






一. SFT微调是什么
-
在大模型的加持下现有的语义理解系统的效果有一个质的飞跃;相对于之前的有监督的Pre-Train模型;大模型在某些特定的任务中碾压式的超过传统nlp效果;由于常见的大模型参数量巨大;在实际工作中很难直接对大模型训练适配特定的任务
-
SFT (Supervised fine-tuning) 有监督微调 意味着使用有标签的数据来调整一个已预训练好的语言模型(LLM)使其更适应某一特定任务;通常LLM的预训练是无监督的,但微调过程往往是有监督的
-
在大模型应用中,SFT指令微调已成为预训练大模型在实际业务应用最重要的方式。众多垂直领域模型,都是在预训练模型的基础上,通过针对性的SFT指令微调,更好地适应最终任务和对齐用户偏好;现有的对话系统或者推荐系统中有较多的语义理解任务需要进行指令微调
-
SFT主要是激发模型在预训练中已学到的知识、让模型学习业务所需要的特定规则、以及输出格式稳定下文中会给出具体的例子
二、SFT微调的方案
-
参数高效微调(PEFT) Prefix/Prompt-Tuning,Adapter-Tuning、P-Tuning、LoRA、QLoRA
-
优点:轻量化,低资源
-
缺点:模型参与训练参数较少,部分任务微调效果可能会不及预期
-
LoRA原理
-
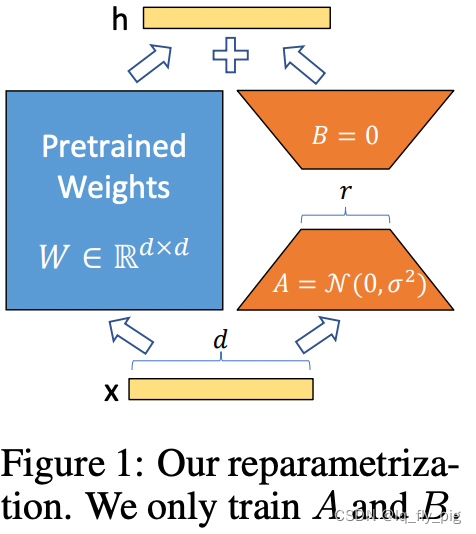
低秩分解来模拟参数的改变量,使用比较小的参数来实现大模型的间接的训练
-
原始的PLM旁边增加一个新的通路,通过A矩阵和B矩阵进行相乘
-
第一个A矩阵进行降低维度,第二个矩阵B进行升维度,中间层维度为r
-
维度d经过fc 降低到r ,再从r 映射到d (其中 r << d)
-
矩阵的计算就是从 dxd 变成 dxr + rxd (参数量减少很多)
-
在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将PLM跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx
-
第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响
-
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源
-

-

-
-
LoRA微调相关代码请参考https://github.com/hiyouga/LLaMA-Factory
-
三、SFT微调的训练心得经验
-
遇到的困难和挑战
-
SFT数据从0到1构建,怎么获取挖掘线上的badcase,补充筛选SFT高质量的数据
-
NLG过程中的幻觉 大模型的胡编乱造
-
prompt的效果迭代和Lora微调的超参数的调试
-
实际项目落地时候模型的推理加速(eg:大模型的量化手段、流量请求时候的预剪枝,减少大模型的请求)
-
-
效果优化思路
-
pompt的迭代
-
prompt优化主要在训练阶段,用于增强指令的多样性,让模型更好的理解指令
-
预测阶段的prompt优化主要用于无法进行finetune的场景,在开源的基座大模型上进行适配
-
对于特定下游任务,预测阶段建议与训练阶段保持一致或者接近的prompt
-
适当构建few shot 及COT(Chain of Thought) 数据加入训练,可以有助于模型的指令理解
-
-
prompt的例子
输入是:打开音乐和空调并帮我播放我喜欢的歌曲 输出是: 打开音乐、打开空调、播放我喜欢的歌曲
-
实际工作中的心得体会
-
prompt尽量给出指定模型扮演的角色,比如nlu理解任务时候说是语音助手,泛化数据的时候是语言大师等等
- 越详细越好,给到的定义越细越好,需要给出关于任务需求的详细信息,比如上面的分句改写任务,需要定义例子的输入和输出,给出详细的例子,还有嘱咐清楚
-
针对任务给出几个示例,符合few-shot 过程,有助于模型的很好理解;使用分隔符清晰的区分输入的不同部分
-
建立惩罚机制,比如 做错了扣分,不要胡编乱造等等
-
prompt中可以尝试让大模型step by step的先思考再决策提升效果
-
-
结论
-
结合ICL上下文学习,在prompt中加入输入输出对,让LLM能够通过理解这些演示样例去进行预测。
-
在prompt里增加一些角色信息相关的内容,让 AI 生成的内容更符合我们的需求。
-
输出格式尽可能是json、xml等等这样的结构化数据;便于后续的结果的解析和输出
-
优质Prompt能够提高模型的精度。通过精心设计的提示词或问题,可以引导模型关注到输入文本的关键信息,从而减少误判和误差
-
优质Prompt能够提高模型的泛化能力。在面对未曾训练过的场景时,优质Prompt可以帮助模型更好地适应新环境,减少过拟合现象
-
优质Prompt能够提高模型的可解释性。通过分析优质Prompt的输出结果,我们可以更好地理解模型的决策过程和推理逻辑,从而更好地评估模型的效果和可靠性
-
-
版本2
'你是一个专业的车载语音助手,任务是协助处理用户的文本输入,并将其抽取为触发条件conditions和执行指令actions两项内容 \ 你需要遵循下列这些注意事项 \ 1. 触发条件代表执行指令执行的触发时机,如果用户输入中不包含这部分,则不用输出conditions\ 2. 执行指令代表用户下达的执行指令,文本输入中一定包含这部分内容。 \ 3. 用户输入中可能会包含多个触发条件和执行指令,请仔细做好内容的识别和拆分,并以JSON格式输出 \ 4. 用户输入是由语音识别转写而来的,可能口语化、重复啰嗦等问题,在不影响语义的情况下,请把触发条件conditions中的`时`,`的时候`之类的词语,以及执行指令actions中的语气词、连词去掉(如`还有`,`同时`,`请帮我`等等),保证抽取结果尽量精简。 \ 5. 处理文本时应遵循用户的意图,不能编造和虚构不存在的内容;不需要解释和过程,严格按照示例的输出形式给出结果。如果输出指令不正确,则你将会被扣分! \ 下面是4个示例的输入输出:\ 输入:上车的时候自动播放QQ音乐 \ 输出:{"conditions":["上车"], "actions":["播放QQ音乐"]} \ 输入:每周五晚上下班时帮我导航回杭州的家调节空调再让NOMI给我周末的问候 \ 输出:{"conditions":["每周五晚上", "下班"], "actions":["导航回杭州的家", "调节空调", "播报周末的问候"]} \ 输入:打开车窗和空调还有香氛关闭阅读灯还有车门 \ 输出:{"actions":["打开车窗", "打开空调", "打开香氛", "关闭阅读灯", "关闭车门"]} \ 输入:打开座椅加热和通风再帮我设置导航目的地为人民广场 \ 输出:{"actions":["打开座椅加热", "打开座椅通风", "设置导航目的地为人民广场"]} \ ----示例结束---- \ 请你协助处理下面这一条用户输入,并直接给出JSON形式的输出 \ 输入:%s \ 输出:' % query -
版本1
经过多次效果迭代,版本2相对比版本1中的prompt,大模型的效果提升2%'你是智能车载语音助手机器人,你的任务是,基于用户输入的文本进行分句和改写 需要把输入文本中多个意图的句子切分开,用逗号分隔,如果文本中没有多个意图的话,那就不需要进行切分。以下是需要进行切分和改写的句子:%s' % query
-
-
PEFT微调LoRA超参数的迭代
-
学习率设置
- 学习率是一个非常重要的参数 ,如果学习率设置不当,很容易让你的SFT模型效果较差。SFT数据集不是特别大的情况下,建议设置较小学习率,一般设置为pre-train阶段学习率的0.1左右,如在pre-train阶段的学习率为3e-4,则SFT学习率设置为3e-5
- warmup_ratio
- 通常pre-train训练的warmup_ratio 0.01~0.015之间,warmup-steps在2000左右。在SFT的时候,建议使用更小的ratio,因为相较于pre-train,SFT样本非常小,较小warmup_ratio可以使模型收敛更平滑。但如果你的学习率设置较大,那可以增大你的warmup_ratio,两者呈正相关
-
-
-
四、总结
-
SFT的主要是使用于领域相关能力的增强,如果通过大模型通用能力,例如embedding、prompt提取、Lang Chain等知识库的形式可以解决的,没有必要再进行SFT微调
-
通用大模型泛化性好,精度不够,SFT后的模型领域体验更佳,两者可能是并行存在较好
-
SFT中仅使用领域数据,会导致通用能力下降以及安全相关回复能力的下降甚至丢失,因此需要人工梳理,增加数据的多样性的同时并把握好SFT数据的质量,质量非常重要
-
SFT不要训练较多轮次,比如10万个样本2-3个epoch内为佳,2~5万个样本 一般是4-5个 epoch 并且领域增强的SFT数据不需要太多,质量一定要把握好,一般的领域总结回复的任务几百条数据即可( 个人经验 ),视情况而定;小数据量可以适当增大epoch,让模型充分收敛。
-
通用数据和领域数据增加数据之间的比例(7:1)左右
-
SFT数据质量的筛选数据质量可以通过ppl、reward model,文本质量分类模型等方式进行初步评估。经过人工进行后续筛选
-
过高的epoch可能会带来通用NLP能力的遗忘,需要根据实际需求核定,若您只需要下游能力提升,则通用NLP能力的略微下降影响不大
五、相关refer
-
https://zhuanlan.zhihu.com/p/692892489
-
https://zhuanlan.zhihu.com/p/635791164
-
https://zhuanlan.zhihu.com/p/649277113
-
https://zhuanlan.zhihu.com/p/662657529
-
https://zhuanlan.zhihu.com/p/682604566
-
https://hub.baai.ac.cn/view/31947
-
https://developer.baidu.com/article/details/2587180
-
https://zhuanlan.zhihu.com/p/676723672?utm_psn=1727814727898763264
-
https://cloud.baidu.com/doc/WENXINWORKSHOP/s/9liblgyh7















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









