







文章目录
- MulDE: Multi-teacher Knowledge Distillation for Low-dimensional Knowledge Graph Embeddings
- Knowledge Transfer via Dense Cross-Layer Mutual-Distillation
- Distilling a Powerful Student Model via Online Knowledge Distillation
- Distill on the Go: Online knowledge distillation in self-supervised learning
- Improving Object Detection by Label Assignment Distillation
- Online Model Distillation for Efficient Video Inference
- Preservation of the Global Knowledge by Not-True Distillation in Federated Learning
- FedX: Unsupervised Federated Learning with Cross Knowledge Distillation
- Learning Efficient Object Detection Models with Knowledge Distillation
- Big Self-Supervised Models are Strong Semi-Supervised Learners
- Class-Balanced Distillation for Long-Tailed Visual Recognition
MulDE: Multi-teacher Knowledge Distillation for Low-dimensional Knowledge Graph Embeddings
MulDE:用于低维知识图嵌入的多教师知识提取
论文:https://arxiv.org/pdf/2010.07152v4.pdf
代码:No code implementations yet
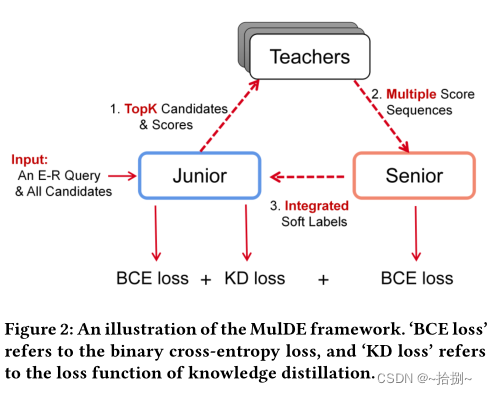
预训练了多个低维双曲KGE模型,提出利用多教师知识提取进行知识图嵌入的新框架MulDE,它包括多个低维双曲KGE模型(教师)和两个学生组件(junior和senior)。
在一次迭代中,Junior组件基于e-r查询进行初步预测,并选择那些无法区分的实体(top-K)询问多名教师。然后,Senior组件可以根据初级的反馈不断调整参数,并通过两种机制(关系特定缩放和对比注意力)自适应地生成软标签。最后,Junior接收软标签,并使用知识蒸馏损失来更新其参数。
Knowledge Transfer via Dense Cross-Layer Mutual-Distillation
通过密集跨层相互蒸馏实现知识转移
论文:https://arxiv.org/pdf/2008.07816v1.pdf
代码:https://github.com/sundw2014/DCM
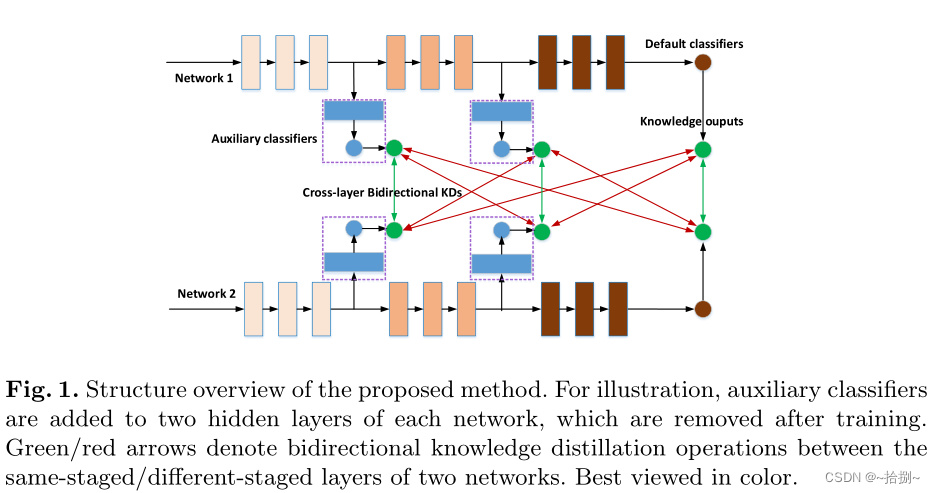
深度相互学习(DML)提出了一种双向KT策略,表明学生网络也有助于改善教师网络。
在本文中,提出密集跨层相互蒸馏(DCM),这是一种改进的双向KT方法,其中教师和学生网络从头开始协同训练。为了增强知识表示学习,在教师和学生网络的某些隐藏层中添加了辅助分类器(将ACLF添加到网络的下采样层)。为了提高KT性能,我们在附加分类器的层之间引入了密集的双向KD操作。在训练之后,所有辅助分类器都被丢弃,因此没有额外的参数被引入最终模型。
Distilling a Powerful Student Model via Online Knowledge Distillation
通过在线知识提取提取强大的学生模型
论文:https://arxiv.org/pdf/2103.14473v3.pdf
代码:https://github.com/SJLeo/FFSD
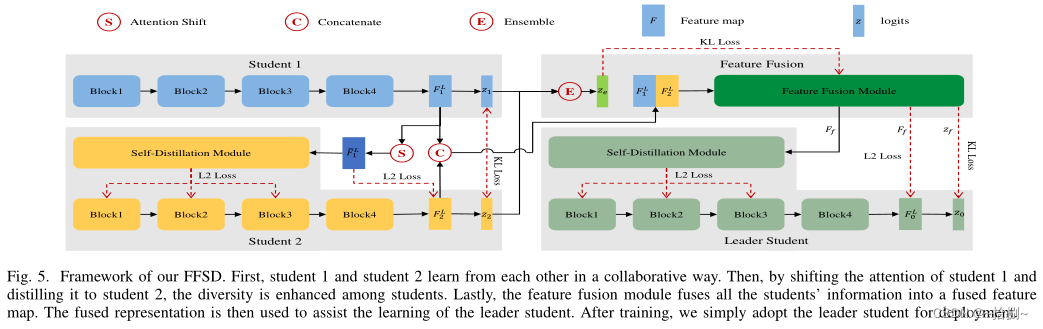
FFSD包括两个关键组件:特征融合和自蒸馏。
FFSD将学生分为领导学生和普通学生。特征融合模块将来自所有普通学生的特征图的拼接转换为融合的特征图。融合表示用于辅助领导学生的学习。
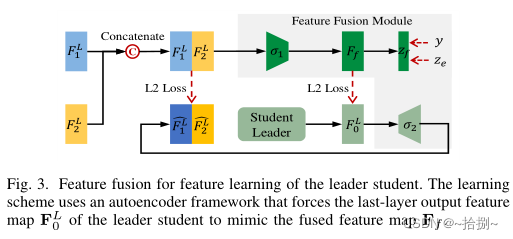
为了使领导者学生能够吸收更多多样的信息,设计了一种增强策略来增加学生的多样性。此外,采用自蒸馏模块将深层的特征图转换为浅层的特征图。然后,鼓励较浅的层模仿较深层的转换特征图,这有助于学生更好地概括。
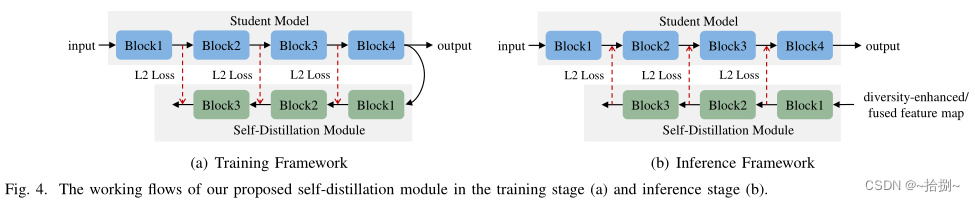
经过训练,我们简单地采用了领导者学生,与普通学生相比,领导者学生的表现更出色,而不会增加存储或推理成本。
Distill on the Go: Online knowledge distillation in self-supervised learning
自我监督学习中的在线知识蒸馏
论文:https://arxiv.org/pdf/2104.09866v2.pdf
代码:https://github.com/NeurAI-Lab/DoGo
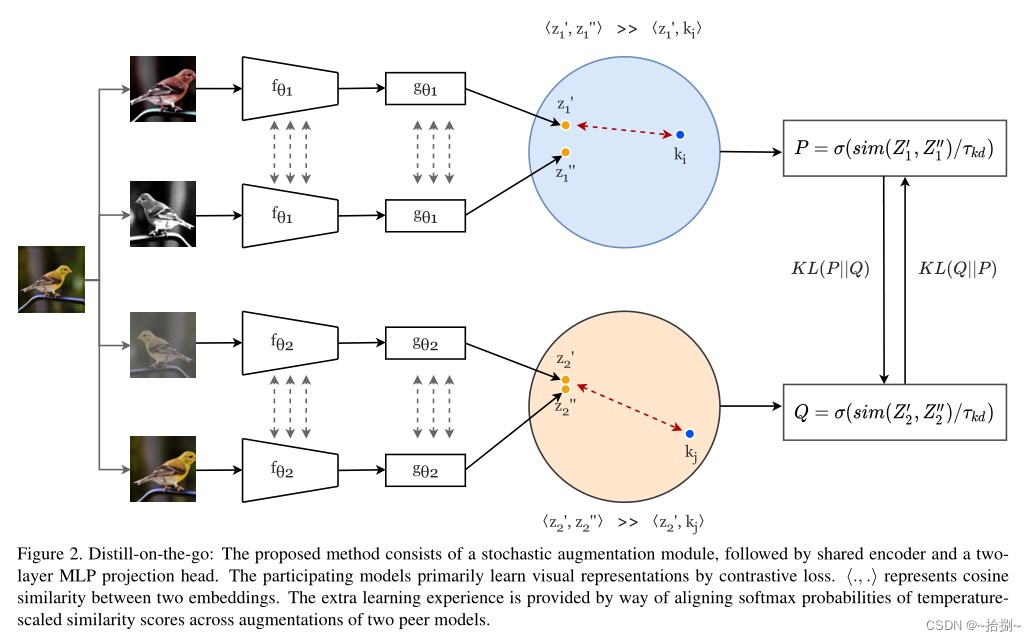
为了解决较小模型的自监督预训练问题,提出了Distille on the Go(DoGo),这是一种完全自监督(无标签)的学习方法,使用单阶段在线知识蒸馏来提高较小模型的表示质量。采用深度相互学习策略,其中两个未经训练的模型,通过解决借口任务相互协作学习。具体来说,每个模型都是使用自监督学习和蒸馏来训练的,蒸馏将每个模型的相似性得分的softmax概率与对等模型的相似度得分的softmax概率对齐(用KL散度)。
通过对比语义相似(正)和不相似(负)的数据样本对来学习视觉表示,从而通过潜在空间中的对比损失使相似对具有最大一致性。对比度损失促使相似对的表示接近,而不同对的表示在潜在空间中更正交。通过使用旋转、高斯噪声和颜色抖动随机增强相同样本获得类似的对。
f θ ( ⋅ ) f_θ(\cdot) fθ(⋅)一个编码器网络,如ResNet-50, g θ ( ⋅ ) g_θ(\cdot) gθ(⋅)一个具有ReLU非线性的两层感知器, g θ ( f θ ( ⋅ ) ) g_θ(f_θ(\cdot)) gθ(fθ(⋅))应该学会最大化正嵌入对 < z ′ , z ′ ′ > <z',z''> <z′,z′′>之间的相似性,同时推开负嵌入对 < z ′ , k ′ ′ > <z',k''> <z′,k′′>。
Improving Object Detection by Label Assignment Distillation
利用标签分配蒸馏改进目标检测
论文:https://arxiv.org/pdf/2108.10520v3.pdf
代码:https://github.com/cybercore-co-ltd/CoLAD
目标检测中的标签分配旨在将目标(前景或背景)分配给图像中的采样区域。与图像分类的标签不同,由于对象的边界框并没有得到很好的定义。
标签分配蒸馏(LAD):使用教师网络为学生生成标签。通过两种方式实现:(1)使用教师的预测作为直接目标(软标签);(2)通过教师动态分配的硬标签(LAD)。
实验结果证明:
(i)LAD比软标签更有效,但它们是互补的。
(ii)使用LAD,较小的教师也可以显著提高较大的学生,而软标签则不能。
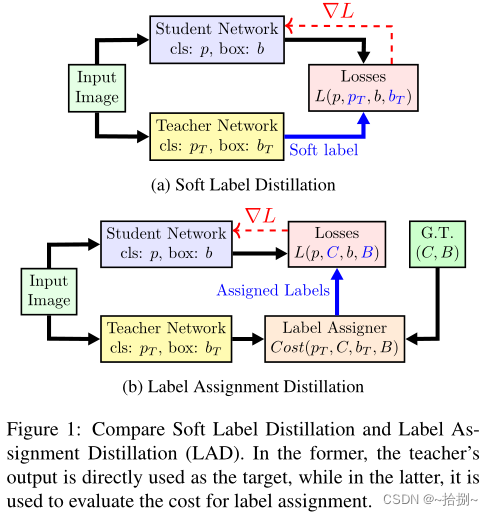
图1(a),对于对象检测,分类和定位任务通常是独立提取的,无论是否使用基本事实。
图1(b),LAD,教师的分类和定位预测和基本事实在被间接提取到学生之前被融合到成本函数中。
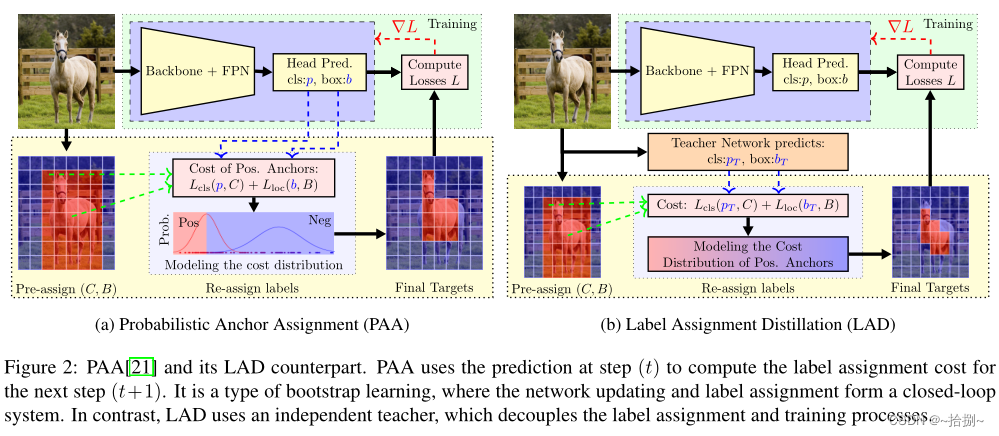 图2(a),概率锚分配PAA,使用步骤
t
t
t 处的预测来计算下一步骤
t
+
1
t+1
t+1 的标签分配成本,网络更新和标签分配形成了一个闭环系统。
图2(a),概率锚分配PAA,使用步骤
t
t
t 处的预测来计算下一步骤
t
+
1
t+1
t+1 的标签分配成本,网络更新和标签分配形成了一个闭环系统。
图1b(b),从LAD的角度来看,网络本身可以被视为老师,也就是说,当前的预测被用来为下一个学习步骤分配标签。
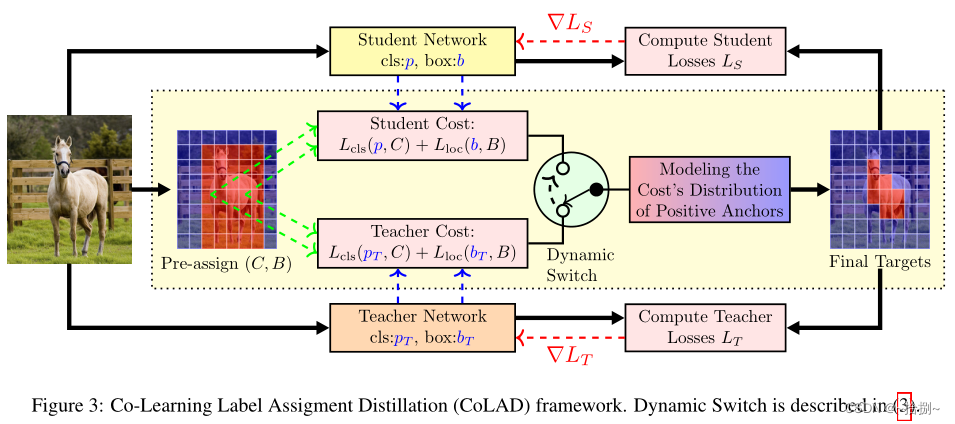
共同学习LAD:使用两个类似于LAD的独立网络,它们都不必经过预训练,两个网络同时从头开始学习,根据他们的表现指标ρ动态切换教师和学生的角色。
ρ
ρ
ρ的标准:标准/平均分数
(
ρ
σ
/
µ
)
(ρ_{σ/µ})
(ρσ/µ)和Fisher分数
(
ρ
F
i
s
h
e
r
)
(ρ_{Fisher})
(ρFisher)
Online Model Distillation for Efficient Video Inference
用于高效视频推理的在线模型蒸馏
论文:https://arxiv.org/pdf/1812.02699v2.pdf
代码:https://github.com/josephch405/jit-masker
使用模型提取技术(使用高成本教师的输出来监督低成本的学生模型)来将准确、低成本的语义分割模型转化为目标视频流。不是在视频流的离线数据上学习专门的学生模型,而是在直播视频上以在线方式训练学生,间歇性地运行老师,为学习提供目标。
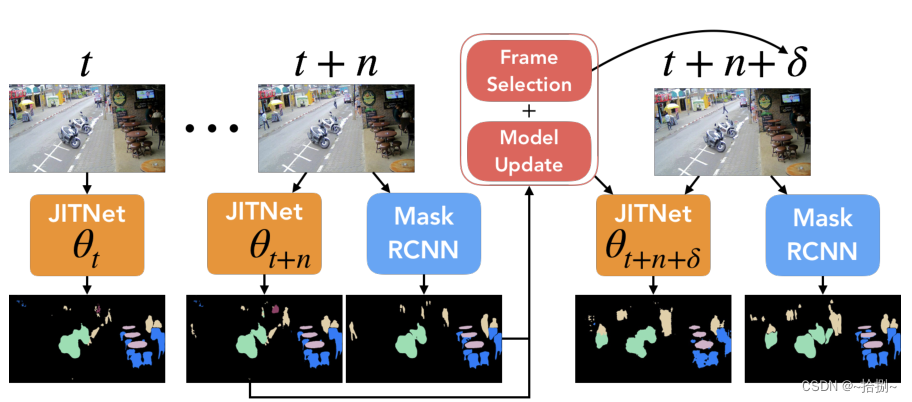
低成本的学生模型(JITNet)的任务是生成高分辨率的每帧语义分割。为了保持高精度,随着新帧的到来,周期性地使用教师模型(MRNN)输出作为学习目标,以调整学生并选择下一帧来请求监督。
为了在实践中提高在线蒸馏的效率:
1)使用快速推理和快速适应的学生网络JITNet,它是一个紧凑的编码器[,由三个修改的ResNet块组成。
2)为了生成用于训练的目标标签,使用MRCNN提供的高于置信阈值的实例掩码,并将它们转换为像素级语义分割标签。未报告实例的所有像素都标记为背景。这会导致背景比例高,降低学生模型的快速学习能力,因此通过对每个预测实例边界框(扩展15%)中的像素损失进行加权,使其比框外的像素高五倍,来缓解这一问题。这种加权将训练重点放在物体边界附近的具有挑战性的区域和小物体上。利用这些加权标签,使用加权交叉熵损失和梯度下降来计算用于更新模型参数的梯度。
3)确定何时以及如何在新框架到来时向教师索要标签。利用先前框架上的教师标签,不仅用于培训,还用于验证。基于最近的学生准确性提高(或降低)教师监督率。JITNet精度低于期望的精度阈值(平均IoU),使用教师预测进行更新。对JITNet模型进行训练,直到其达到设定的精度阈值(athresh)或每帧更新迭代的上限(umax)。一旦训练阶段结束,如果JITNet达到准确度阈值,则教师跑步的步幅将加倍;否则,它将减半(以最小和最大步幅为界)。
Preservation of the Global Knowledge by Not-True Distillation in Federated Learning
通过联合学习中的非真实蒸馏来保存全球知识
论文:https://arxiv.org/pdf/2106.03097v5.pdf
代码:https://github.com/Lee-Gihun/FedNTD
在联合学习中,通过聚合客户端的本地训练模型来协作学习强大的全局模型。遗忘可能是联合学习的瓶颈,全局模型会忘记前几轮的知识,而局部训练会导致忘记局部分布之外的知识。假设解决向下遗忘将缓解数据异质性问题,提出联邦非真蒸馏(FedNTD),为非真类保留了局部可用数据的全局视角。
跨客户端的本地数据是从异构的底层分布中提取的;因此,本地可用的数据不能代表整体的全局分布,这被称为数据异质性。
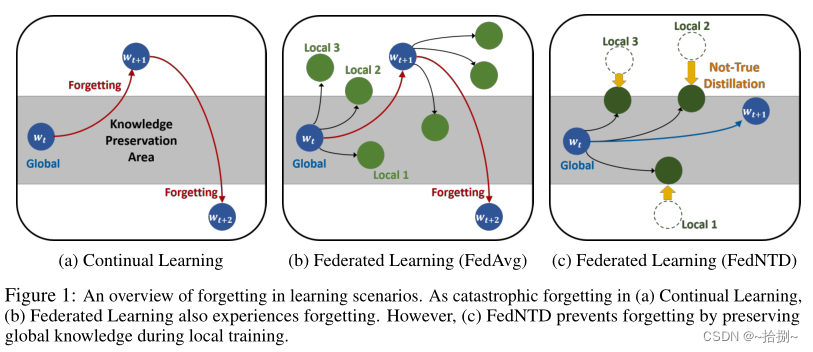
图1(a):在持续学习中,由于每个任务的数据分布不同,对任务序列的学习往往会导致灾难性的遗忘[36,40],从而适应新任务会干扰对以前任务很重要的参数。
图1(b):全局模型的预测在多轮通信中高度不一致,大大降低了预测先前模型最初预测良好的某些类的性能。由于仅仅对局部模型求平均值无法恢复,全局模型很难保存以前的知识,与局部分布之外的区域相对应的全局知识很容易被遗忘。
图1(c):FedNTD通过在本地训练期间保存全局知识来防止遗忘。
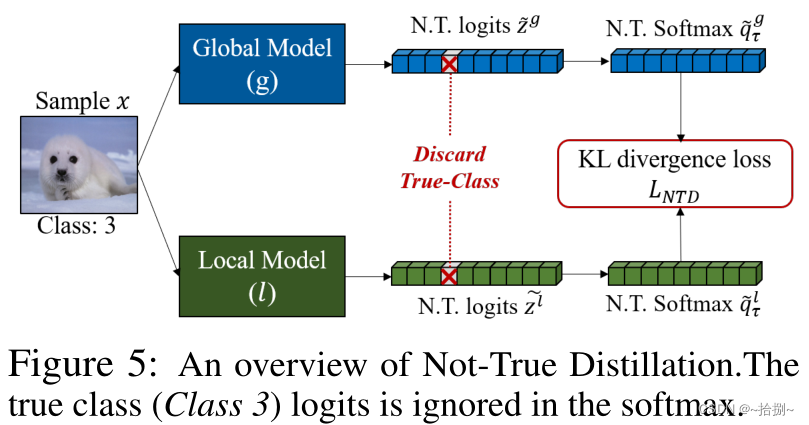
FedNTD通过交叉熵损失
L
C
E
L_{CE}
LCE和非真实蒸馏损失
L
N
T
D
L_{NTD}
LNTD之间的线性组合损失函数
L
L
L 进行局部侧蒸馏
FedX: Unsupervised Federated Learning with Cross Knowledge Distillation
FedX:具有交叉知识蒸馏的无监督联合学习
论文:https://arxiv.org/pdf/2207.09158v1.pdf
代码:https://github.com/sungwon-han/fedx
无监督的联邦学习框架FedX,从去中心化和异构的本地数据中学习无偏表示,采用了以对比学习为核心组件的双边知识提取,使联邦系统能够在不需要客户端共享任何数据特征的情况下运行。它的适应性架构可以用作联邦设置中现有无监督算法的插件模块。
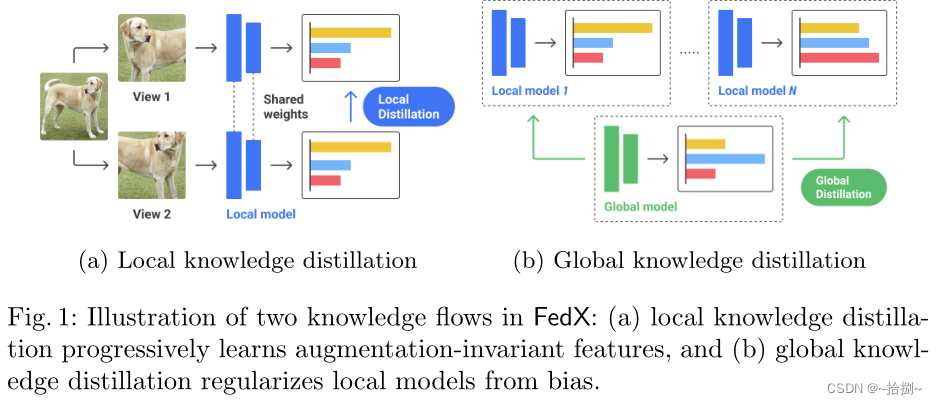
图1(a):局部知识提取,最大化了同一数据实例的两个不同视图之间的嵌入相似性,同时最小化了其他实例的嵌入相似度。该过程由对比损失定义。我们设计了一个额外的损失,通过软标记来放松对比损失。软标签被计算为锚点和随机选择的实例之间的相似性,称为关系向量。我们最小化两个不同视图的关系向量之间的距离,以转移结构知识并实现快速训练速度——这个过程受到关系损失的调节。
图1(b):全局知识蒸馏,将全局模型传递的样本表示视为一个替代视图,该视图应放置在局部模型的嵌入附近。这一过程也受到对比损失和关系损失的调节。并行优化允许模型学习语义信息,同时通过正则化消除数据偏差。这些目标不需要额外的通信轮次或昂贵的计算。此外,它们不共享敏感的本地数据或使用外部数据集。
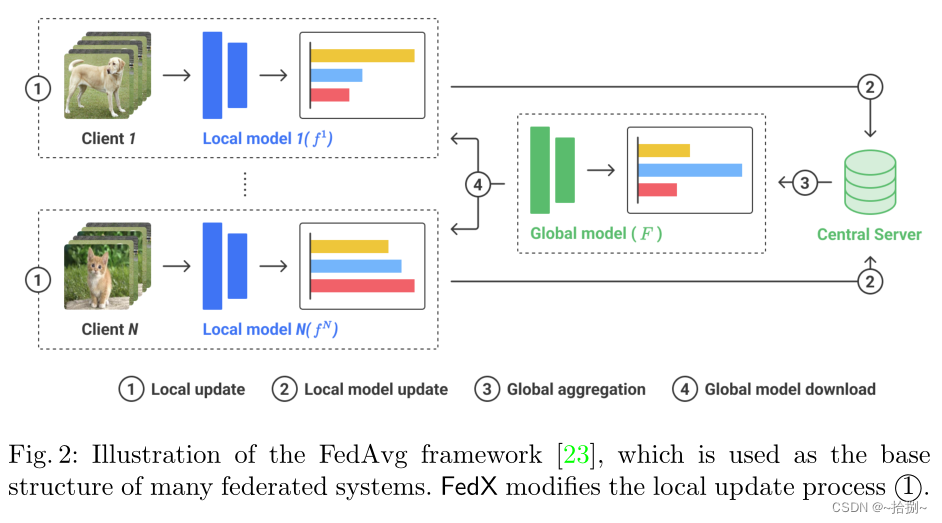 使用FedAvg作为底层结构,数据流如图2所示。每轮运行四个流程:(1)局部更新是当每个局部客户端训练具有
E
E
E个局部时期的数据
D
m
D^m
Dm的模型
f
m
时
f^m时
fm时;(2) 当客户端与服务器共享训练的模型权重时,进行本地模型上传;(3)当中央服务器对接收到的模型权重进行平均并生成共享的全局模型
F
F
F时,进行全局聚合;(4)全局模型下载是指客户端将其本地模型替换为下载的全局模型(即平均权重)。这些过程运行
R
R
R轮通信。
使用FedAvg作为底层结构,数据流如图2所示。每轮运行四个流程:(1)局部更新是当每个局部客户端训练具有
E
E
E个局部时期的数据
D
m
D^m
Dm的模型
f
m
时
f^m时
fm时;(2) 当客户端与服务器共享训练的模型权重时,进行本地模型上传;(3)当中央服务器对接收到的模型权重进行平均并生成共享的全局模型
F
F
F时,进行全局聚合;(4)全局模型下载是指客户端将其本地模型替换为下载的全局模型(即平均权重)。这些过程运行
R
R
R轮通信。
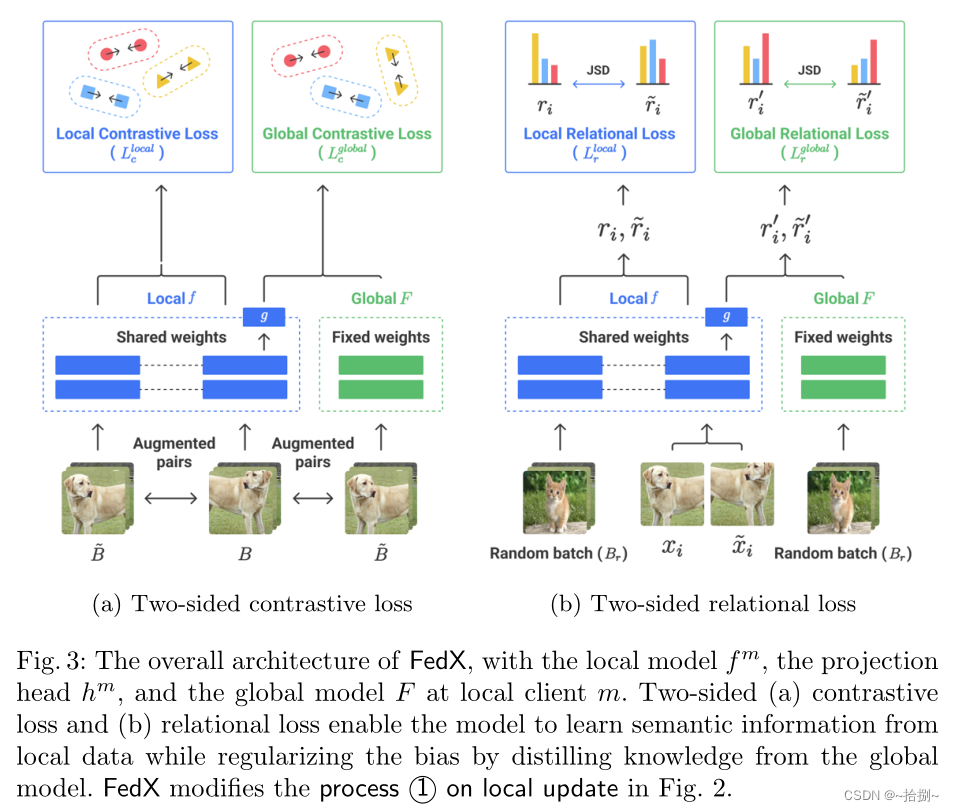
FedX修改流程(1)通过重新设计损失目标来提取本地和全球范围内的知识。FedX的整体架构,包括本地模型
f
m
f^m
fm、投影头
h
m
h^m
hm和本地客户端
m
m
m的全局模型
F
F
F。双侧对比损失(a)和双侧关系损失(b)使模型能够从本地数据中学习语义信息,同时通过从全局模型中提取知识来规范偏差。
Learning Efficient Object Detection Models with Knowledge Distillation
利用知识蒸馏学习高效的目标检测模型
论文:http://papers.nips.cc/paper/6676-learning-efficient-object-detection-models-with-knowledge-distillation
代码:No code implementations yet
使用知识蒸馏和提示学习(hint learning)来学习紧凑快速的目标检测网络。加权交叉熵损失来解决课堂不平衡问题,教师有界损失来处理回归分量和适应层,来更好地从中间教师分布中学习。
贡献:
- 提出了一个端到端可训练的框架,用于通过知识提取来学习紧凑的多类对象检测模型。
- 提出一种用于分类的加权交叉熵损失,该损失解释了背景类与对象类错误分类影响的不平衡,用于知识蒸馏的教师有界回归损失和用于提示学习的适应层,允许学生更好地从教师中间层中的神经元分布中学习。
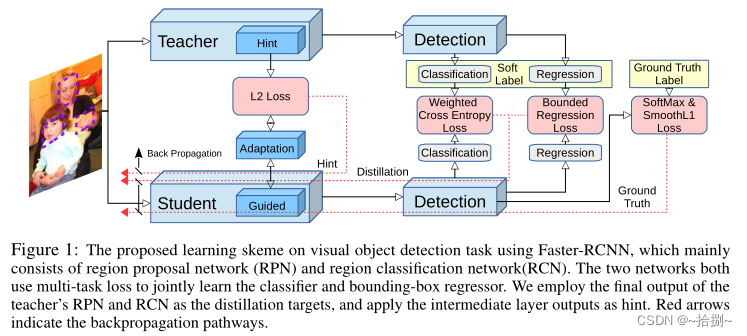
使用Faster RCNN提出的视觉对象检测任务的学习骨架,主要由区域建议网络(RPN)和区域分类网络(RCN)组成。这两个网络都使用多任务损失来联合学习分类器和边界框回归器。我们使用教师的RPN和RCN的最终输出作为蒸馏目标,并应用中间层输出作为提示。红色箭头表示反向传播途径。
Faster RCNN由三个模块组成:
1)通过卷积层的共享特征提取
2)生成对象建议的区域建议网络(RPN)
3)返回每个对象建议的检测分数和空间调整向量的分类和回归网络(RCN)。
RCN和RPN都使用1)的输出作为特征,RCN也将RPN的结果作为输入。
- 采用了基于提示的学习鼓励学生网络的特征表示与教师网络的特征表达相似。
- 使用知识蒸馏框架在RPN和RCN中学习更强的分类模块。
- 为了处理对象检测中严重的类别不平衡问题,我们将加权交叉熵损失应用于提取框架。
- 将教师的回归输出作为上界的一种形式进行转移,也就是说,如果学生的回归输出比教师的好,则不应用额外的损失。
Big Self-Supervised Models are Strong Semi-Supervised Learners
大的自我监督模型是强的半监督学习者
论文:https://arxiv.org/pdf/2006.10029v2.pdf
代码:https://github.com/google-research/simclr
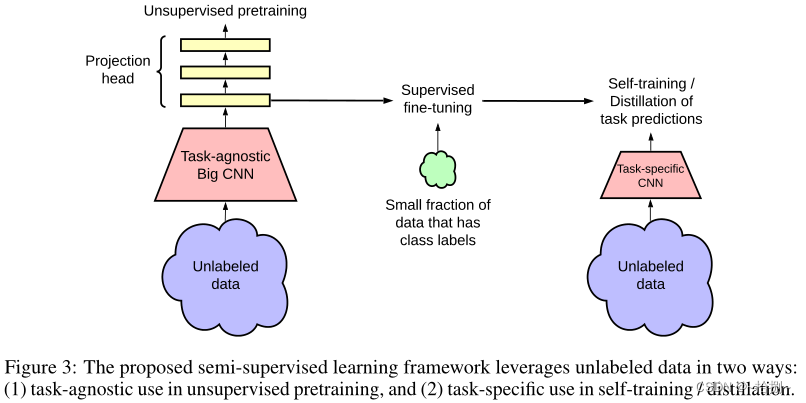
提出的半监督学习算法可以概括为三个步骤:使用SimCLRv2对大ResNet模型进行无监督预训练,对几个标记的例子进行监督微调,以及用未标记的例子提炼和转移特定任务的知识。
第一次使用未标记数据时,它是以任务不可知的方式,通过无监督预训练来学习一般(视觉)表示。然后,通过监督的微调将通用表示适配于特定任务。第二次使用未标记数据时,是以特定任务的方式,用于进一步提高预测性能并获得紧凑模型。为此,我们在未标记的数据上训练学生网络,并从微调的教师网络中输入标签。我们的方法可以概括为三个主要步骤:预处理、微调和提取。
为了使用未标记图像有效地学习一般视觉表示,采用并改进了SimCLR(一种基于对比学习的方法)。SimCLR通过在潜在空间中的对比损失最大化相同数据示例的不同增强视图之间的一致性来学习表示。更具体地说,给定随机采样的图像的小批量,使用随机裁剪、颜色失真和高斯模糊对每个图像 x i x_i xi进行两次增强,从而创建相同示例 x 2 k − 1 x_{2k−1} x2k−1和 x 2 k x_{2k} x2k的两个视图。这两幅图像通过编码器网络 f ( ⋅ ) f(·) f(⋅)(ResNet[25])进行编码,以生成表示 h 2 k − 1 h_{2k−1} h2k−1和 h 2 k h_{2k} h2k。然后用非线性变换网络 g ( ⋅ ) g(·) g(⋅)(MLP投影头)再次变换表示,得到用于对比损失的 z 2 k − 1 z_{2k−1} z2k−1和 z 2 k z_{2k} z2k。
微调是使任务不可知的预训练网络适应特定任务的常用方法。在SimCLR中,MLP投影头 g ( ⋅ ) g(·) g(⋅)在预训练后被完全丢弃,而在微调过程中只使用ResNet编码器 f ( ⋅ ) f(·) f(⋅)。我们建议在微调期间将MLP投影头的一部分纳入基本编码器,而不是将其全部扔掉。换句话说,我们从投影头的中间层微调模型,而不是像SimCLR中那样从投影头输入层微调模型。
Class-Balanced Distillation for Long-Tailed Visual Recognition
用于长尾视觉识别的类平衡蒸馏
论文:[https://arxiv.org/pdf/2104.05279v2.pdf](https://arxiv.org/pdf/2104.05279v2.pdf
代码:https://github.com/google-research/google-research
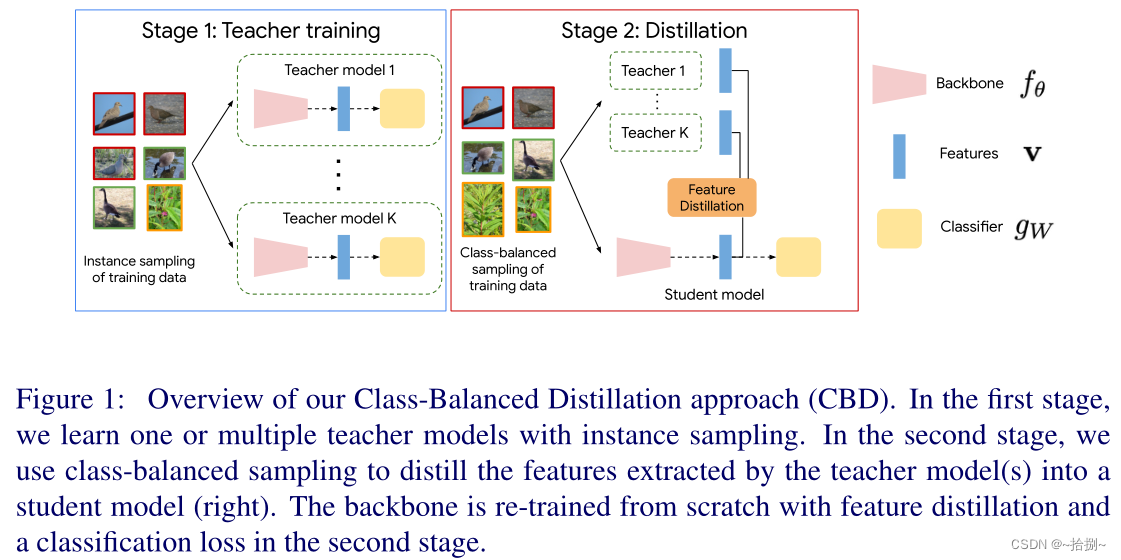
真实世界的图像通常以每类图像数量的显著不平衡为特征,从而导致长尾分布。长尾视觉识别的一种有效而简单的方法是分别通过实例和类平衡采样分别学习特征表示和分类器。在这项工作中,我们引入了一个新的框架,通过关键的观察,即在长尾设置中,通过实例采样学习的特征表示远不是最优的。我们的主要贡献是一种新的训练方法,称为类平衡蒸馏(CBD),它利用知识蒸馏来增强特征表示。
CBD允许特征表示在第一阶段,通过实例抽样学习一个或多个教师模型。在第二阶段,使用类平衡提取将教师模型提取的特征提取到学生模型中(右)。主干在第二阶段通过特征提取和分类损失从头开始重新训练。

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









