







0. 简介
之前作者在《深度学习之从Python到C++》介绍了一些比较传统的方法,主要侧重介绍了如何将pth和pytorch传统形式文件转化为onnx的文件,这个部分的内容,也可以主要看一下《PyTorch模型部署:pth转onnx跨框架部署详解+代码》这个文章的内容,我们发现在实际使用中,真正的TensorRT模型不是和我们之前介绍的这么简单。因为现在包含了很多第三方的依赖库,为此,我们需要使用更有效的方法来完成转化。这里主要参照pytorch模型(.pth)转tensorrt模型(.engine)几种方式
1. onnx-tensorrt
onnx-tensorrt开源项目可以通过选择不同版本的tensorrt来完成有效的部署,并生成trt文件。比如说我们想要使用tensorRT 7.2的版本。比如说通过git checkout -b 7.2.1.然后我们就可以开始编译了。
通过下面的指令我们就可以得到一个编译好的转onnx2trt工具,然后输入
cd onnx-tensorrt
mkdir build && cd build
cmake .. -DTENSORRT_ROOT=<path_to_trt> && make -j
// Ensure that you update your LD_LIBRARY_PATH to pick up the location of the newly built library:
export LD_LIBRARY_PATH=$PWD:$LD_LIBRARY_PATH

ONNX模型可以使用onnx2trt可执行文件转换为序列化的TensorRT引擎:
onnx2trt my_model.onnx -o my_engine.trt
ONNX模型也可以转换为人类可读的文本:
onnx2trt my_model.onnx -t my_model.onnx.txt
详细的操作可以看Github即可。
2. trtexec
而另一种方法就是trtexec,它是TensorRT的自带工具,如果您将模型保存为 ONNX 文件、UFF 文件,或者如果您有 Caffe prototxt 格式的网络描述,则可以使用trtexec工具测试使用 TensorRT 在网络上运行推理的性能。 trtexec是一种无需开发自己的应用程序即可快速使用 TensorRT 的工具。
trtexec工具有三个主要用途:
- 它对于在随机或用户提供的输入数据上对网络进行基准测试很有用。
- 它对于从模型生成序列化引擎很有用。
- 它对于从构建器生成序列化时序缓存很有用。
2.1 常用的命令行标志
该部分列出了常用的trtexec命令行标志。
2.1.1 构建阶段的标志
--onnx=<model> :指定输入 ONNX 模型。
--deploy=<caffe_prototxt> :指定输入的 Caffe prototxt 模型。
--uff=<model> :指定输入 UFF 模型。
--output=<tensor> :指定输出张量名称。仅当输入模型为 UFF 或 Caffe 格式时才需要。
--maxBatch=<BS> :指定构建引擎的最大批量大小。仅当输入模型为 UFF 或 Caffe 格式时才需要。如果输入模型是 ONNX 格式,请使用--minShapes 、 --optShapes 、 --maxShapes标志来控制输入形状的范围,包括批量大小。
--minShapes=<shapes> , --optShapes=<shapes> , --maxShapes=<shapes> :指定用于构建引擎的输入形状的范围。仅当输入模型为 ONNX 格式时才需要。
--workspace=<size in MB>:指定策略允许使用的最大工作空间大小。该标志已被弃用。您可以改用--memPoolSize=<pool_spec>标志。
--memPoolSize=<pool_spec> :指定策略允许使用的工作空间的最大大小,以及 DLA 将分配的每个可加载的内存池的大小。
--saveEngine=<file> :指定保存引擎的路径。
--fp16 、 --int8 、 --noTF32 、 --best :指定网络级精度。
--sparsity=[disable|enable|force] :指定是否使用支持结构化稀疏的策略。
disable:使用结构化稀疏禁用所有策略。这是默认设置。enable:使用结构化稀疏启用策略。只有当 ONNX 文件中的权重满足结构化稀疏性的要求时,才会使用策略。force:使用结构化稀疏启用策略,并允许trtexec覆盖 ONNX 文件中的权重,以强制它们具有结构化稀疏模式。请注意,不会保留准确性,因此这只是为了获得推理性能。
--timingCacheFile=<file> :指定要从中加载和保存的时序缓存。
--verbose :打开详细日志记录。
--buildOnly :在不运行推理的情况下构建并保存引擎。
--profilingVerbosity=[layer_names_only|detailed|none] :指定用于构建引擎的分析详细程度。
--dumpLayerInfo , --exportLayerInfo=<file>:打印/保存引擎的层信息。
--precisionConstraints=spec :控制精度约束设置。
none:没有限制。prefer:如果可能,满足--layerPrecisions / --layerOutputTypes设置的精度约束。obey:满足由--layerPrecisions / --layerOutputTypes设置的精度约束,否则失败。
--layerPrecisions=spec :控制每层精度约束。仅当PrecisionConstraints设置为服从或首选时才有效。规范是从左到右阅读的,后面的会覆盖前面的。 “ * ”可以用作layerName来指定所有未指定层的默认精度。
例如: --layerPrecisions=*:fp16,layer_1:fp32将所有层的精度设置为FP16 ,除了 layer_1 将设置为 FP32。
--layerOutputTypes=spec :控制每层输出类型约束。仅当PrecisionConstraints设置为服从或首选时才有效。规范是从左到右阅读的,后面的会覆盖前面的。 “ * ”可以用作layerName来指定所有未指定层的默认精度。如果一个层有多个输出,则可以为该层提供用“ + ”分隔的多种类型。
例如: --layerOutputTypes=*:fp16,layer_1:fp32+fp16将所有层输出的精度设置为FP16 ,但 layer_1 除外,其第一个输出将设置为 FP32,其第二个输出将设置为 FP16。
2.1.2 推理阶段的标志
--loadEngine=<file> :从序列化计划文件加载引擎,而不是从输入 ONNX、UFF 或 Caffe 模型构建引擎。
--batch=<N> :指定运行推理的批次大小。仅当输入模型为 UFF 或 Caffe 格式时才需要。如果输入模型是 ONNX 格式,或者引擎是使用显式批量维度构建的,请改用–shapes 。
--shapes=<shapes> :指定要运行推理的输入形状。
--warmUp=<duration in ms> , --duration=<duration in seconds> , --iterations=<N> : 指定预热运行的最短持续时间、推理运行的最短持续时间和推理运行的迭代。例如,设置--warmUp=0 --duration=0 --iterations允许用户准确控制运行推理的迭代次数。
--useCudaGraph :将推理捕获到 CUDA 图并通过启动图来运行推理。当构建的 TensorRT 引擎包含 CUDA 图捕获模式下不允许的操作时,可以忽略此参数。
--noDataTransfers :关闭主机到设备和设备到主机的数据传输。
--streams=<N> :并行运行多个流的推理。
--verbose :打开详细日志记录。
--dumpProfile, --exportProfile=<file> :打印/保存每层性能配置文件。
有关所有受支持的标志和详细说明,请参阅trtexec --help 。
2.2 trtexec的plugins
我们发现在使用trtexec的时候,有些时候有些不包含在pytorch原始代码中的程序是无法完成直接转换的,为什么说要生成plugins呢,这就涉及到TensorRT的本质了。我们将来一步步进行阐述。
2.2.1 编译TensorRT以及生成内容
Github下载TensorRT的编译源文件链接,另外下载第三方库onnx,cub,protobuf并放到TensorRT源文件相应的文件夹里
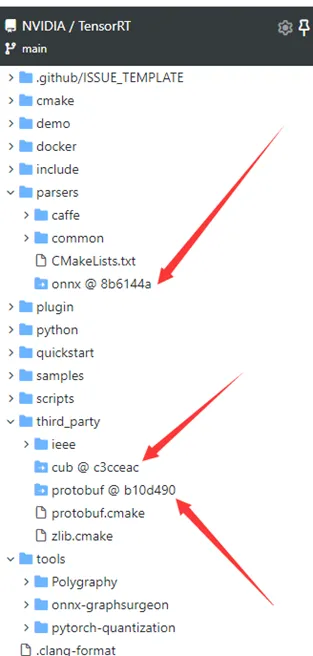
在TensorRT源文件根目录下执行下列命令:
cmake -B build
cd build
make
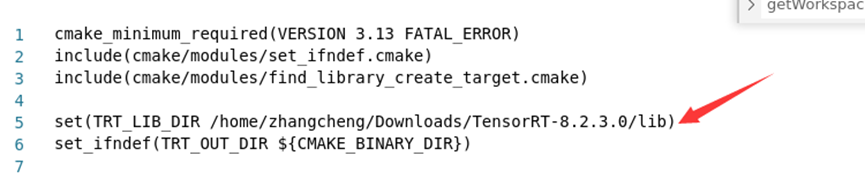
如果已安装的tensorRT库未添加环境变量,上述编译过程会报错,提示找不到文件,我们可以直接在CMakeLists.txt文件中指定TensorRT库路径,如下图所示
另外,官方提供的cmakelists默认编译parser,plugin,还有sample。自定义算子不需要编译sample,可以将它关闭了。
option(BUILD_PLUGINS "Build TensorRT plugin" ON)
option(BUILD_PARSERS "Build TensorRT parsers" ON)
option(BUILD_SAMPLES "Build TensorRT samples" OFF)
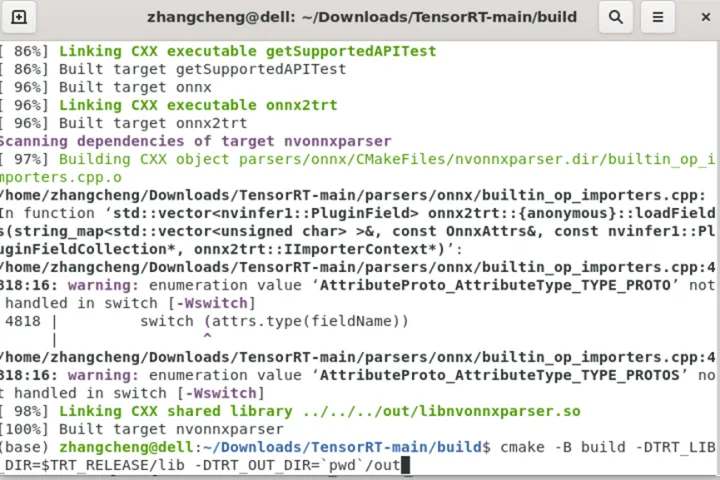
导出结果如下图:
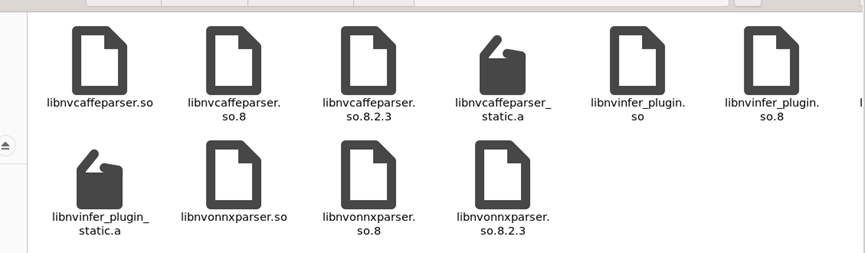
out文件夹存储了编译后的各种链接库,将其复制到tensorRT/lib目录下,替换原本的链接库文件。 进行到这一步已经可以了,我们可以看到TensorRT本质编译过后就是动态链接库的.so的形式。
2.2.2 常用的plugin插件
随着tensorRT的不断发展(v5->v6->v7),TensorRT的插件的使用方式也在不断更新。插件接口也在不断地变化,由v5版本的IPluginV2Ext,到v6版本的IPluginV2IOExt和IPluginV2DynamicExt。未来不知道会不会出来新的API,不过这也不是咱要考虑的问题,因为TensorRT的后兼容性做的很好,根本不用担心你写的旧版本插件在新版本上无法运行。

TensorRT插件的存在目的,主要是为了让我们实现TensorRT目前还不支持的算子,毕竟众口难调嘛,我们在转换过程中肯定会有op不支持的情况。这个时候就需要使用TensorRT的plugin去实现我们的自己的op。此时我们需要通过TensorRT提供的接口去实现自己的op,因此这个plugin的生命周期也需要遵循TensorRT的规则。我们常用的plugin,主要有两个plugin插件,即TensorRT的官方plugin库
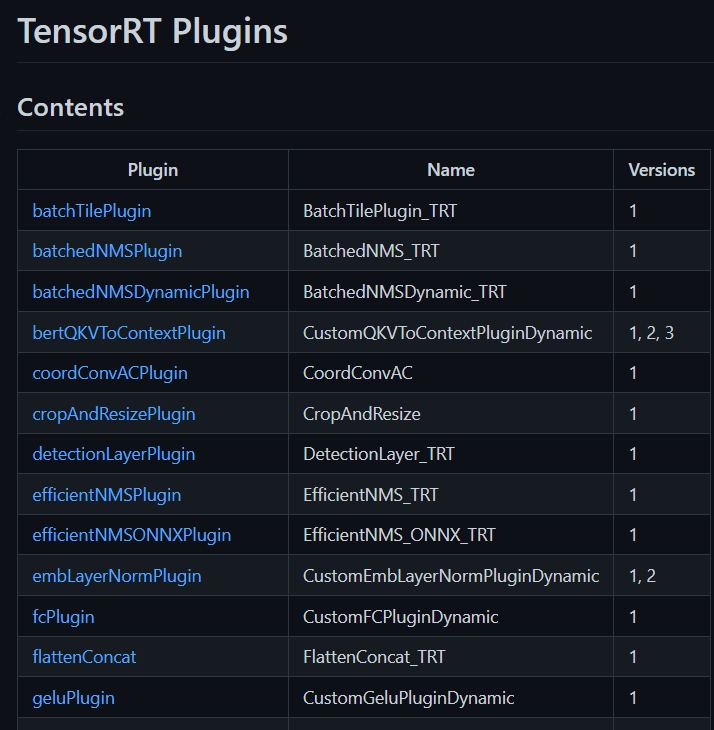
以及open-mmlab的plugin插件库。
官方提供的插件已经相当多,而且TensorRT开源了plugin部分。并且可以看到其源码,通过模仿源码来学习plugin是如何写的。
2.2.3 添加自己的算子
如果要添加自己的算子,可以在官方的plugin库里头进行修改添加,然后编译官方的plugin库。将生成的libnvinfer_plugin.so.7替换原本的.so文件即可。或者自己写一个类似于官方plugin的组件,将名称替换一下,同样生成.so,在TensorRT的推理项目中引用这个动态链接库即可。有兴趣的可以先看看TensorRT的官方文档。下面我们将整个流程分为几个步骤。
- 打开TRT源代码仓库

- 复制LeakyReluPlugin文件将其改成CustomPlugin,里面的头文件还有cpp文件统统改为自己想要的名字,顺便把代码里面的类型名也改了,见下图。

- 为了后续方便注册,自定义插件Custom类需要继承nvinfer1::IPluginV2DynamicExt接口,另外需要增加一些重写方法和属性(插件类继承IPluginV2DynamicExt才可以支持动态尺寸,其他插件类接口例如IPluginV2IOExt和前者大部分是相似的。)
- CustomPlugin,继承IPluginV2DynamicExt,是插件类,用于写插件具体的实现
- CustomPluginCreator,继承BaseCreator,是插件工厂类,用于根据需求创建该插件
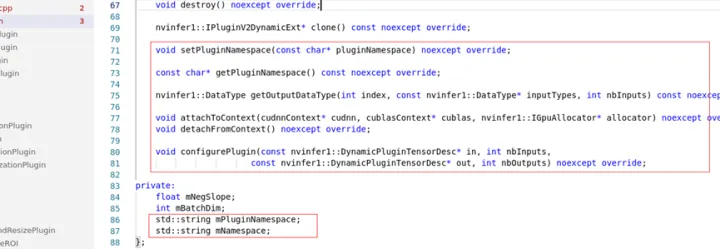
下面是对应的cpp实现


















 3691
3691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











