







DistServe
LLM推理的两个阶段
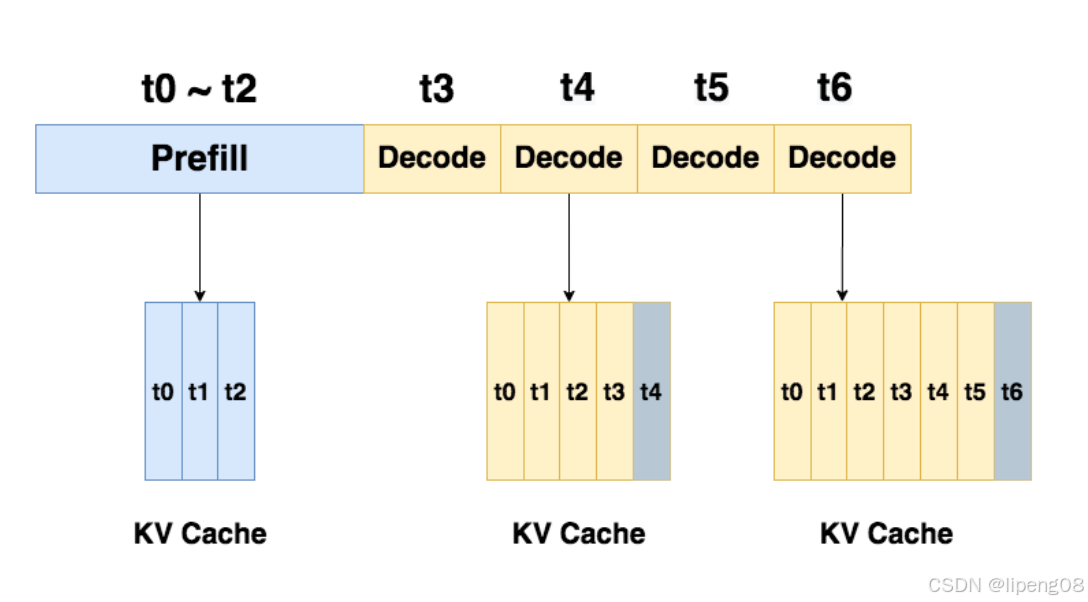
- prefill阶段:根据输入的t0,t1,t2产生第一个token t3
- decode阶段:一个token一个token的产生t4,t5,t6
预填充性能评估指标:TTFT(time to first token)
TTFT 即生成首个标记的时间,是预填充阶段关键评估指标。实际应用中,通常会设定 TTFT SLO,这是对系统的性能要求,只有系统满足该指标,其性能才达标。例如,设定 P90 TTFT SLO 为 0.4 秒,即要求系统 90% 的请求其 TTFT 值小于等于 0.4 秒。
解码性能评估指标:TPOT(time per output token)
TPOT 是生成每个输出标记的时间,是解码阶段重要评估指标。同样存在 TPOT SLO,作为人为制定的系统性能要求。
为什么做KV分离
分离式框架中 prefill 和 decode 不共享 GPU,prefill 实例计算完将 KV Cache 传送给 decode 实例,decode 实例继续推理。如下图所示:Prefill instance 是 prefill 实例,包含完整模型,可能占据 1 或多块 GPU;Decode instance 是 decode 实例,定义与 prefill 实例类似且不与 prefill 实例共享 GPU。
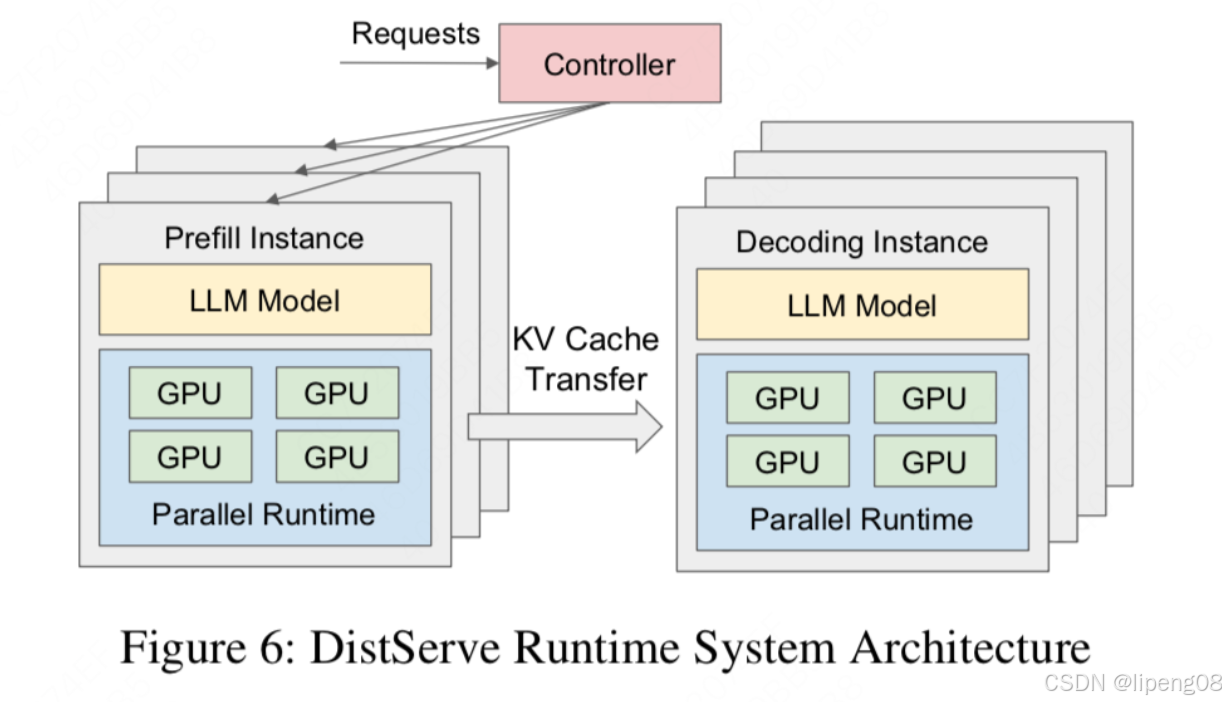
注意:第一直觉是分离式架构相比于合并式架构,多加载了模型副本(耗显存),同时还涉及到gpu间的KV Cache传输(耗时间),应该会弱于合并式架构,这个从个人而言,它并不是反直觉的,存储领域经常有存算分离的思想,虽然增加了通信开销,但是各方向线性扩展,可以达到更好的资源利用率。
考虑下面的这种情况,有一个装着不同状态 requests 的 pool 和一张 GPU,GPU资源的有限性以及prefill 和 decode 在做 fwd 阶段有差异性,在不考虑特殊优化的情况下,同一推理阶段只能全做 prefill 或全做 decode。你要考虑下一个推理时刻是从request列表中选择 prefill 还是 decode?
- 观察到 pool 中塞满等待 prefill 的请求后决定做 prefill,做了prefill,decode生成会被延迟,牺牲 TPOT 以尽量保全 TTFT。
- 将 prefill 和 decode 分开让 TTFT 和 TPOT 各自独立发展优化是否会有更好结果。
DistServe做了一个实验来验证你的猜想,接下来我们就来看这个实验结果。
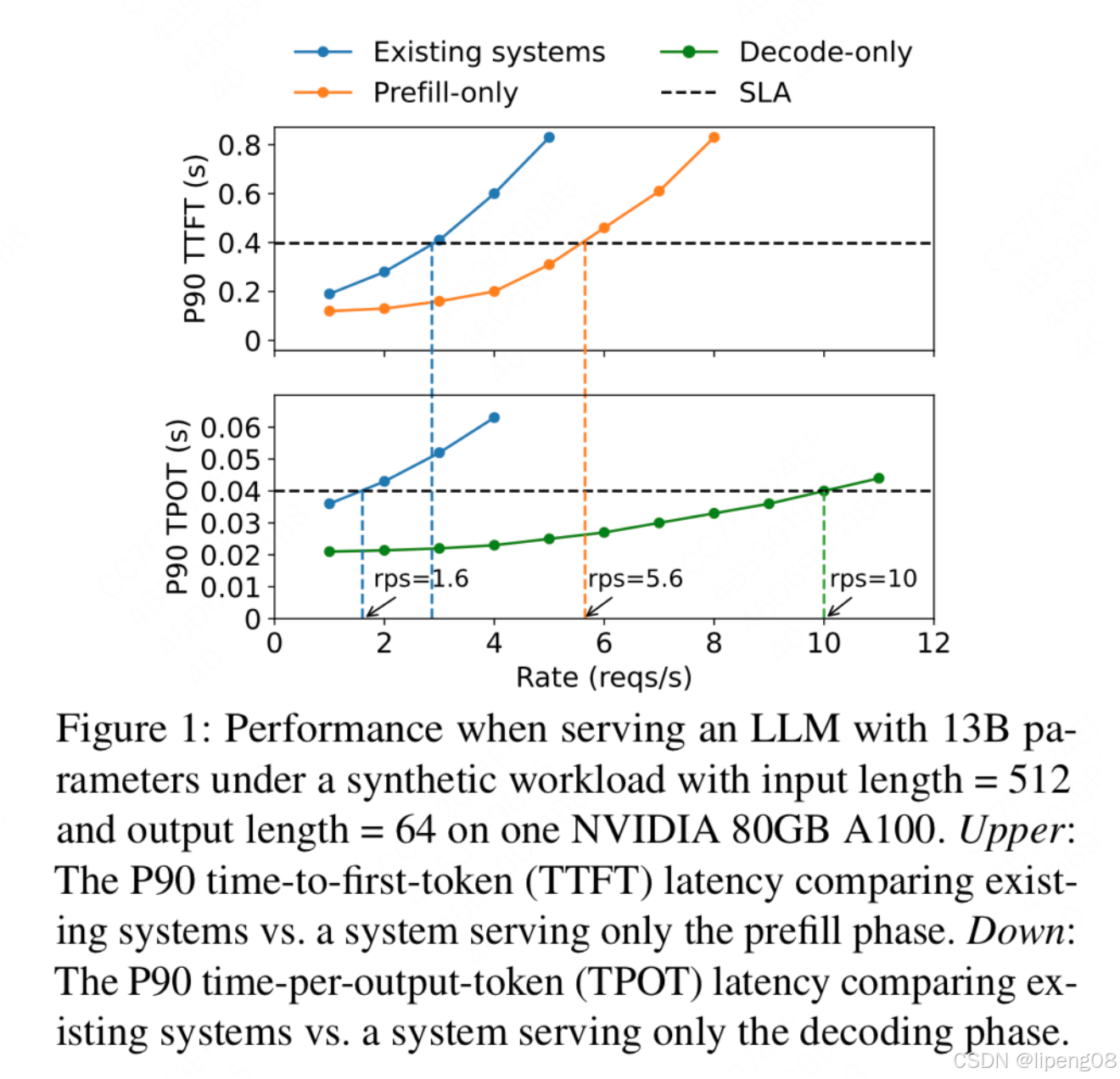
实验配置:
- 1张A100 80G的gpu
- 13B LLM,input_length = 512, output_length = 64
SLO(人为定义的系统性能达标要求):
- P90 TTFT = 0.4s,人为定义在prefill阶段90%的请求的TTFT必须达到0.4s(上面那张图黑色虚线部分)
- P90 TPOT = 0.04s,人为定义在decode阶段90%的请求的TPOT必须达到0.04s(下面那张图的黑色需要部分)
上图解读
- 蓝线:将蓝线和我们设定的SLO(黑虚线)对比发现,如果我们同时达到设定好的TTFT SLO和TPOT SLO,我们的最大rps = 1.6,我们也记这个指标为goodput。
- 黄绿线: 一次实验只让它处理需要做prefill的请求(黄线),一次实验只让它处理需要做decode的请求(绿线),我们得到在这块gpu上只做prefill时,它的goodput=5.6;只做decode时,它的goodput=10。
一张卡只做prefill或者只做decode的goodput,都要比它既做prefill又做decode的goodput要高,这也验证了我们前文的猜想:合并式架构可能会同时损害TTFT和TPOT。不考虑 KV Cache传输和模型加载的开销,使用3张卡,2张prefill,1张decode,分离架构下可以达到的goodput是10,也就是单卡3.3,相比于合并架构下单卡的1.6的2.1倍!也就是说,看起来分离架构好像更消耗资源了,但是其实并不是,吞吐量反而更高,更省卡。
分离架构下prefill/decode的优化方向
在确定使用PD分离架构下,会有哪些优化方向?
算力与存储的独立优化
总结:
- prefill 阶段:有计算受限性质,在请求流量大且用户 prompt 长时明显。prefill 阶段算完 KV cache 发给 decode 阶段后理论上不再需要此 KV cache,也可采用 LRU 等策略管理而非直接清除。
- decode 阶段:有内存带宽受限性质,因 token by token 的生成方式需频繁从存储中读取 KV Cache,意味着要尽可能保存 KV cache。
这两个阶段的差异意味着可以使用的不同的硬件满足不同阶段的需求,在分离式框架下,计算和存储可以朝着两个独立的方向做优化。
内存和计算 bound的分析
batching策略的独立优化
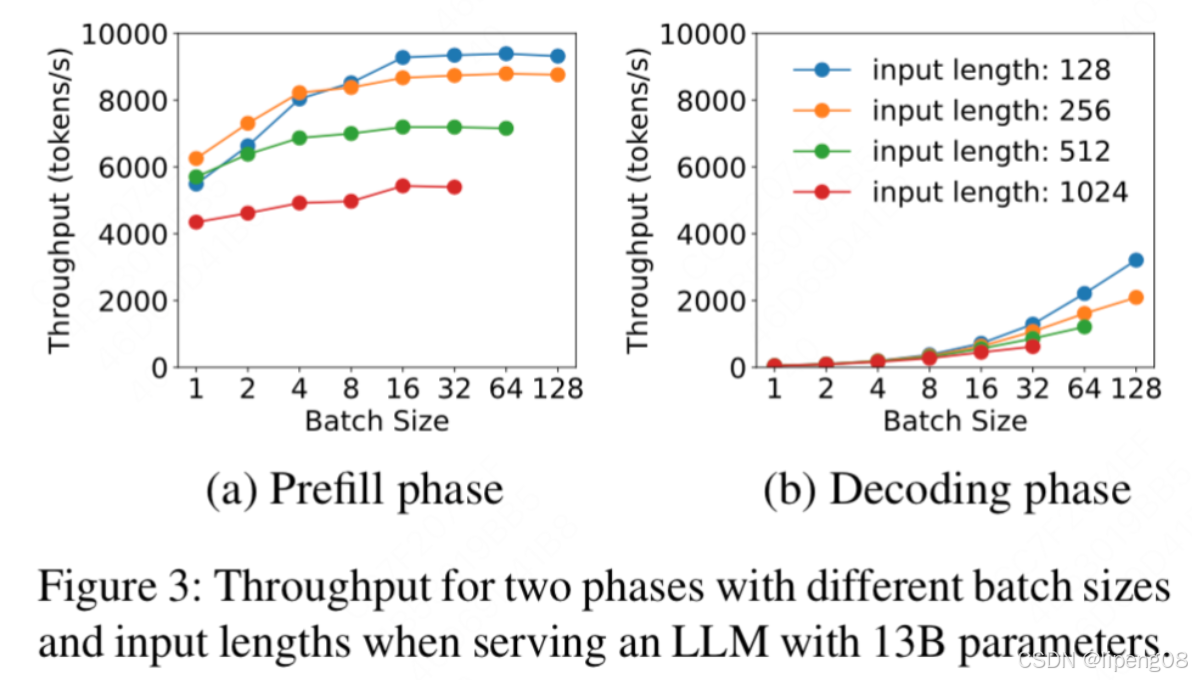
总结:
- 实验比较不同 batch size 下 prefill 和 decode 阶段吞吐量情况,不同颜色线条代表不同 input_length下的吞吐量(token/s,代表每秒处理的token数量,不同颜色的线代表不同的input length)
- prefill 阶段是 compute-bound,随 batch size 增加吞吐量增长趋势趋于平缓,到达GPU资源上限。
- decode 阶段是 memory-bound,随 batch size 增加,其计算的强度增加,吞吐量增长趋势显著。
结论是 prefill 和 decode 不适合用一样的 batching 策略,两者分离后可在 batching 上继续优化。
并行策略的优化
https://aijishu.com/a/1060000000472929

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









