







参考理解熵与交叉熵 - 九号的文章 - 知乎
https://zhuanlan.zhihu.com/p/389293738
熵
计算公式:
H
(
a
)
=
−
l
o
g
(
p
(
a
)
)
H(a) = -log(p(a))
H(a)=−log(p(a))
就是信息量,对于一个事件A,的一种情况的信息量,由情况a_i发生的概率决定
举个例子:
明天的天气有3种情况,分别是阴,晴,雨。发生的概率分别为1/10,2/10,7/10。那么,假如上帝告诉你“明天一定会下雨”,则这句话的信息量为
−
l
o
g
(
1
/
10
)
-log(1/10)
−log(1/10),-log函数随x递减,也就是说概率越低,熵越大
ps: 为什么是这个公式?(-log)
(1)信息量应该依赖于概率分布,所以应该是个单调函数
(2)信息量>0 ,在定义域为(0~1)时
(3)连续依赖于概率变化
(4)若有两个随机变量且相互独立,要求同时观测与分别观测时信息量相同
事件的信息量:
就是所有情况的信息量的加权平均,一般情况下权重就是它本身的概率,也就是这个情况发生的概率
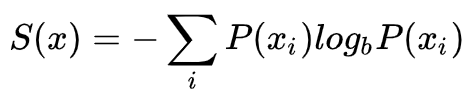
交叉熵
交叉熵是用来衡量两种分布的差异大小,来源自KL散度删去常量(其中一个事件的熵)
计算公式:

可以理解为用事件A的所有情况的概率分布当做事件B的对应情况信息量的权重
KL散度
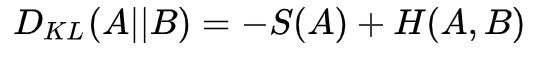
其实就是交叉熵-事件A的信息量
用来衡量两个分布的差异大小,差异越大,KL散度越大,反之亦然
ps:这里不用用事件B的信息量,有坐标系问题

参考为什么交叉熵(cross-entropy)可以用于计算代价? - 微调的回答 - 知乎
https://www.zhihu.com/question/65288314/answer/244557337
计算公式:

条件熵
在已知一个事件时,得知另一个事件所获取的信息量。也可以理解为条件分布p(x|y)的熵。
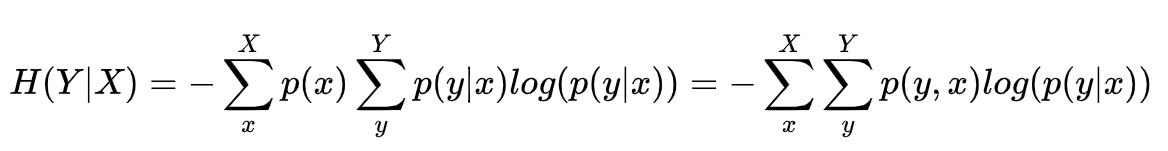















 2346
2346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









