






动机:
他们认为,人的属性识别的准确性受以下因素的影响较大:1)只有局部部分与某些属性相关;2)具有挑战性的因素,如姿势变化、视角和遮挡;3).属性与不同部分区域之间的复杂关系。因此,他们提出了使用基于图的推理框架来联合建模区域-区域、属性-属性和区域属性的空间和语义关系。
contributions :
(1) A visual-semantic graph reasoning framework is proposed to jointly model spatial and semantic relations for sequential pedestrian attribute prediction.
(2) A novel end-to-end architecture is presented based on spatial and semantic graphs, which not only capture spatial relations between regions and potential semantic relations between attributes , but also model the relations between regions and attributes by performing mutual embedding between the two graphs to guide the relational learning for each other.
(3) The proposed method is evaluated on 3 large-scale pedestrian attribute benchmarks including PETA, RAP and PA-100k . Experiments show superiority of the proposed method over state-of-the-art methods and effectiveness of our joint GCN structures for sequential attribute prediction.
框架:
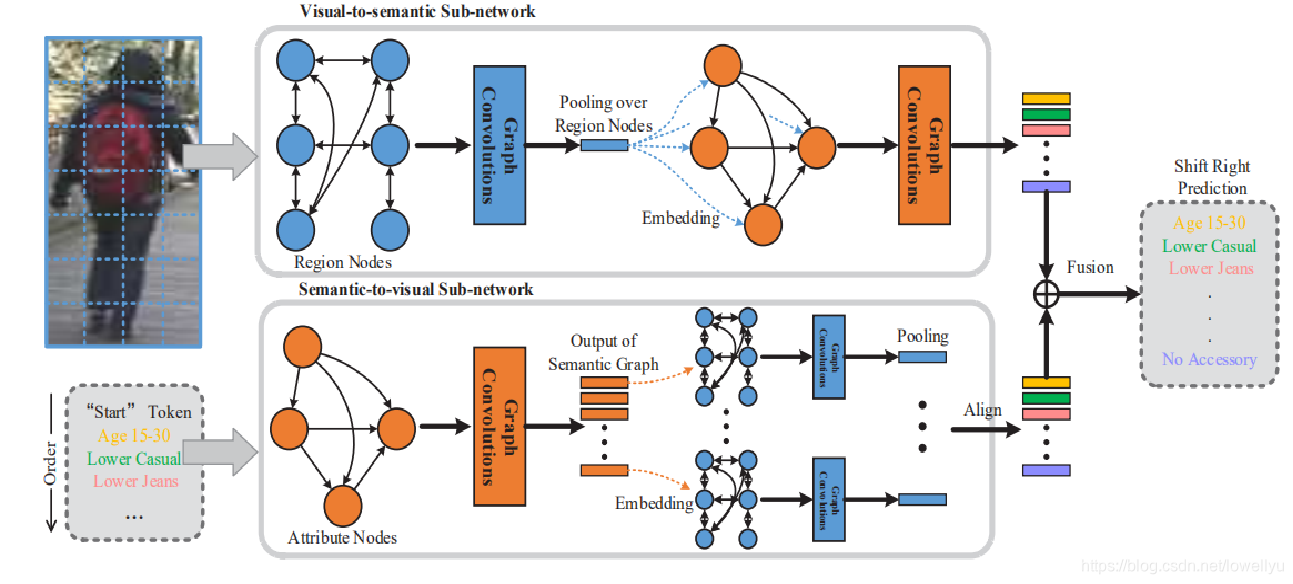
该算法主要包含两个子网络,即视觉-语义子网络和语义-视觉子网络。
在视觉语义子网络中,首先将人体图像分割为固定数量的局部部分,然后构造一个图,图的节点是局部部分,边是不同部分的相似性。与常规的关系建模不同的是,它们既采用零件之间的相似关系,又采用拓扑结构将零件与其相邻区域连接起来。具体过程就是利用空间图学习图像特征表示,获取整个行人图像中不同身体部位之间的空间关系。然后将学习到的空间上下文嵌入到语义空间中,指导有向语义图上的属性之间的关系学习。
在语义视觉子网络中,首先采用有向语义图来捕捉属性之间的语义关系。在每个预测步骤中,将当前属性节点的输出嵌入到空间图中,进行语义感知特征学习,预测下一个属性。
实验:
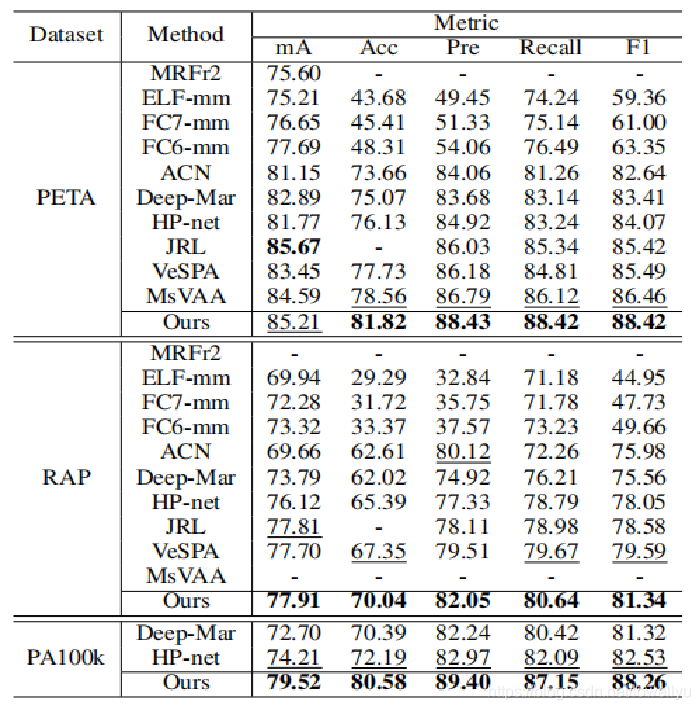
在三个数据集上进行实验
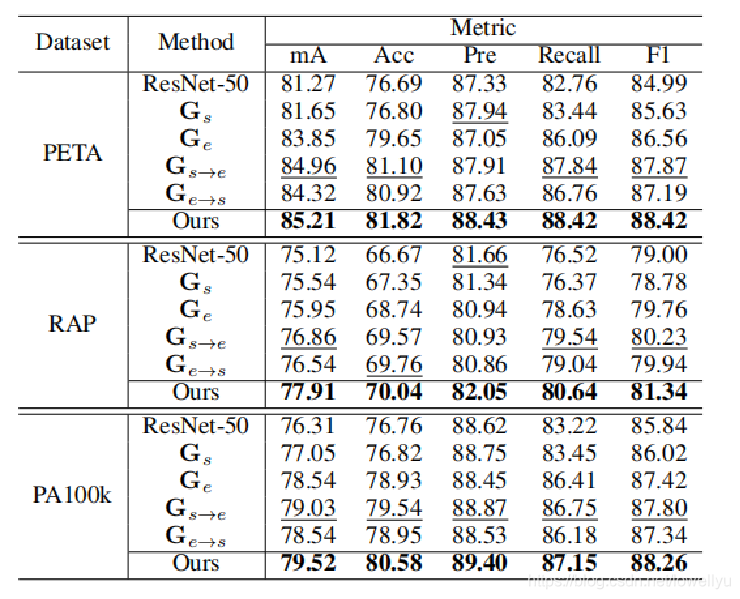
消融实验:

在这两个RAP范例中,基线模型都没有识别出人的行为。这可能是因为它通过上下文线索推断的能力有限。在PA-100k的第一个例子中,人部分被遮挡。这给基线模型带来了干扰,基线模型不能正确地预测性别,并且不能识别眼镜、背包和佩带用品的属性。在PA-100k的第二张图中,人的外貌被斑马线从背景中分散了注意力,导致对上半身属性的错误识别















 1580
1580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









