







这篇文章比较难,需要较多的概率论和信息论知识,论文中公式推导给的不是特别多,有些过程并没有做推导,因此不是太能理解,不过大概意思是能懂的。
论文提出了一种知识量计算方法,通过计算每个输入的知识量,来表征每个输入的重要程度
总的想法非常简单,就是对每个输入加一个可学习的扰动,通过Loss函数来使得这个扰动大小能代表对应输入的重要程度

这是输出的hidden state:S和输入X的互信息,不过其实这个公式在这里没啥用,作者主要是要引出后面这个条件熵
条件熵
H
(
X
∣
S
)
H(X|S)
H(X∣S),就是知道输出的情况下,输入的熵

换句话说,就是经过这层layer,有多少输入的信息量被抛弃了。(论文中是这么说的,不过照理说不是应该用信息增益来作为抛弃的量嘛,如果H(X|S)越大,代表信息增益越小,也就是抛弃的信息量越小)
上面这个公式,X代表这个句子,s代表这个句子输出的最后一个hidden state(分类任务),也就是说,这是求这个句子的条件熵,我们最终要拿到的是每个单词的条件熵(或者说是抛弃的信息量),因此这里有个独立性假设,假设每个单词的embedding都是独立的,因此有句子的熵=每个单词的熵相加

但是每个单词的条件熵并不好求,这里
p
(
x
i
∣
s
)
p(x_i|s)
p(xi∣s)怎么求都不知道,因此用另一种方法来近似
(1)对每个输入增加一个可学习的高斯噪声
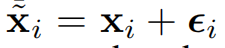
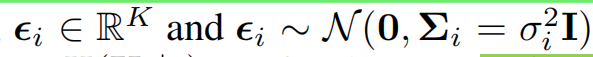
每个单词加的噪声都不同,都是独立的,均值为0,方差为
σ
i
2
\sigma_i^2
σi2,这个方差是可学习的
(2)计算Loss,凸优化
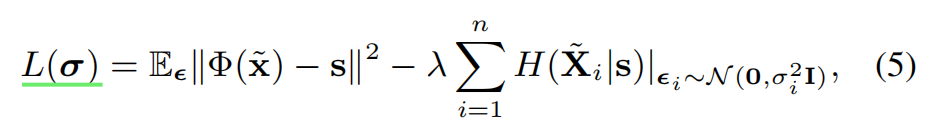
这个Loss的优化目标:
1、最小化原始输出和扰动后的输出的距离,也就是说这个扰动要能使得输出尽量不变
2、最大化扰动后的总的条件熵,也就是说,加了扰动之后,尽量使得输入变化大,就算知道原始输出,输入X的信息量(随机性)也很大
通过推导可以得到
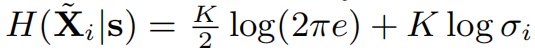
上式中K是x_i的维度
这个条件熵是关于该word的扰动的方差的函数,且方差越大,条件熵越大,所以最大化条件熵,实际上是最大化扰动(的方差)
同时还要保证输出的hidden state变化尽量小,因此,对输出影响越大的word加的噪声会越小,对输出影响越小的word加的噪声越大。
因此,可以用噪声的大小来衡量输入word对输出的影响程度,即知识量

这张图就很好地描述了上面两个过程。
最后理一下为什么噪声能代表“知识量”?
从优化目标看,噪声少——>word对输出影响大——>word的H(x|s)大——>H(x)-H(x|s)信息增益小(互信息小)——>layer遗忘的信息量大
其实跟那种加个噪声看输出变化量来评估word重要程度的方法差不多,只不过这里是学习噪声,使得噪声能反映word的重要程度
解释一下那个知识量公式:
x
i
=
x
+
ϵ
x_i=x+\epsilon
xi=x+ϵ,这里有个假设,假设原始x也是呈正态分布的,这样两个分布相加,也是正态分布,均值为
x
ˉ
+
0
\bar{x}+0
xˉ+0,方差为
σ
+
σ
x
\sigma+\sigma_x
σ+σx,这里
σ
x
\sigma_x
σx是一个常数
经过正态分布的微分熵的计算后,均值没有了,只剩下方差

因此也就是最后那个公式,另外这个方差应该是噪声的方差+原始x的方差,不过由于原始x的方差是一个定值,这里主要是用来比较,因此可以直接看成噪声的方差















 1865
1865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









