









0. 简介
我们在之前的博客中讨论了一些激光回环检测的方法,但是基本都是围绕着点云特征去做的,并未涉足过深度学习的相关方法,之前作者在查找《经典文献阅读之–BoW3D》资料时看到了一个比较感兴趣的工作《OverlapNet: Loop Closing for LiDAR-based SLAM》,同时这个文章还拥有对应的开源源码Github,非常适合复现以及学习。
1. 工作重心
同时定位和映射(SLAM)是大多数自主系统所需的基本能力。在本文中,我们讨论了基于自动驾驶汽车记录的3D激光扫描的SLAM闭环问题。我们的方法利用深度神经网络,利用从激光雷达数据生成的不同线索来寻找环路闭合。它估计广义到距离图像的图像重叠,并提供扫描对之间的相对偏航角估计。基于这些预测,我们处理环路闭合检测,并将我们的方法集成到现有的SLAM系统中,以改善其映射结果。
简单来说,作者通过深度学习完成点云转换为影像,然后做回环检测, 输出Overlap和yaw的操作步骤。
文中指出,本文的主要创新点有:
- 能够利用多个线索,不需提前知道两个雷达扫描的相对位姿,只利用范围、法向量、强度和语义等线索,使用深度神经网络直接估计两个激光雷达扫描的重叠率,以及相对偏航角。
- 结合里程计信息和重叠率预测实现闭环的检测、修正。
- 可以检测到的闭环整合到现有SLAM系统中,可以提高整体位姿估计的结果,产生全局一致的地图。
- 无需先验位姿信息,解决在自动驾驶中3D LiDAR SLAM 的闭环检测问题。
- 使用产生正确扫描匹配结果的OverlapNet网络预测初始化ICP
2. 详细算法
2.1 Overlap的概念
作者认为直接对比两个点云之间的距离不够精确,因为会受漂移的影响。因此提出用重叠率来代替距离检测回环。具体思路是由影像的overlap中来,要成功匹配两个图像并计算它们的相对姿态,图像必须重叠。这可以通过将重叠百分比定义为第一图像中的像素的百分比来量化,该像素可以在没有遮挡的情况下成功地投影回第二图像中。请注意,该度量不是对称的:如果图像对存在较大的尺度差异,例如,一幅图像显示一堵墙,另一幅显示该墙周围的许多建筑物,则第一到第二幅图像的重叠百分比可能较大,而第二到第一幅图像的交叠百分比较低。在本文中,我们使用了距离图像重叠的思想,明确地利用了距离信息
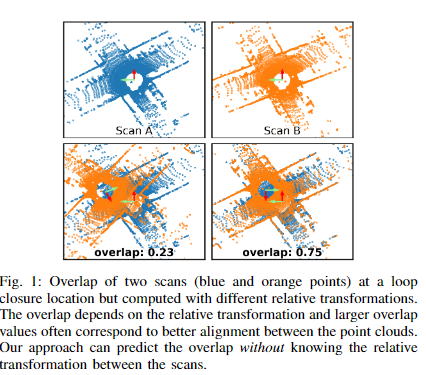
对于环路闭合,重叠百分比的阈值可用于决定两个激光雷达扫描是否在同一位置和/或环路闭合。对于环路闭合,这种测量可能比一对扫描记录位置之间的常用距离更好,因为位置可能会受到漂移的影响,因此不可靠。重叠预测与相对姿势无关,因此可用于查找环路闭合,而无需知道扫描之间的正确相对姿势。
2.2 激光雷达扫描对之间重叠的定义
文中使用激光雷达扫描的球面投影作为输入数据,将点云
P
\mathcal{P}
P投影到所谓的顶点贴图
V
:
R
2
→
R
3
\mathcal{V}:\mathbb{R}^2→ \mathbb{R}^3
V:R2→R3,其中每个像素映射到最近的3D点。每个点
p
i
=
(
x
,
y
,
z
)
p_i=(x,y,z)
pi=(x,y,z)通过函数:
R
3
→
R
2
\mathbb{R}^3→ \mathbb{R}^2
R3→R2转换到球坐标系,最后到图像坐标
(
u
,
v
)
(u,v)
(u,v),通过
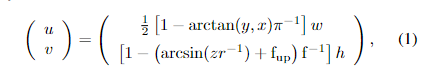
其中
r
=
∣
∣
p
∣
∣
2
r=||p||^2
r=∣∣p∣∣2是范围,
f
=
f
u
p
+
f
d
o
w
n
f=f_{up}+f_{down}
f=fup+fdown是传感器的垂直视场,
w
,
h
w,h
w,h是所得顶点映射
V
\mathcal{V}
V的宽度和高度。
对于一对激光雷达扫描
P
1
\mathcal{P}_1
P1和
P
2
\mathcal{P}_2
P2,我们生成相应的顶点映射
V
1
、
V
2
\mathcal{V}_1、\mathcal{V}_2
V1、V2。我们将时间步长为
t
t
t,且处于传感器为中心的坐标帧表示为
C
t
C_t
Ct。坐标帧
C
t
C_t
Ct中的每个像素通过姿态
T
W
C
t
∈
R
4
×
4
T_{WC_t}\in\mathbb{R}^{4\times4}
TWCt∈R4×4与世界帧W关联。给定姿态
T
W
C
1
T_{WC_1}
TWC1和
T
W
C
2
T_{WC_2}
TWC2,我们可以将扫描点
P
1
\mathcal{P}_1
P1重新投影到另一个顶点映射
V
2
\mathcal{V}_2
V2的坐标系中,并生成重新投影的顶点映射
V
1
′
\mathcal{V}^′_1
V1′:
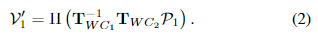
然后,我们计算
V
1
′
\mathcal{V}^′_1
V1′和
V
2
\mathcal{V}_2
V2中所有对应像素的绝对差,仅考虑与两幅距离图像中有效距离读数对应的像素。然后,重叠被计算为相对于所有有效输入的特定距离内的所有差异的百分比,即,两个激光雷达扫描
O
C
1
C
2
O_{C_1C_2}
OC1C2的重叠定义如下:
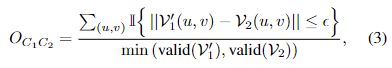
其中如果
a
a
a为真,则
∏
{
a
}
=
1
\prod\{a\}=1
∏{a}=1,否则为0。有效(
V
\mathcal{V}
V)是
V
\mathcal{V}
V为单位的有效像素数,因为并非所有像素在投影后都具有有效的LiDAR测量值。
**简单来说就是将两个点云转化为二维图并且坐标系对齐,如果两个坐标差小于阈值记为1,否则为零,求和再除以两个图中像素较小的那个,**作者想用这个等式建立训练集。对于旋转,作者选择旋转多个角度,用最大重叠值代表最终重叠值。
2.3 网络结构
下图描述了所提出的重叠网络的概述。我们利用了多个线索,这些线索可以从单个激光雷达扫描中生成,包括深度、法线、强度和语义类概率信息。深度信息存储在由一个通道组成的范围图
R
\mathcal{R}
R中。我们使用顶点映射的邻域信息来生成法线映射
N
\mathcal{N}
N,它有三个通道编码法线坐标。我们直接从传感器获得强度信息,也称为缓解,并使用强度信息为单通道强度图
I
\mathcal{I}
I。使用RangeNet++计算逐点语义类概率,我们将其表示为语义图
S
\mathcal{S}
S。RangeNet++提供20个不同类的概率。为了提高效率,我们使用主成分分析将20维RangeNet++输出缩减为压缩的三维向量。信息被组合成一个大小为
64
×
900
×
D
64×900×D
64×900×D的输入张量,其中64900是输入的高度和宽度,
D
D
D取决于使用的数据类型.
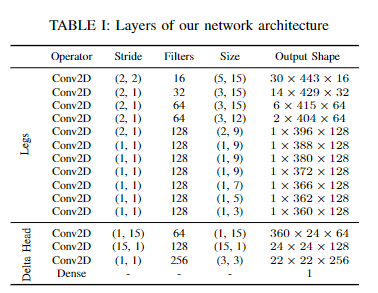
这里没有特别仔细去研究,具体就是由两个共享权重的Legs和由Legs生成的相同特征体积对的Head组成。进一步说这个模型的作用就是将深度图,向量图,强度图,还用RangeNet++做了个语义图一起作为输入。















 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











