







0. 简介
Occ其实是自动驾驶中最常用也是比较重要的工作,所以在这一篇,我们着重来聊一聊Occ端到端知识,这个知识内容比较散,但是干货比较多,适合有一定基础的人来看。
1. OpenOcc整理
这个 Occupancy3D-nuScenes-V1.0 数据集是我们在做Occ中最常用的数据集,其目录结构和内容如下:
Occupancy3D-nuScenes-V1.0
│
├── mini
│
├── trainval
│ ├── imgs
│ │ ├── CAM_BACK
│ │ │ ├── n015-2018-07-18-11-07-57+0000_CAM_BACK__1531883530437525_.jpg
│ │ │ ├── ...
│ │ ├── CAM_BACK_LEFT
│ │ │ ├── n015-2018-07-18-11-07-57+0000_CAM_BACK_LEFT__1531883530447423_.jpg
│ │ │ ├── ...
│ │ ├── ...
│ │
│ ├── gts
│ │ ├── [scene_name]
│ │ │ ├── [frame_token]
│ │ │ │ ├── labels.npz
│ │ │ ├── ...
│ │
│ ├── annotations.json
│
├── test
│ ├── imgs
│ ├── annotations.json
1.1 目录和文件解释
- imgs/:
包含由各种摄像头捕获的图像。
图像文件夹按摄像头位置分类,例如CAM_BACK和CAM_BACK_LEFT。
每个图像文件名包含时间戳和摄像头信息。 - gts/:
包含每个样本的真实值(ground truth)。
[scene_name]指定一系列帧的场景名称。
[frame_token]指定序列中单个帧的标识符。
labels.npz文件包含每帧的语义标签、激光雷达数据掩码和摄像头数据掩码。 - annotations.json:
包含数据集的元数据信息。
结构如下:
{
"train_split": ["scene-0001", ...],
"val_split": ["scene-0003", ...],
"scene_infos": {
"[scene_name]": {
"[frame_token]": {
"timestamp": "<str>",
"camera_sensor": {
"[cam_token]": {
"img_path": "<str>",
"intrinsic": "<float[3, 3]>",
"extrinsic": {
"translation": "<float[3]>",
"rotation": "<float[4]>"
}
}
},
"ego_pose": {
"translation": "<float[3]>",
"rotation": "<float[4]>"
},
"gt_path": {
"next": "<str>",
"prev": "<str>"
}
}
}
}
}
- 解释:
train_split和val_split是训练和验证数据集的场景名称列表。scene_infos包含每个场景的详细信息:timestamp: 时间戳或唯一标识符。camera_sensor: 摄像头传感器的元信息。img_path: 对应的图像文件路径。intrinsic: 摄像头的内参矩阵。extrinsic: 摄像头的外参,包括平移和旋转。
ego_pose: 车辆的位姿,包括平移和旋转。gt_path: 真实值路径,包括前一帧和后一帧的标识符。
- labels.npz:
包含每帧的语义标签(semantics)、激光雷达数据掩码(mask_lidar)和摄像头数据掩码(mask_camera)。
1.2 评测指标
1.2.1 语义指标 (mIoU)
语义指标用于评估模型在不同语义类别上的表现。这里使用的是平均交并比(mean Intersection over Union, mIoU),其计算公式如下:
mIoU = 1 C ∑ c = 1 C TP c TP c + FP c + FN c \text{mIoU} = \frac{1}{C} \sum_{c=1}^{C} \frac{\text{TP}_c}{\text{TP}_c + \text{FP}_c + \text{FN}_c} mIoU=C1c=1∑CTPc+FPc+FNcTPc
其中:
C
C
C是语义类别的数量。
TP
c
\text{TP}_c
TPc 是类别
c
c
c 的真正例(True Positives)。
FP
c
\text{FP}_c
FPc 是类别
c
c
c 的假正例(False Positives)。
FN
c
\text{FN}_c
FNc 是类别
c
c
c 的假负例(False Negatives)。
mIoU 衡量的是模型在所有类别上的平均表现,数值越高表示模型在语义分割任务上的表现越好。
1.2.2 几何指标 (IoU_geo)
几何指标用于评估场景几何重建的质量。这里使用的是类无关的交并比(class-agnostic Intersection over Union, IoU_geo),其计算公式如下:
IoUgeo = TPgeo TPgeo + FPgeo + FN geo \text{IoU}{\text{geo}} = \frac{\text{TP}{\text{geo}}}{\text{TP}{\text{geo}} + \text{FP}{\text{geo}} + \text{FN}_{\text{geo}}} IoUgeo=TPgeo+FPgeo+FNgeoTPgeo
其中:
TP
geo
\text{TP}_{\text{geo}}
TPgeo是几何重建中的真正例。
FP
geo
\text{FP}_{\text{geo}}
FPgeo是几何重建中的假正例。
FN
geo
\text{FN}_{\text{geo}}
FNgeo是几何重建中的假负例。
IoU_geo 衡量的是模型在几何重建任务上的表现,数值越高表示模型在几何重建上的表现越好。
在SurroundOcc中,Occupancy 指标评测的详细定义在 projects/mmdet3d_plugin/datasets/evaluation_metrics.py 文件中
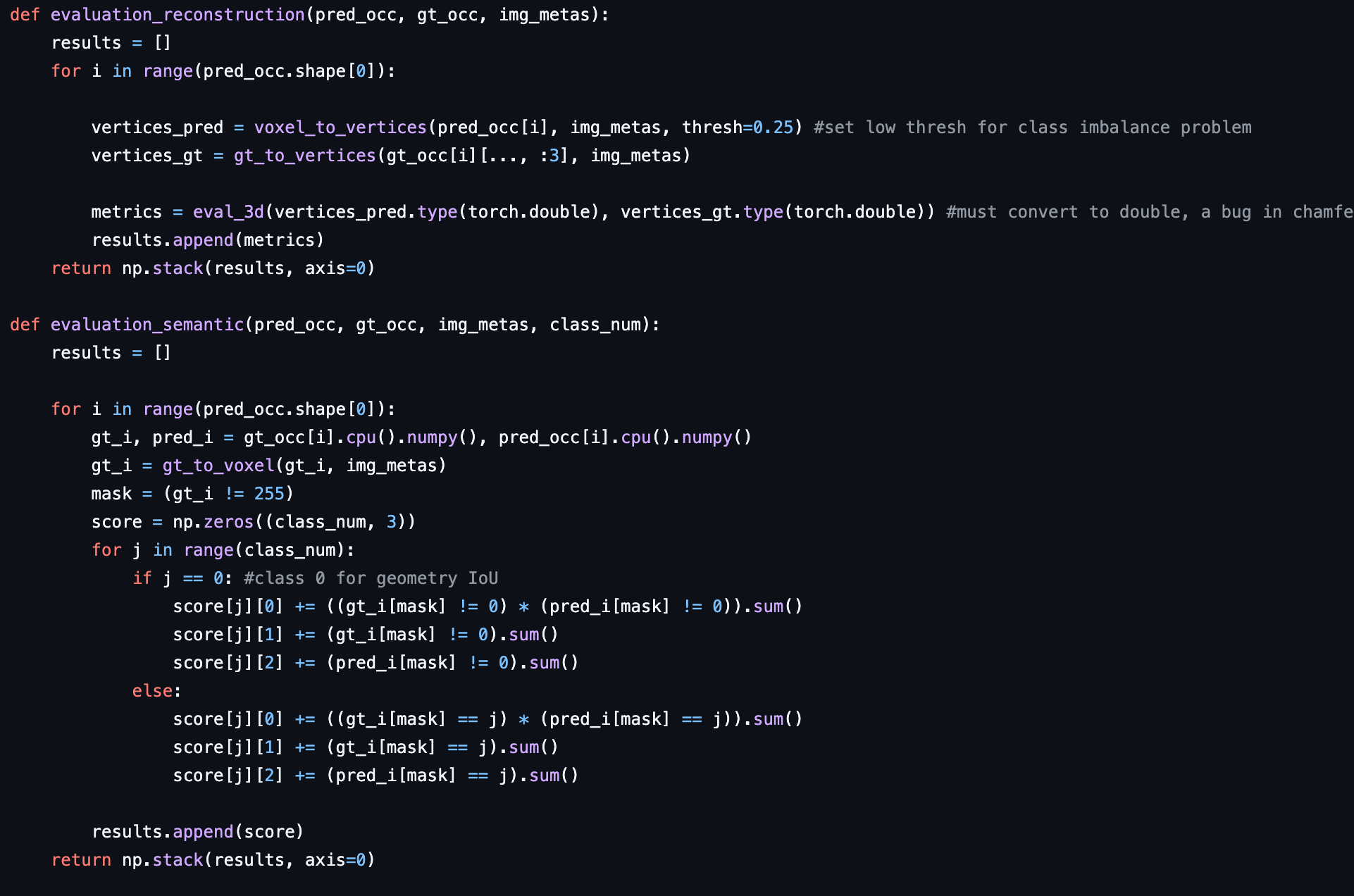
1. evaluation_reconstruction 函数
该函数用于评估几何重建的质量,具体步骤如下:
输入参数:
pred_occ: 预测的占据网格(occupancy grid)。gt_occ: 真实的占据网格。img_metas: 图像元数据。
步骤:
- 初始化结果列表
results。 - 遍历每个样本:
- 使用
voxel_to_vertices函数将预测的占据网格转换为顶点,设置阈值为 0.25。 - 使用
gt_to_vertices函数将真实的占据网格转换为顶点。 - 使用
eval_3d函数计算预测顶点和真实顶点之间的 3D 评估指标,并将结果转换为 double 类型。 - 将计算的指标添加到结果列表中。
- 使用
- 返回结果列表的堆叠数组。
2. evaluation_semantic 函数
该函数用于评估语义分割的质量,具体步骤如下:
输入参数:
pred_occ: 预测的占据网格。gt_occ: 真实的占据网格。img_metas: 图像元数据。class_num: 语义类别的数量。
步骤:
- 初始化结果列表
results。 - 遍历每个样本:
- 将真实占据网格和预测占据网格转换为 numpy 数组。
- 创建掩码,选择真实占据网格中值大于 0.25 的部分。
- 初始化分数数组
score,大小为(class_num, 3)。
- 遍历每个语义类别:
- 跳过类别 0(几何 IoU 不计算该类别)。
- 计算真正例、假正例和假负例的数量,并存储在
score数组中。
- 将分数数组添加到结果列表中。
- 返回结果列表的堆叠数组。
2. Occ框架概览
下面是TPVFormer作者对BEV系列做了比较好的总结。大概来说可以分为下面六个部分。首先输入多模态数据之后,会做一个image encoder,从而得到一个2D特征。然后下面就是使用一些特征表示。主要是将2D特征转化为向量来处理表示,一边传入到2D-3D的特征转换操作。这个特征转换部分包括LSS,BEVFormer这些方法,将2D的图像特征转化道BEV视角下。然后转换完后我们会用不同的特征表示来给出,无论是Total Point of View,Occupany,还是BEV占用都可以用于表示,从而达到我们的任务需求。然后就是设计多头任务来给出不同输出结果,比如lanes network(静态元素),fisheye 3D(动态物体)这些。最后一步就是真值生成,来完成loss生成。



















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











