







一、 算法备案的主体
不同于欧盟的算法治理路径,算法主体责任机制是我国算法问责制的基础。原因在于,我国认为算法是开发者价值观的技术体现,因此可以穿透算法面纱将开发者的责任承担至于前线,对应承担算法安全主体责任,也即预设了算法设计的工具属性。
《算法推荐规定》《深度合成规定》《人工智能暂行办法》三部法规均对算法备案的主体进行了更为详细的规定:

上表显示,三部法规规定的备案主体有一个共同特征——“具有舆论属性或者社会动员能力”,结合《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》第二条的有关规定,“具有舆论属性或者社会动员能力”是指1、从产品形态上看,属于论坛、博客、微博客、聊天室、通讯群组、公众账号、短视频、网络直播、信息分享、小程序等信息服务或者附设相应功能;2、从功能上看,提供公众舆论表达渠道或者具有发动社会公众从事特定活动能力的其他互联网信息服务。
同时根据《算法推荐规定》的有关规定,上述具有备案义务的算法推荐服务提供者应通过互联网信息服务算法备案系统填报服务提供者的名称、服务形式、应用领域、算法类型、算法自评估报告、拟公示内容等信息。其中需要注意的是,同一种算法应用于不同产品或服务时,仅需取得一项备案即可;同一款产品或服务触及多类算法,则应当分别进行多个算法备案。
二、 算法备案的负责机构
《算法推荐规定》第三条对算法备案的负责机构进行了规定,即国家网信部门负责统筹协调全国算法推荐服务相关监督管理工作;国务院电信、公安、市场监管等有关部门依据各自职责负责算法推荐服务监督管理工作;地方网信部门负责统筹协调本行政区域内的算法推荐服务相关监督管理工作;地方电信、公安、市场监管等有关部门依据各自职责负责本行政区域内的算法推荐服务监督管理工作。
三、 算法备案的时间要求及流程
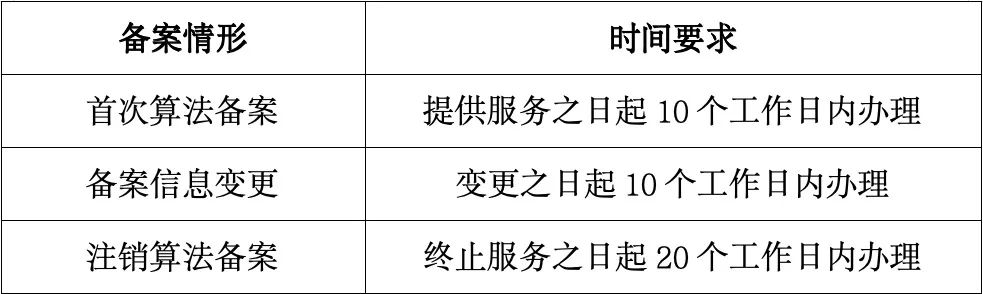
《算法推荐规定》第二十四条将三种算法备案情形,即首次算法备案、备案信息变更和注销算法备案的时间要求进行了规定:
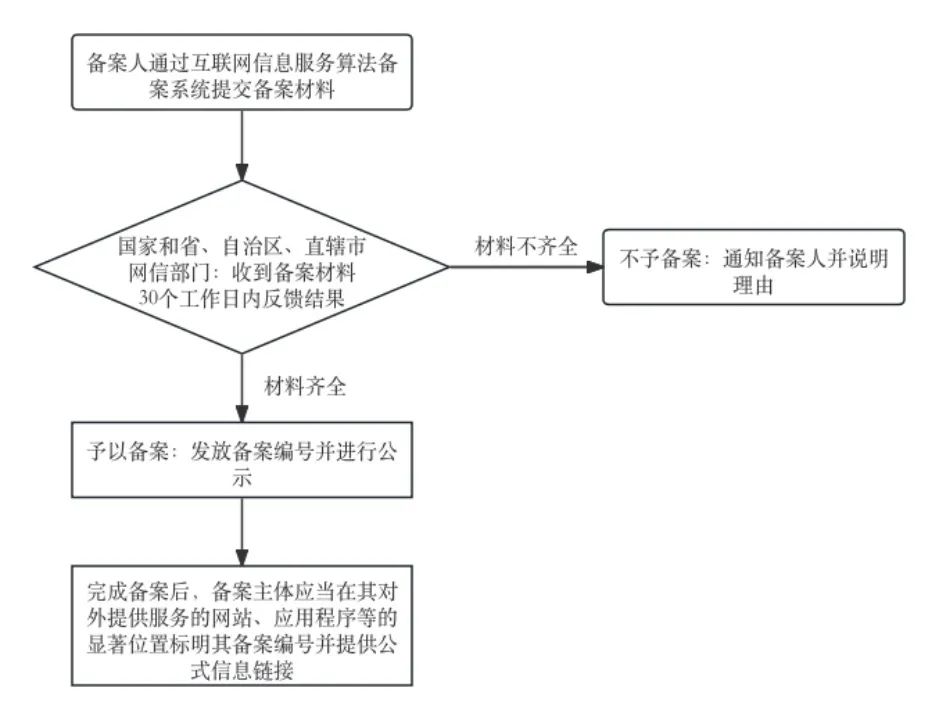
《算法推荐规定》第二十五条、第二十六条对算法备案流程进行了规定:
四、 算法备案平台与需填报的内容
《算法推荐规定》所提到的互联网信息服务算法备案系统是https://beian.cac.gov.cn,备案人在申报时,需要登录该网站,填写申报内容,上传申报材料。
填报内容包括三部分,即算法主体信息、算法信息、产品及功能信息。下表对填报内容做出归纳,详细操作以平台发布的算法备案操作指引《互联网信息服务算法备案系统使用手册》和《互联网信息服务深度合成管理规定》备案填报指南为准。

五、 算法备案不通过的常见原因
根据笔者的实践经验,算法备案不通过原因主要聚焦在以下方面,企业应予以重点关注:
(一)履行数据安全与合规义务
在《数据安全法》、《个人信息保护法》等法律法规实施后,企业对于数据的合法采集、使用、存储义务空前强化。关于算法的数据来源、数据内容、数据的处理方式等均为备案时应予以考虑的重点;并且企业应当建立合法合规的分级分类制度,采取合理必要的控制措施以防止数据受到非授权的篡改和泄露,从而保障数据安全,在数据全生命周期履行安全和合规义务,保证数据处于有效保护和合法利用的状态。
(二)提供透明的算法解释
我国当前算法治理体系以算法透明为内核,对于企业来说履行算法透明义务与保护自身商业秘密同等重要。对此,我们认为对于不同企业的不同算法,所要达成的透明度标准并不相同,应区分场景对待。与具有较强公共服务功能相关的算法,其充分公开排序、选择、检索、推送等规则的义务应越高,反之应有一定程度的降低,在此基础上,用清晰简洁的语言解释算法的工作流程,以达到社会公众感知、了解、明白为标准。
(三)标识合规
深度合成服务提供者对使用其服务生成或者编辑的信息内容,应当采取技术措施添加标识,这不仅是法律法规的强制性规定,也是社会伦理的需求。与结构化数据相比,非结构化的数据更易泄露种族、性别、宗教、特定身份等敏感信息,加剧引发对人口子群体算法偏见的风险,造成社会伦理问题或不安因素。因此设立对模型生成内容进行清洗、准确、可追溯的标识机制是算法备案过程中的重要环节。
六、 不履行算法备案义务的法律后果
根据《算法推荐规定》的有关规定,不履行或未按时履行算法备案义务的,网信部门和电信、公安、市场监管等有关部门依据职责给予警告、通报批评,责令限期改正;拒不改正或者情节严重的,责令暂停信息更新,并处一万元以上十万元以下的罚款;通过隐瞒有关情况、提供虚假材料等不正当手段取得备案的,由国家和省、自治区、直辖市网信部门予以撤销备案,给予警告、通报批评;情节严重的,责令暂停信息更新,并处一万元以上十万元以下罚款。此外,企业变更、终止算法服务的,也应当办理注销备案手续,并作出相关妥善安排。
素材摘自炜衡视点,侵删
















 3200
3200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











