







在Code::Blocks新建一个wx空白项目并建立一个main.cpp文件,代码如下:
#include "wx/wx.h"
//主窗口类
class MyFrame: public wxFrame
{
public:
MyFrame();
};
//主窗口类构造函数
MyFrame::MyFrame()
:wxFrame(NULL, wxID_ANY, wxT("Title"), wxDefaultPosition, wxSize(400, 300))
{
//增加一个静态文本到主窗口
wxStaticText *text = new wxStaticText(this, wxID_ANY, wxT("Hello World!"));
}
//应用类
class MyApp : public wxApp
{
public:
virtual bool OnInit();
};
//自动实例化MyApp对象并赋值给全局变量wxTheApp
DECLARE_APP(MyApp)
//声明可以使用wxGetApp()获取实例对象
IMPLEMENT_APP(MyApp)
//应用程序入口
bool MyApp::OnInit()
{
//实例化一个主窗口
MyFrame *frame = new MyFrame();
//显示主窗口
frame->Show(true);
//开始事件循环
return true;
}这就是最简单的wx程序了。
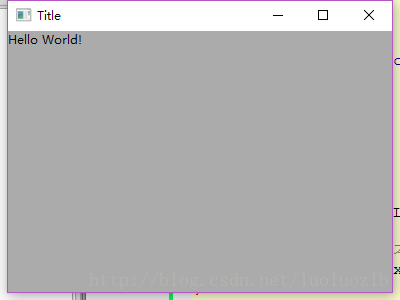
运行效果如下:















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









