









相关背景
NN的简单含义
简单地说,最近邻检索就是根据数据的相似性,从数据库中寻找与目标数据最相似的项目,而这种相似性通常会被量化到空间上数据之间的距离,可以认为数据在空间中的距离越近,则数据之间的相似性越高。当需要查找离目标数据最近的前k个数据项时,就是k最近邻检索(K-NN)。最近邻检索的应用领域
在当今这个移动互联网时代,我们的日常生活每天都面临着海量数据地冲击,诸如像个人信息、视频
记录、图像采集、地理信息、日志文档等,面对如此庞大且日益增长的数据信息,如何对我们需要的信息有效的存储及索引与查询是目前国内外研究的热点。
最近邻检索起初作为具有查找相似性文档信息的方法被应用于文档检索系统,随后在地理信息系统中,最近邻检索也被广泛应用于位置信息,空间数据关系的查询、分析与统计,如今在图像检索、数据压缩、模式识别以及机器学习等领域都有非常重要的作用,而在这些领域中大多会涉及到海量的多媒体数据信息的处理,其中包括大量图像、视频信息。在图像处理与检索的研究中,基于内容的图像检索方法(CBIR)是目前的主流,这里的“内容”指的是图像中包含的主要对象的几何形状、颜色强度、表面纹理等外在特性,以及前景与后景的对比程度等整体特征。为了获得图像中这些特定的信息或方便后续处理,我们通常会利用多种不同的描述方式来表示图像,包括局部特征描述子(SIFT、SURF、BRIEF) ,全局特征描述子(GIST),特征频率直方图,纹理信息,显著性区域等。最近邻检索的引入将图像检索转化到特征向量空间,通过查找与目标特征向量距离最近的向量来获得相应图像之间的关系。这种特征向量之间的距离通常被定义为欧几里得距离(Euclidean distance),即是空间中两点之间的直线距离。
最近邻检索的发展
最近邻检索作为数据检索中使用最为广泛的技术一直以来都是国内外学者研究的热点。在近些年的研究中涌现出大量以最近邻检索或近似最近邻检索为基本思想的方法,其中一类是基于提升检索结构性能的方法,主要方法大多基于树形结构。另一类主要基于对数据本身的处理,包括哈希算法、矢量量化方法等。
- 精确检索
精确检索中数据维度一般较低。所以会采用简单的蛮力方法,也就是平常所说的穷举搜索,在数据库中依次计算其中样本与所查询数据之间的距离,抽取出所计算出来的距离最小的样本即为所要查找的最近邻。这样做的缺点是当数据量非常大的时候,搜索效率急剧下降。因为实际数据会呈现出簇状的聚类形态,所以可以考虑对数据库中的样本数据构建数据索引,索引树就是最常见的方法。其基本思想是对搜索空间进行层次划分,再进行快速匹配。比如当d=1时,只要采用传统的二分查找法或者各类平衡树就能找到最近邻;当d=2时,情况稍稍复杂点,一般则将最近邻检索问题转化为求解查询点究竟落在哪个区域的Voronoi图问题,再通过二分查找树就能很好的解决,空间复杂度和查询复杂度分别为0(n),O(log n)。当数据维度不太高(如d< 20),通常采用树型索引结构对数据进行分区以实现高效索引,如最经典的KD树算法 、R树、M树等等,它们的时间和空间复杂度都是以d为指数的指数级别的,在实际搜索时也取得了良好的效果。
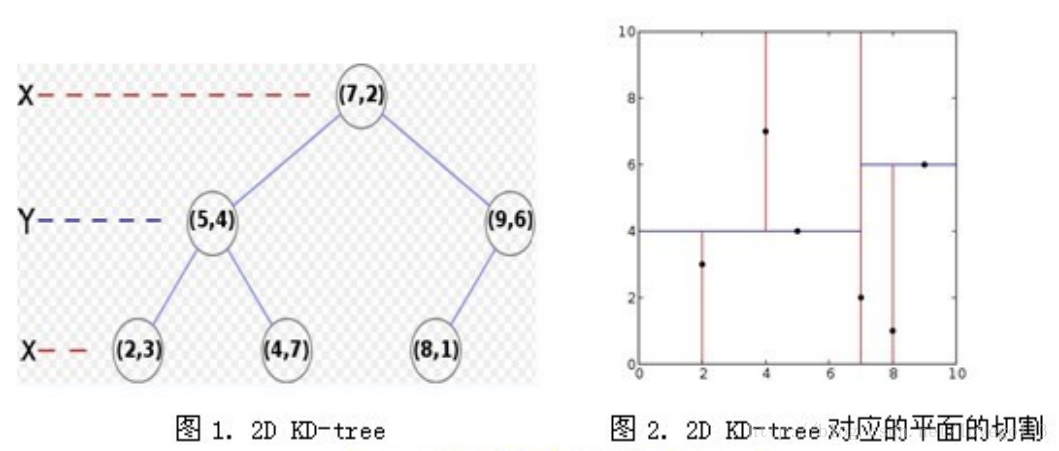
KD-Tree 是由 Finkel 和 Bentley 共同设计提出的对二叉搜索树的推广,利用KD-Tree 我们可以对一个由 K 维数据组成的数据集合进行划分,划分时在树的每一层上根据设定好的分辨器(discriminator)选取数据的某一维,比较待分配数据与节点数据在这一维度上数值的大小,根据结果将数据划分到左右子树中。比如X= {(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}这样的一个由6个点构成的二维点集,我们首先对它的第一维X进行划分,根据二分将(7,2)作为根节点,那么数据点的x轴小于7的划分到左子树,大于7的划分到右子树;再对第二维Y进行划分时,则根据数据点的y轴的大小进行左右划分。
那么对于k维的点集,我们只需要依照上面的方法进行k层这样的划分就可以构成一棵KD-Tree 。然而在做最近邻检索时虽然从根节点到叶子节点自上而下的检索较线性查找节省了时间,但为了找到“最近邻”还需要进行回溯查找比较那些不在已访问分支中的节点,所以当 K 很大即数据维度很高时算法复杂度将大大提高。 - 近似检索
面对庞大的数据量以及数据库中高维的数据信息,现有的基于 NN 的检索方法无法获得理想的检索效果与可接受的检索时间。进而有研究人员开始关注近似最近邻检索(Approximate Nearest Neighbor,ANN),近似最近邻检索利用了数据量增大后数据之间会形成簇状聚集分布的特性,通过对数据分析聚类的方法对数据库中的数据进行分类或编码,对于目标数据根据其数据特征预测其所属的数据类别,返回类别中的部分或全部作为检索结果。近似最近邻检索的核心思想是搜索可能是近邻的数据项而不再只局限于返回最可能的项目,在牺牲可接受范围内的精度的情况下提高检索效率。主要分为两种办法,一种是采用哈希散列的办法,另一种则是矢量量化。
局部敏感哈希(LSH)最早由 P. Indyk and R. Motwani 提出,其核心思想是:在高维空间相邻的数据经过哈希函数的映射投影转化到低维空间后,他们落入同一个吊桶的概率很大而不相邻的数据映射到同一个吊桶的概率则很小。在检索时将欧式空间的距离计算转化到汉明(Hamming)空间,并将全局检索转化为对映射到同一个吊桶中的数据进行检索,从而提高了检索速度。这种方法的主要难点在于如何寻找适合的哈希函数,它的哈希函数必须满足以下两个条件:
1)如果d(x,y) ≤ d1, 则h(x) = h(y)的概率至少为p1;
2)如果d(x,y) ≥ d2, 则h(x) = h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离,d1 < d2, h(x)和h(y)分别表示对x和y进行hash变换。后续的研究中有许多寻找哈希函数的方法。
矢量量化的代表就是乘积量化(PQ),PQ的主要思想是将特征向量进行正交分解,在分解后的低维正交子空间上进行量化,由于低维空间可以采用较小的码本进行编码,因此可以降低数据存储空间 。PQ方法采用基于查找表的非对称距离计算(Asymmetric Distance Computation,ADC)快速求取特征向量之间的距离,在压缩比相同的情况下,与采用汉明距离的二值编码方法,采用ADC的PQ方法的检索精度更高。然而,PQ方法假设各子空间的数据分布相互独立,当子空间数据的相互依赖较强时检索精度下降
严重。针对这点就有通过旋转矩阵来调整数据空间的OPQ(Optimized Product Quantization)算法,如下图,原本按照1234维排列的数据空间通过与正交矩阵R相乘,其维度排列变成了3214,那么我们就可以寻找一个合适的正交矩阵重新排列向量的维度,使得其划分的各子空间之间的依赖性达到最小。
另外还有一个AQ(Additive Quantization)算法,它与PQ算法一样,也是将d维向量划分为m个子向量,对应m个码本,每个码本包含k个码字,然而,PQ中码字长度为d/m,而AQ 中码字长度为d,与待编码特征向量长度一致。



注:文中部分例图来自于网络和相关文章。
展望:以后的数据基本都是大数据量且高维度的,另外哈希散列方法基于二进制编码的近似最近邻查找虽然大大提高了检索效率,但其检索的准确度始终不高,因此以乘积量化为代表的矢量量化方法可能将是一个可行的办法。















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









