







1、Tensorrt的量化方式/ncnn
对称的饱和量化,从ncnn的源码来看,使用的是逐通道量化,tensorrt没看源码就不知道了(应该也是):
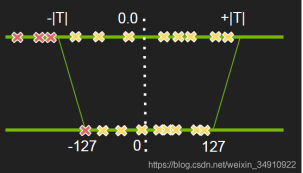
问题的核心转化为如何寻找一个最优值T,是的饱和量化能够精度最小,转化为最优化的问题。
英伟达使用kl散度来比较量化前后两个分布的差异,即相对熵,则问题转化为求相对熵的最小值。1、从信息熵的角度来解释,kl散度最小则代表两个分布差异最小。2、将log换为以2为底的数,则代表信息的编码字组组成,编码信息量的差异。
量化流程(尽量去简化理解,其实很简单):
- 准备一个校准数据集,收集校准表,对每一层:
- 收集激活值的直方图
- 基于不同的阈值(浮点的截断阈值)产生不同的量化分布
- 计算每个分布与原分布的相对熵,选择min值,则得到最像原分布的1个。
此时,便选出了阈值,也就得到了scale。
量化流程伪代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3796
3796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









