







1. 简介
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力,此外还有3090和P40,价格每小时只需要8毛,赠送的算礼金够用一整天。
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
最近,Qwen发布了最新的32B推理模型QwQ-32B,其性能在许多基准测试中表现出色,甚至不逊色于671B参数的满血版DeepSeek R1。QwQ-32B基于Qwen2.5-32B,并通过强化学习(RL)进行进一步优化。目前实测需要全部放在GPU上需要四卡4090,单卡只能放cpu一起跑

目前相关镜像已经存入网站:QwQ-32B-深度思考满血版中了。此外还有Deepseek-R1 671B、Ollama-DeepSeek-R1-32B和Ollama-DeepSeek-R1-70B可供选择
2. 环境设置
为了使用QwQ-32B模型,首先需要更新pip并安装必要的依赖包。以下是相关的命令行代码:
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装依赖包
pip install modelscope==1.9.5
pip install transformers==4.48.3
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==1.3.0
pip install transformers_stream_generator==0.0.4
# 下载安装包
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
apt install gcc-11
# 设置安装包可执行
chmod +x cuda_12.1.0_530.30.02_linux.run
sh cuda_12.1.0_530.30.02_linux.run
3. 强化学习的应用
扩展强化学习(RL)在提升模型性能方面展现出巨大的潜力,超越了传统的预训练和后训练方法。研究表明,RL可以显著改善模型的推理能力。例如,DeepSeek R1通过整合冷启动数据和多阶段训练,达到了最先进的性能,使得复杂推理成为可能。
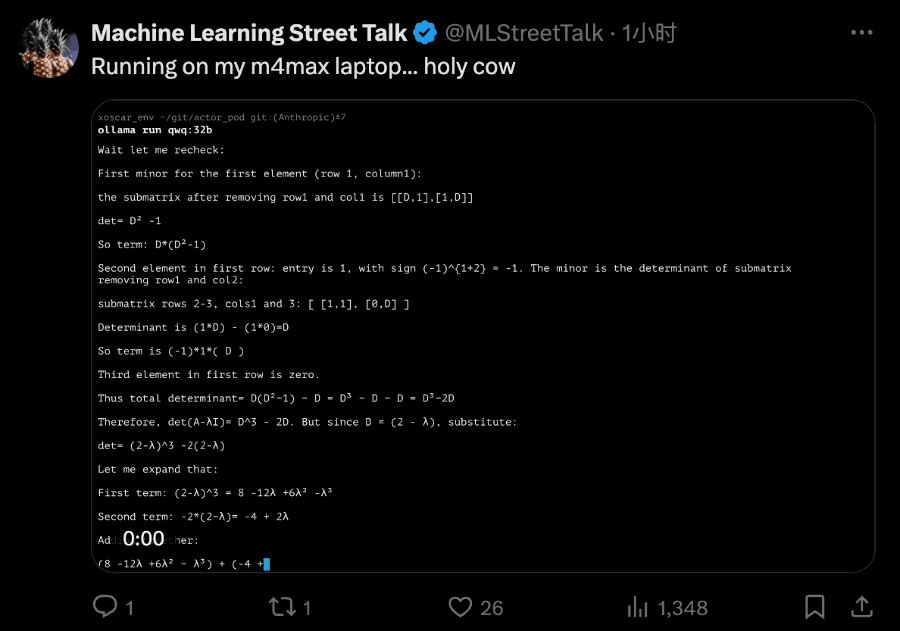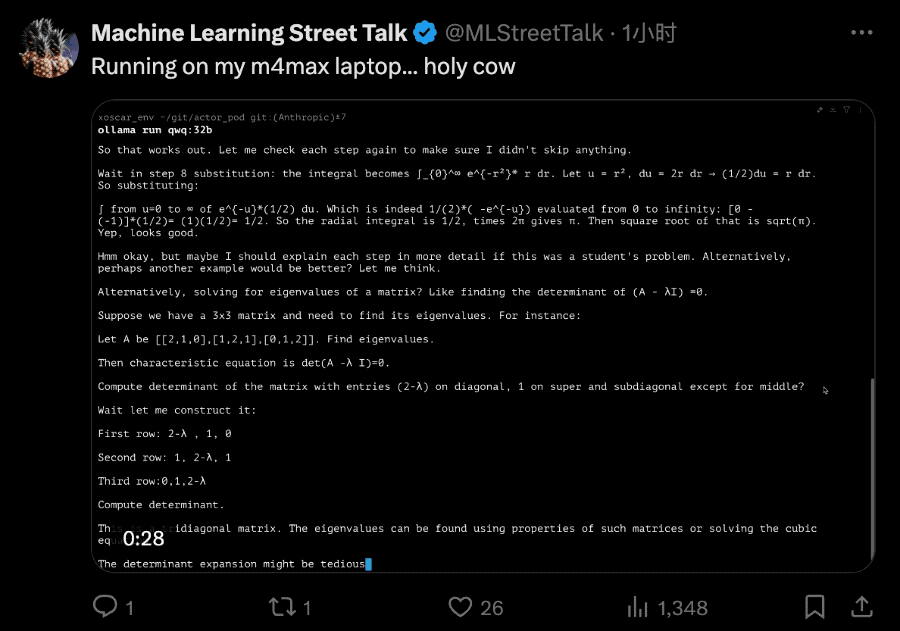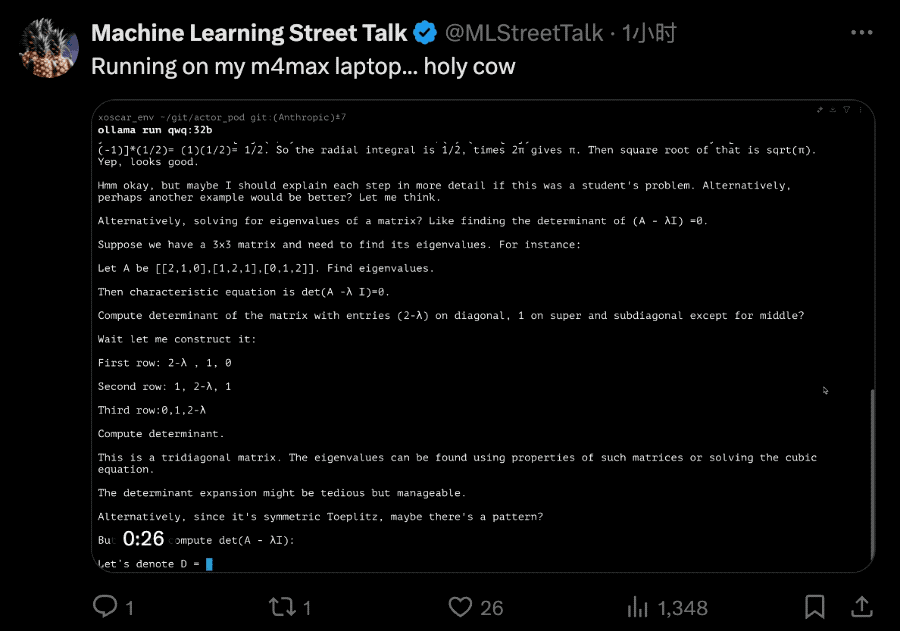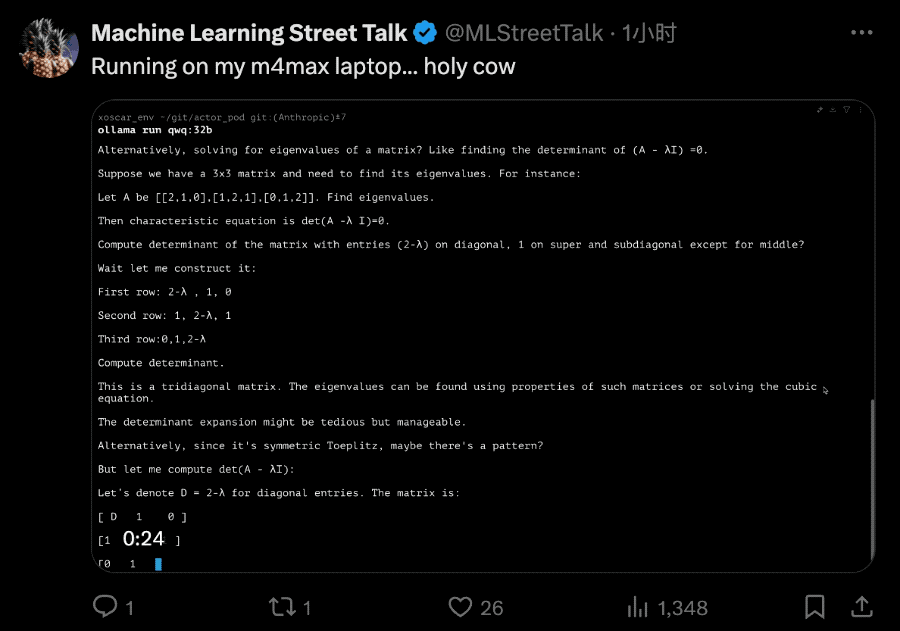
QwQ-32B拥有320亿参数,其性能可与具有6710亿参数的DeepSeek-R1相媲美。该模型尚未发布完整技术报告,但官方页面对其强化学习方法进行了简要说明:
- 从一个冷启动检查点开始,实施基于结果奖励的强化学习(RL)。
- 初始阶段专注于数学和编码任务,使用数学问题准确性验证器和代码执行服务器来确保解决方案的正确性。
- 随着训练的推进,两个领域的性能持续提升。
在第一阶段后,增加了通用能力的强化学习,使用来自通用奖励模型的奖励和一些基于规则的验证器进行训练。
4. 开放权重与访问
QwQ-32B模型在Hugging Face和ModelScope上以开放权重形式发布,遵循Apache 2.0许可证,并可通过Qwen Chat访问。
5. 性能评估
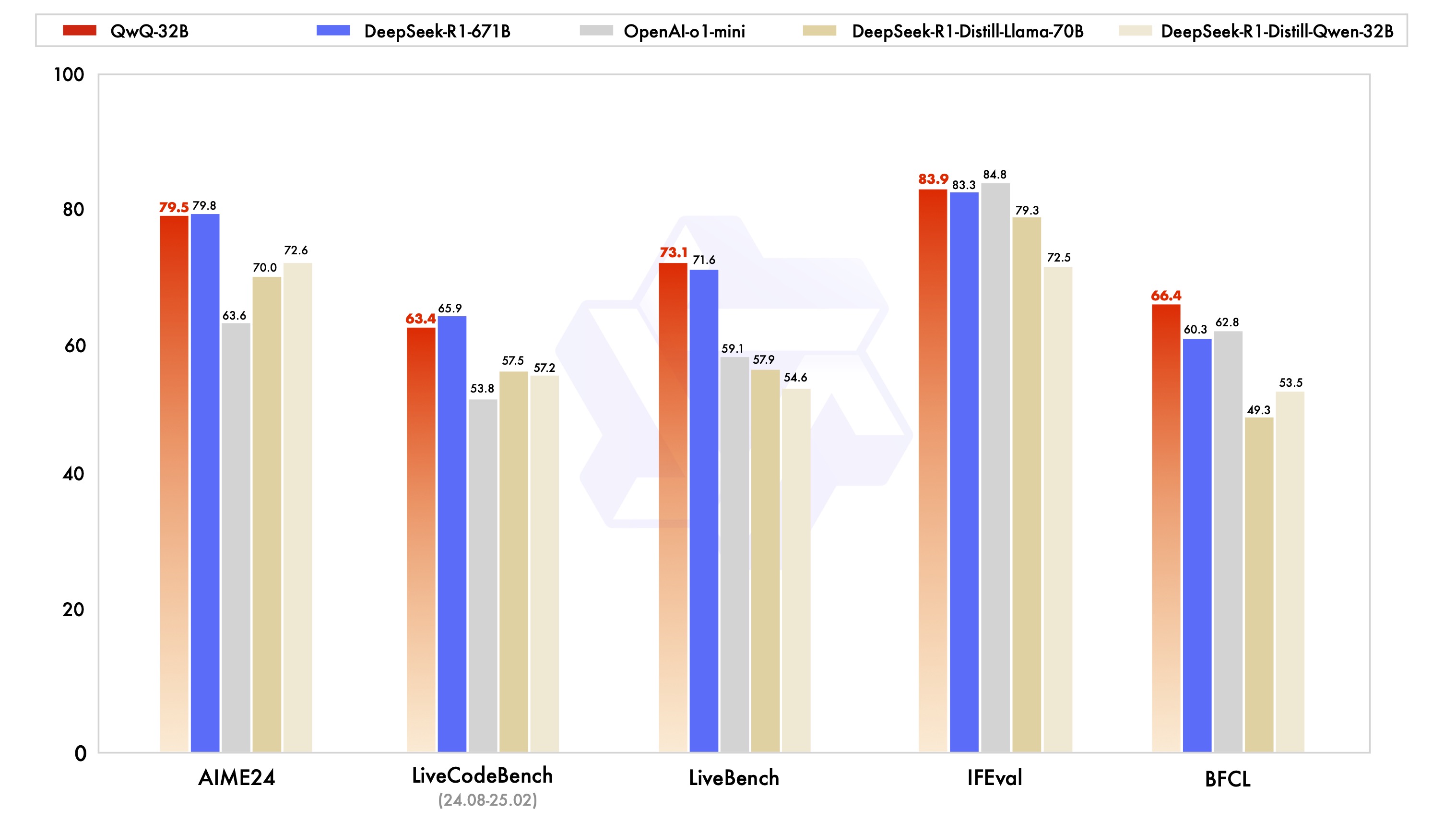
QwQ-32B在一系列基准测试中进行了评估,重点关注数学推理、编码能力和一般问题解决能力。以下是QwQ-32B与其他领先模型的性能比较:
6. 使用QwQ-32B
以下是通过Hugging Face Transformers和阿里云DashScope API使用QwQ-32B的示例代码:
6.1 使用Hugging Face Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
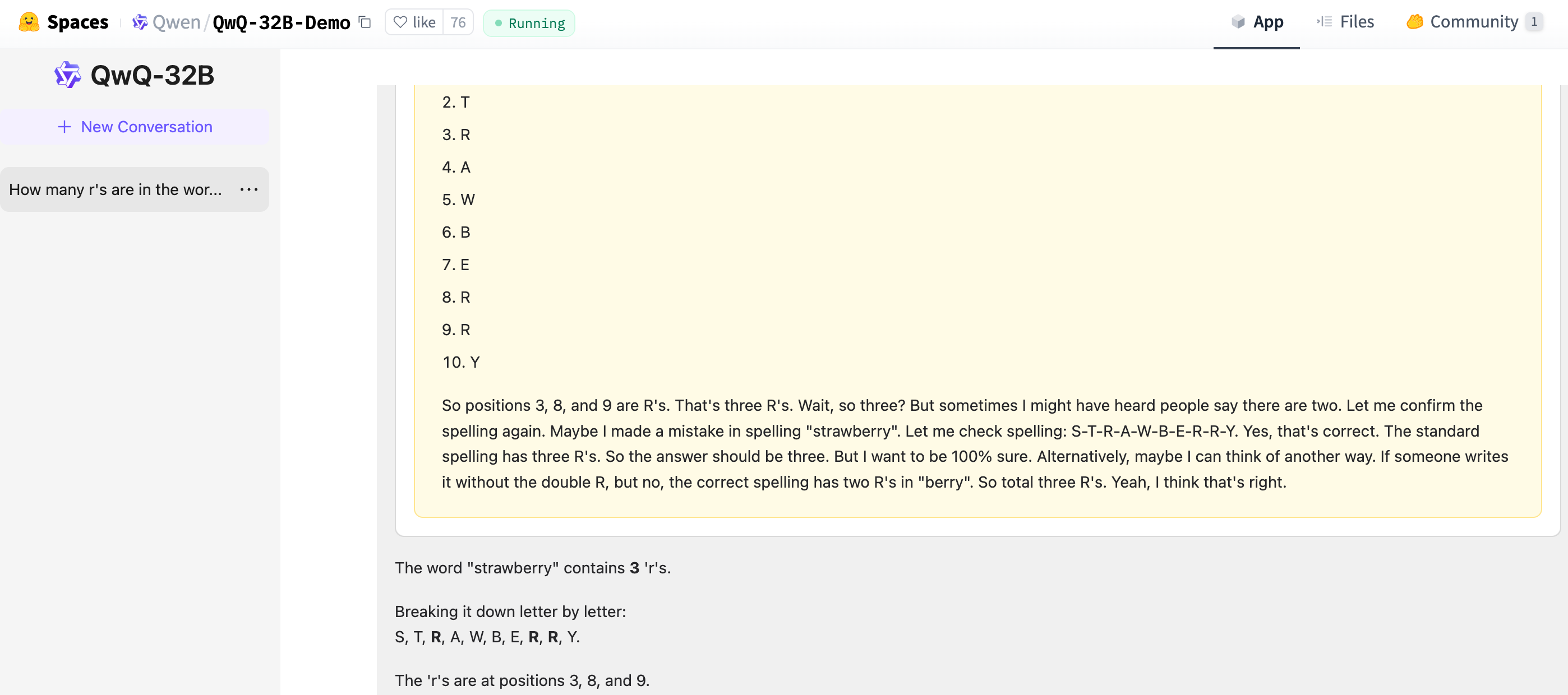
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
运行python api_qwq.py完成测试

6.2 可视化
以下是一个使用Streamlit构建的QwQ-32B聊天机器人的示例代码,默认提供是非流式的对话平台:
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## Qwen/QwQ-32B LLM")
max_length = st.slider("max_length", 0, 32768, 4096, step=1)
# 创建一个标题和一个副标题
st.title("💬 Qwen/QwQ-32B Chatbot")
st.caption("🚀 A streamlit chatbot powered by Hugging Face Transformers")
# 定义模型路径
model_name = "Qwen/QwQ-32B"
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
model.eval()
return tokenizer, model
# 加载模型和tokenizer
tokenizer, model = get_model()
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "有什么可以帮您的?"}]
# 显示聊天记录
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 处理用户输入
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=max_length
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
st.session_state.messages.append({"role": "assistant", "content": response})
st.chat_message("assistant").write(response)
如果想要流式的对话平台,请替换为下面的代码:
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM, TextIteratorStreamer
import torch
import streamlit as st
from threading import Thread
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## Qwen/QwQ-32B LLM")
max_length = st.slider("max_length", 0, 32768, 4096, step=1)
# 创建一个标题和一个副标题
st.title("💬 Qwen/QwQ-32B Chatbot")
st.caption("🚀 A streamlit chatbot powered by Hugging Face Transformers")
# 定义模型路径
model_name = "Qwen/QwQ-32B"
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
model.eval()
return tokenizer, model
# 加载模型和tokenizer
tokenizer, model = get_model()
if "messages" not in st.session_state:
st.session_state.messages = [{"role": "assistant", "content": "有什么可以帮您的?"}]
# 显示聊天记录
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 定义生成响应的函数
def generate_response(prompt):
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True)
generation_kwargs = {
"input_ids": model_inputs['input_ids'].to(model.device),
"streamer": streamer,
"max_new_tokens": max_length, # 可以根据需要调整
"temperature": 0.95,
"top_p": 0.8,
}
# 启动生成线程
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
generated_text = ""
for new_text in streamer:
generated_text += new_text
yield generated_text # 流式输出生成的文本
thread.join() # 等待线程完成
# 处理用户输入
if prompt := st.chat_input("请输入问题"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
message_placeholder = st.empty() # 创建一个占位符
for new_text in generate_response(prompt):
message_placeholder.markdown(new_text) # 更新占位符内容
# 将生成的完整内容添加到消息记录中
st.session_state.messages.append({"role": "assistant", "content": new_text})
# 清空按钮
if st.button("清空"):
st.session_state.messages = [{"role": "assistant", "content": "有什么可以帮您的?"}]
st.experimental_rerun()
在终端中运行以下命令启动 streamlit 服务,并按照 compshare 的指示将端口映射到本地,然后在浏览器中打开链接 http://外部链接:11434/,即可看到聊天界面。
streamlit run /workspace/streamlit_qwq.py --server.address 0.0.0.0 --server.port 11434
7. 在线体验:
https://chat.qwen.ai
https://huggingface.co/spaces/Qwen/QwQ-32B-Demo
8. 参考链接
https://qwenlm.github.io/blog/qwq-32b/
https://x.com/Alibaba_Qwen/status/1897366093376991515
https://mp.weixin.qq.com/s/ZtnUV0RLf6_CR04Sbm-Wyw


















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











