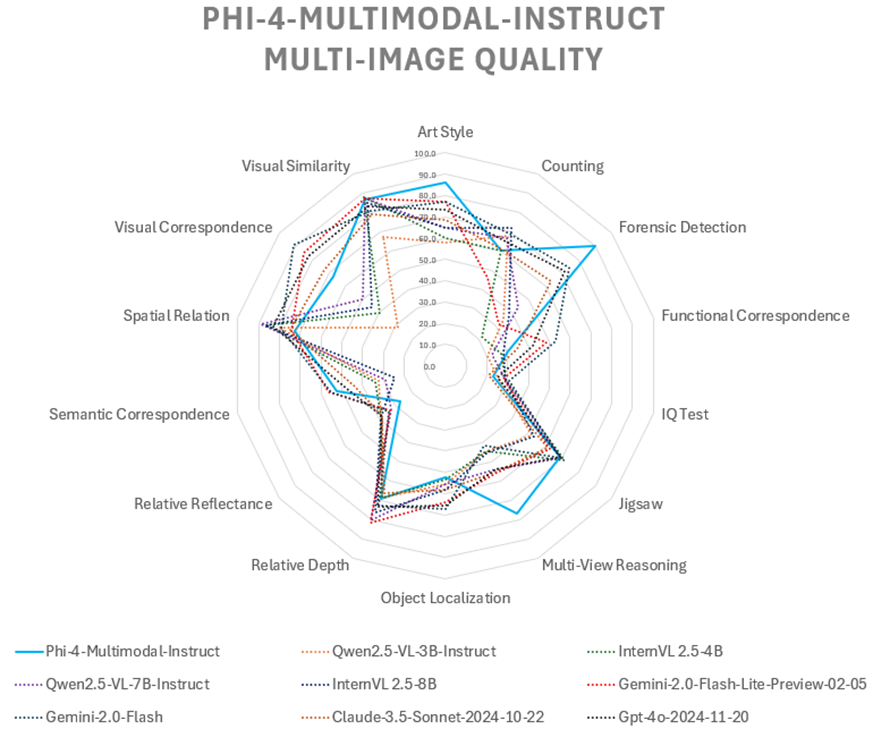
2.3 视觉感知能力
以下是现有多图像任务的对比结果。平均而言,Phi-4-multimodal-instruct 在同等规模模型中表现最优,其多帧处理能力甚至可与更大规模的模型媲美。BLINK 是一个包含14项视觉任务的综合基准测试,这些任务对人类而言能快速解决,但对当前多模态大语言模型仍具挑战性。
| 数据集 | Phi-4-multimodal-instruct | Qwen2.5-VL-3B-Instruct | InternVL 2.5-4B | Qwen2.5-VL-7B-Instruct | InternVL 2.5-8B | Gemini-2.0-Flash-Lite-prv-02-05 | Gemini-2.0-Flash | Claude-3.5-Sonnet-2024-10-22 | Gpt-4o-2024-11-20 |
|---|---|---|---|---|---|---|---|---|---|
| 艺术风格 | 86.3 | 58.1 | 59.8 | 65.0 | 65.0 | 76.9 | 76.9 | 68.4 | 73.5 |
| 计数 | 60.0 | 67.5 | 60.0 | 66.7 | 71.7 | 45.8 | 69.2 | 60.8 | 65.0 |
| 取证检测 | 90.2 | 34.8 | 22.0 | 43.9 | 37.9 | 31.8 | 74.2 | 63.6 | 71.2 |
| 功能对应 | 30.0 | 20.0 | 26.9 | 22.3 | 27.7 | 48.5 | 53.1 | 34.6 | 42.3 |
| 智商测试 | 22.7 | 25.3 | 28.7 | 28.7 | 28.7 | 28.0 | 30.7 | 20.7 | 25.3 |
| 拼图 | 68.7 | 52.0 | 71.3 | 69.3 | 53.3 | 62.7 | 69.3 | 61.3 | 68.7 |
| 多视角推理 | 76.7 | 44.4 | 44.4 | 54.1 | 45.1 | 55.6 | 41.4 | 54.9 | 54.1 |
| 物体定位 | 52.5 | 55.7 | 53.3 | 55.7 | 58.2 | 63.9 | 67.2 | 58.2 | 65.6 |
| 相对深度 | 69.4 | 68.5 | 68.5 | 80.6 | 76.6 | 81.5 | 72.6 | 66.1 | 73.4 |
| 相对反射率 | 26.9 | 38.8 | 38.8 | 32.8 | 38.8 | 33.6 | 34.3 | 38.1 | 38.1 |
| 语义对应 | 52.5 | 32.4 | 33.8 | 28.8 | 24.5 | 56.1 | 55.4 | 43.9 | 47.5 |
| 空间关系 | 72.7 | 80.4 | 86.0 | 88.8 | 86.7 | 74.1 | 79.0 | 74.8 | 83.2 |
| 视觉对应 | 67.4 | 28.5 | 39.5 | 50.0 | 44.2 | 84.9 | 91.3 | 72.7 | 82.6 |
| 视觉相似度 | 86.7 | 67.4 | 88.1 | 87.4 | 85.2 | 87.4 | 80.7 | 79.3 | 83.0 |
| 综合得分 | 61.6 | 48.1 | 51.2 | 55.3 | 52.5 | 59.3 | 64.0 | 56.9 | 62.4 |
七、负责任的人工智能考量
与其他语言模型类似,Phi系列模型可能表现出不公平、不可靠或冒犯性的行为。需要特别注意的局限性包括:
-
服务质量:Phi模型主要基于英语文本、语音和视觉内容进行训练,并包含部分多语言覆盖。不同模态和语言间的性能表现可能存在显著差异:
- 文本:非英语语言的性能会降低,不同非英语语言的性能下降程度各异。训练数据中代表性较少的英语变体可能表现不如标准美式英语。
- 语音:语音识别和处理呈现类似的语言性能模式,标准美式英语口音和发音表现最优。其他英语口音、方言及非英语语言的识别准确率和响应质量可能较低。背景噪音、音频质量和语速会进一步影响性能。
- 视觉:视觉处理能力可能受训练数据中文化和地理偏见的影响。当分析包含非英语文本或非西方常见视觉元素的图像时,模型表现可能下降。图像质量、光照条件和构图也会影响处理准确性。
-
多语言性能与安全缺陷:我们认为扩大语言模型的多语言覆盖很重要,但Phi 4模型仍存在多语言版本的常见问题。与所有大语言模型部署类似,开发者需针对自身语言文化背景测试性能或安全缺陷,并通过额外微调和适当保障措施定制模型。
-
伤害表征与刻板印象延续:这些模型可能过度或不足表征某些群体、抹除部分群体的存在,或强化贬损性/负面刻板印象。尽管经过安全后训练,由于不同群体的表征差异、文化背景或训练数据中反映现实世界偏见的内容,这些局限仍可能存在。
-
不当或冒犯性内容:模型可能生成其他类型的不当内容,若未针对具体场景采取缓解措施,可能不适用于敏感场景的部署。
-
信息可靠性:语言模型可能生成无意义内容,或编造看似合理实则错误或过时的信息。
-
代码范围限制:Phi 4训练数据主要基于Python,使用常见包如"typing, math, random, collections, datetime, itertools"。若模型生成使用其他包或其他语言的脚本,强烈建议用户手动验证所有API调用。
-
长对话限制:与其他模型类似,Phi 4在超长英文或非英文对话中可能生成重复、无帮助或不一致的响应。建议开发者实施缓解措施(如限制对话轮次)以应对可能的对话偏离。
-
敏感属性推断:Phi 4模型在被明确要求时,可能尝试从用户语音推断敏感属性(如性格特征、国籍、性别等)。Phi 4-multimodal-instruct并非设计用于通过生物特征数据推断种族、政治观点、宗教信仰等信息的生物识别分类系统。通过系统消息可在应用层有效缓解此行为。
开发者应遵循负责任AI实践,包括针对具体用例和文化语言环境进行风险映射、评估和缓解。Phi 4系列是通用模型,建议开发者在特定用例中微调模型,并将其作为配备语言特定保障措施的更广泛AI系统的一部分。关键考量领域包括:
- 资源分配:未经进一步评估和去偏技术处理,模型可能不适用于影响法律地位或资源/人生机会分配的场景(如住房、就业、信贷等)。
- 高风险场景:需评估模型在输出不公/不可靠可能导致严重后果的场景中的适用性,包括对准确性要求高的专业领域建议(如法律或医疗)。应根据部署环境在应用层实施额外保障。
- 错误信息:模型可能生成不准确信息。开发者应遵循透明度实践,告知终端用户正在与AI系统交互,并通过检索增强生成(RAG)等技术建立反馈机制。
- 有害内容生成:开发者应根据上下文评估输出,并采用适合用例的安全分类器或定制方案。
- 滥用防范:需防范欺诈、垃圾信息或恶意软件制作等滥用形式,确保应用符合法律法规。
八、安全性
Phi-4系列模型采用了强大的安全后训练方法。该方法结合了开源数据集和内部生成数据集,通过监督微调(SFT)、直接偏好优化(DPO)以及基于人类反馈的强化学习(RLHF)等技术实现安全对齐。训练使用了人工标注和合成的英语数据集,包括公开可用的帮助性与无害性数据集,以及针对多类安全问题的问答数据。对于非英语语种,通过机器翻译扩展了现有数据集。语音安全数据集是通过将文本安全数据集输入Azure文本转语音(TTS)服务生成的,涵盖英语和非英语语种。此外还创建了视觉(文本&图像)安全数据集,覆盖公共及内部多模态RAI数据集中识别的危害类别。
1、安全评估与红队测试
我们采用了多种评估技术,包括红队测试、对抗性对话模拟以及多语言安全评估基准数据集,以评估Phi-4模型在多种语言和风险类别中产生不良输出的倾向。通过结合多种方法,弥补了单一方法的局限性。各项评估方法的结果表明,如Phi 3安全后训练论文所述的安全后训练措施,通过拒绝率(拒绝输出不良内容)和对越狱技术的鲁棒性观察,对多语言和多风险类别产生了积极影响。关于Phi系列模型历史红队测试的详细信息,可参阅Phi 3安全后训练论文。
本次发布中,红队测试重点针对新增的音频输入模态及以下安全领域:有害内容、自残风险和漏洞利用。研究发现,当遭受上下文操纵或说服性技术攻击时,模型更容易产生不良输出。这一现象在所有语言中均存在,其中说服性技术对法语和意大利语的影响尤为显著。这凸显了行业需要加大对高质量多语言安全评估数据集开发的投入,包括资源稀缺语言,以及考虑语言使用地区文化差异的风险领域。
2、视觉安全评估
为评估模型在涉及文本和图像场景中的安全性,我们采用了微软Azure AI评估SDK。该工具通过提供旨在引发有害响应的提示文本和图像,可模拟与目标模型的单轮对话。随后由能力较强的模型对目标模型的响应进行多维度评估,涵盖暴力、色情内容、自残、仇恨与不公内容等危害类别,并根据识别到的危害严重程度对每个响应进行评分。评估结果与Phi-3.5-Vision及同等规模的开源模型进行了对比。此外,我们还运行了内部及公开的RTVLM和VLGuard多模态(文本&视觉)RAI基准测试,再次将得分与Phi-3.5-Vision及同类规模开源模型进行对比。需注意,该模型可能对特定语言攻击提示和文化语境较为敏感。
3、音频安全评估
除进行大量红队测试外,我们还通过三项独立评估来验证模型的安全性。首先,与文本和视觉输入评估类似,我们利用微软Azure AI评估SDK检测模型对语音提示的响应中是否存在有害内容。其次,运行微软语音公平性评估以验证语音转文字功能在不同人口统计特征中的表现。第三,我们提出并通过系统消息的缓解方案进行评估,该方案可防止模型从用户声音中推断敏感属性(如性别、性取向、职业、健康状况等)。
九、其它
商标声明
本项目可能包含项目、产品或服务的商标或标识。经授权使用微软商标或标识时,必须遵守微软商标与品牌指南的规定。在本项目修改版本中使用微软商标或标识时,不得造成混淆或暗示微软的赞助。任何第三方商标或标识的使用均受该第三方政策约束。
注意事项
请注意,该模型仅用于概念验证/实验目的,不适用于生产环境。需要更多高质量数据、调优、消融研究和实验验证。
Phi-4多模态模型在多模态任务中表现优异,尤其在语音转文本任务上具有优势,且在韩语任务中展现出巨大潜力。因此,如果您对韩语语音转文本任务感兴趣,该模型可以作为一个良好的起点。
参考文献
- https://huggingface.co/microsoft/Phi-4-multimodal-instruct
- https://huggingface.co/seastar105/Phi-4-mm-inst-zeroth-kor
附录 A:基准测试方法
我们在此简要说明基准测试方法,特别是关于如何优化提示的设计思路。
理想情况下,基准测试中应保持所有提示不变,以确保不同模型之间的对比始终基于相同条件。这确实是我们的默认原则,目前运行的绝大多数模型均采用此方法。
但存在以下例外情况:
- 当模型因输出格式问题导致评估表现异常时(例如无故拒绝回答问题,或在代码任务中添加无关前缀如"Sure, I can help with that…“导致解析失败),我们会尝试调整系统消息(如改为"必须回答所有问题"或"直接给出答案”)。
- 当少量示例(few-shot)反而降低模型性能时,允许在所有测试案例中使用零示例(0-shot)模式运行基准测试。
- 在聊天API与补全API转换场景中,针对不同模型的关键词差异(如Human与User),允许建立模型专用的提示映射规则。
我们始终坚持以下原则:
- 对比不同模型时,保持少量示例内容完全一致
- 不更改提示基础格式(如选择题选项保持A/B/C/D形式,不会改为1/2/3/4)
1、视觉基准测试设置
本基准测试的目标是衡量当普通用户使用这些模型处理涉及视觉输入的任务时,LMM的性能表现。为此,我们选取了9个流行且公开可用的单帧数据集和3个多帧基准测试,这些数据集覆盖了数学、OCR任务、图表理解等多种具有挑战性的主题和任务,同时选用了一组高质量模型。
我们的基准测试采用零样本提示方法,所有模型的提示内容保持一致。我们仅对提示内容进行格式化以适应各模型的提示API要求,从而确保评估过程在测试模型间的公平性。许多基准测试要求模型从给定的选项列表中选择响应,因此我们在提示结尾添加了指令,引导所有模型选择与其认为正确答案对应的选项字母。
在视觉输入方面,我们直接使用原始数据集提供的基准测试图像。对于需要特定格式的模型(如GPTV、Claude Sonnet 3.5、Gemini 1.5 Pro/Flash),我们通过JPEG编码将这些图像转换为base-64格式。对于其他模型(如Llava Interleave、InternVL2 4B和8B),我们通过其Huggingface接口传入PIL图像或本地存储的JPEG图像。所有图像均未进行缩放或其他预处理。
最后,我们使用相同的代码提取答案,并采用统一的评估代码对所有测试模型进行评判,以此保证答案质量评估的公正性。
2、语音基准测试设置
本次基准测试的目标是评估模型在普通用户使用的语音和音频理解任务中的性能表现。为实现这一目标,我们选取了多个最先进的开源和闭源模型,并在各类公开及内部基准测试上进行了评估。这些基准测试涵盖多样且具有挑战性的主题,包括自动语音识别(ASR)、自动语音翻译(AST)、口语查询问答(SQQA)、音频理解(AU)以及语音摘要。
所有结果均基于相同测试数据的评估得出,未进行额外说明。在推理过程中未采用任何采样方法。为确保比较的准确性,我们对不同任务的模型使用了一致的提示词,但某些模型API(如GPT-4o)可能会拒绝响应特定任务的提示词。
最终,我们采用统一的代码提取答案并进行评估。这种方法通过评估模型响应质量确保了测试的公平性。
3、基准测试数据集
该模型在广泛的公开及内部基准测试中进行了评估,以了解其在多种任务和条件下的能力。虽然大多数评估使用英语,但也纳入了多语言基准测试来覆盖选定语言的性能表现。具体而言,
4、愿景:
-
主流综合基准测试:
- MMMU 和 MMMU-Pro:面向大学学科知识与深度推理的大规模多学科任务。
- MMBench:评估感知与推理能力的大规模基准测试。
-
视觉推理:
- ScienceQA:基于科学的多模态视觉问答。
- MathVista:视觉数学推理。
- InterGPS:二维几何视觉推理。
-
图表推理:
- ChartQA:针对图表的视觉与逻辑推理。
- AI2D:图表理解。
-
文档智能:
- TextVQA:读取并推理图像中的文本以回答问题。
- InfoVQA:读取并推理任意长宽比的高清信息图。
- DocVQA:读取并推理密集文本及手写文档图像。
- OCRBench:测试多样化文本相关图像的OCR与问答能力。
-
视觉语音多模态理解:
- s_AI2D:以语音提问的图表理解。
- s_ChartQA:以语音提问的图表视觉与逻辑推理。
- s_InfoVQA:以语音提问的高清信息图读取与推理。
- s_DocVQA:以语音提问的密集文本及手写文档图像推理。
-
负责任AI与安全基准:
- VLGuardExt:VLGuard是面向模型安全的视觉语言指令跟随公共数据集,涵盖欺骗鉴别、隐私及风险行为(建议、性、暴力、政治)等领域的安全问题。该数据集已扩展至儿童安全、选举关键信息等内部类别。
- RTVLM:针对视觉语言模型红队的公开基准,测试模型真实性、隐私性、安全性与公平性。
- GPTV-RAI:Azure AI发布的GPT-4V内部基准,测量有害性(如性、暴力、仇恨与自残)、隐私性、越狱及错误信息。
5、语音数据集:
- CommonVoice v15 是由 Mozilla 开发的开源多语言语音数据集,包含全球志愿者贡献并验证的 133 种语言、超过 33,000 小时的语音数据。评估在支持的八种语言中进行。
- Hugging Face 的 OpenASR 排行榜 专为英语自动语音识别(ASR)模型的鲁棒性基准测试而设计,涵盖朗读、对话、会议等多种语音领域。
- CoVoST2 是基于 Mozilla Common Voice 项目的多语言语音转文本翻译数据集,是当前最大的开源语音翻译数据集之一,支持 X→英语(X→En)和英语→X(En→X)的双向翻译任务。测试集评估了支持语言方向的性能。
- FLEURS 是多语言语音数据集,用于评估语音识别和语音转文本翻译模型在广泛语言中的表现。语音识别和翻译任务的测试集均以八种支持语言进行评估。
- MT Bench(多轮对话基准) 专注于评估 AI 模型在多轮问答(QA)场景中的对话和指令跟随能力。为支持语音提问,文本会被合成为语音。
- MMMLU(多语言大规模多任务语言理解) 是评估 AI 模型跨学科通用知识和推理能力的综合基准。为支持语音提问,文本会被合成为对应语音。本测试集在八种支持语言上评估模型表现。
- AIR-Bench Chat(音频指令与响应基准) 是测试大型音频语言模型(LALM)能力的综合框架,包含基础基准和对话基准。对话基准因其开放式音频问答能力被选用。
- MMAU(大规模多任务音频理解) 是评估多模态模型在音频理解和推理任务中能力的综合数据集,测试集以多选题形式覆盖音乐、声音和语音类别。
- Golden3 是真实会议数据集,包含 108 段平均时长 6 分钟的会议录音及转录文本,采集自 30 个会议室,每场会议 4-8 人参与。数据集以英语为主,涵盖广泛主题,使用 GPT4 生成控制输出风格/长度/结构的摘要指令。
- AMI(增强多方交互) 是包含约 100 小时会议录音的综合数据集,测试集含 20 段平均 32 分钟的会议录音。模型测试采用近距离麦克风版本音频,使用 GPT4 生成控制摘要输出的指令。
(注:所有代码、专有名词及数据集名称均按核心翻译原则保留原格式)
6、安全性与负责任AI(RAI):
- 单轮可信度评估:
- DecodingTrust:一套涵盖八个不同维度的可信度基准测试集
- XSTest:采用极端场景的安全压力测试
- Toxigen:对抗性仇恨言论检测工具
- 红队测试:
- 对微软AI红队提供的提示词响应测试
(注:严格保留所有代码/项目名称原文,技术术语采用行业通用译法,被动语态转为主动表述,长句按中文习惯拆分)
附录 B:韩语语音微调
1、概述与数据集
Phi-4-multimodal 最初并非为韩语语音转文本任务设计,但可以通过自有数据或公开韩语语音数据集进行微调以适配该任务。
我们使用以下数据集对 Phi-4-multimodal 模型进行了韩语语音转文本任务的微调:
- kresnik/zeroth_korean
- mozilla-foundation/common_voice_17_0(仅使用韩语语音部分)
- PolyAI/minds14(仅使用韩语语音部分)
- 自定义数据集。该语音数据混合了快慢语速(包含作者发布的技术博客内容和演讲录音),并通过 audiomentations 和 此脚本 进行了部分调制
总计 35K 样本。每个样本均为韩语语音及其对应文本转录的组合,数据集采样率为 16kHz。
您可在此处下载微调后的模型:下载链接。请参考 演示文件夹 中的 Jupyter notebook 和视频片段。这些仅为概念验证目的进行的简易微调,未达到生产级质量,但您可以看到即使母语者语速较快时,模型仍能实现高准确率的转录和翻译。
2、requirements
基于 Python 3.10 环境,需要安装以下软件包,并推荐使用 A100/H100 GPU 显卡。
torch==2.6.0
transformers==4.48.2
accelerate==1.4.0
soundfile==0.13.1
pillow==11.1.0
scipy==1.15.2
torchvision==0.21.0
backoff==2.2.1
peft==0.14.0
datasets==3.3.2
pandas==2.2.3
flash_attn==2.7.4.post1
evaluate==0.4.3
sacrebleu==2.5.1
3、训练过程
该模型在单块A100 80GB GPU上进行了4个周期的训练,批量大小为16,使用的是microsoft/Phi-4-multimodal-instruct仓库中的sample_finetune_speech.py脚本。
微调脚本和命令行参数基本与此处示例相同,但需要自行准备数据集。如需解除音频编码器冻结,请参考以下代码片段。该代码片段取自微调Colab笔记本。
with accelerator.local_main_process_first():
processor = AutoProcessor.from_pretrained(
"microsoft/Phi-4-multimodal-instruct",
trust_remote_code=True,
)
model = create_model(
args.model_name_or_path,
use_flash_attention=args.use_flash_attention,
)
def unfreeze_speech_components(model):
"""Directly target verified components from your debug logs"""
# 1、Audio Embed Module (confirmed exists)
audio_embed = model.model.embed_tokens_extend.audio_embed
# 2、Entire Audio Encoder (simplified)
audio_encoder = audio_embed.encoder # Direct access
# 3、Audio Projection (from debug logs)
audio_projection = audio_embed.audio_projection
# Unfreeze ONLY these 3 components
for component in [audio_embed, audio_encoder, audio_projection]:
for param in component.parameters():
param.requires_grad = True
return model
model = unfreeze_speech_components(model)
# Verify unfrozen parameters
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Trainable parameters: {trainable_params:,}")
# After unfreezing
encoder_params = list(model.model.embed_tokens_extend.audio_embed.encoder.parameters())
proj_params = list(model.model.embed_tokens_extend.audio_embed.audio_projection.parameters())
assert any(p.requires_grad for p in encoder_params), "Encoder params frozen!"
assert any(p.requires_grad for p in proj_params), "Projection params frozen!"
print("Components properly unfrozen ✅")
运行微调脚本的示例命令如下:
python main.py
当前上传的最新模型版本通过解冻音频编码器进行了微调,与基于LoRA适配器的基线微调相比,ASR性能显著提升。
对比全量微调与LoRA微调的结果:在zeroth测试集上,CER分别为1.61% 和 2.72%,WER分别为 3.54% 和7.19%。更多细节请参阅实验设置与结果。
4、实验设置与结果
本次基准测试旨在评估韩语音频在语音和音频理解任务中的基础性能。我们针对自动语音识别(ASR)和自动语音翻译(AST)进行了测试,使用的数据集和样本如下:
评估采用以下数据集:
- ASR(自动语音识别):使用zeroth测试集(457个样本)评估CER(字符错误率)和WER(词错误率)
- AST(自动语音翻译):使用fleurs韩英语音翻译测试集(270个样本)评估BLEU分数
评估脚本来自此处
我们选择Phi-4-mm-inst-zeroth-kor作为性能提升的基线模型,因其在1个epoch训练后即展现显著改进。该基线模型使用22K条Zeroth韩语语音数据训练1个epoch。基于这个35K训练样本的基线,我们进行了以下场景的对比实验:
- [案例1] LoRA微调(1个epoch):基于LoRA适配器微调1个epoch
- [案例2] LoRA微调(4个epoch):基于LoRA适配器微调4个epoch
- [案例3] 解冻音频编码器微调(4个epoch):完整模型微调4个epoch
实验结果如下:
-
zeroth测试集的CER和WER(数值越低越好)
- 案例1的CER和WER分别为3.80%和11.52%,优于基线(7.02%和17.31%)
- 案例2的CER和WER分别为2.72%和7.19%,优于案例1
- 案例3的CER和WER分别为1.61%和3.54%,是所有方案中最优的
-
fleurs韩英语音翻译测试集的BLEU分数(数值越高越好)
- 案例1相比基线没有提升,特别是fleurs-ko2en-cot的BLEU分数低于基线
- 案例2相比案例1略有提升,是所有方案中最优的
- 案例3相比基线和案例2没有提升
| 模型 | zeroth(CER) | zeroth(WER) | fleurs-ko2en | fleurs-ko2en-cot | fleurs-en2ko | fleurs-en2ko-cot |
|---|---|---|---|---|---|---|
| original | 99.16 | 99.63 | 5.63 | 2.42 | 6.86 | 4.17 |
| 我们的方案-语音全微调(4epoch) | 1.61 | 3.54 | 7.67 | 8.38 | 12.31 | 9.69 |
| LoRA微调(4epoch) | 2.72 | 7.19 | 7.11 | 9.95 | 13.22 | 10.45 |
| LoRA微调(1epoch) | 3.80 | 11.52 | 7.03 | 7.04 | 12.50 | 9.54 |
| Phi-4-mm-inst-zeroth-kor | 7.02 | 17.31 | 7.07 | 9.19 | 13.08 | 9.35 |
伊织 xAI 2025-05-05(周一)



















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











