






引言
当 LoRA 遇见 MoE,会擦出怎样的火花?
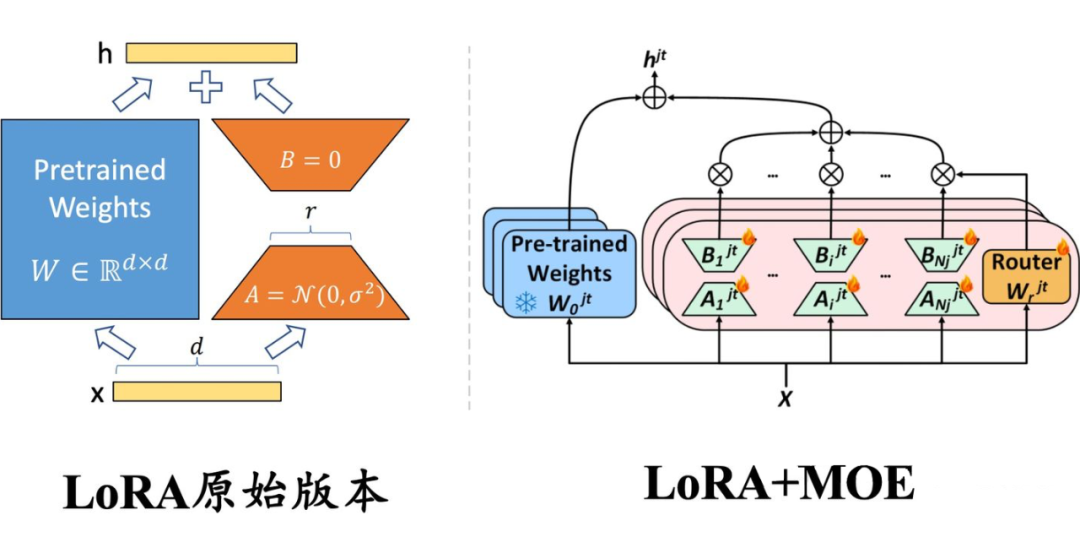
▲ 左侧:原始版本的 LoRA,权重是稠密的,每个样本都会激活所有参数;右侧:与混合专家(MoE)框架结合的 LoRA,每一层插入多个并行的 LoRA 权重(即 MoE 中的多个专家模型),路由模块(Router)输出每个专家的激活概率,以决定激活哪些 LoRA 模块。
由于大模型全量微调时的显存占用过大,LoRA、Adapter、IA 这些参数高效微调(Parameter-Efficient Tuning,简称 PEFT)方法便成为了资源有限的机构和研究者微调大模型的标配。PEFT 方法的总体思路是冻结住大模型的主干参数,引入一小部分可训练的参数作为适配模块进行训练,以节省模型微调时的显存和参数存储开销。
传统上,LoRA 这类适配模块的参数和主干参数一样是稠密的,每个样本上的推理过程都需要用到所有的参数。近来,大模型研究者们为了克服稠密模型的参数效率瓶颈,开始关注以 Mistral、DeepSeek MoE 为代表的混合专家(Mixure of Experts,简称 MoE)模型框架。
在该框架下,模型的某个模块(如 Transformer 的某个 FFN 层)会存在多组形状相同的权重(称为专家),另外有一个路由模块(Router) 接受原始输入、输出各专家的激活权重,最终的输出为:
-
如果是软路由(soft routing),输出各专家输出的加权求和;
-
如果是离散路由(discrete routing),即 Mistral、DeepDeek MoE 采用的稀疏混合专家(Sparse MoE)架构,则将 Top-K(K 为固定的 超参数,即每次激活的专家个数,如 1 或 2)之外的权重置零,再加权求和。
在 MoE 架构中,每个专家参数的激活程度取决于数据决定的路由权重,使得各专家的参数能各自关注其所擅长的数据类型。在离散路由的情况下,路由权重在 TopK 之外的专家甚至不用计算,在保证总参数容量的前提下极大降低了推理的计算代价。
那么,对于已经发布的稠密大模型的 PEFT 训练,是否可以应用 MoE 的思路呢?近来,笔者关注到研究社区开始将以 LoRA 为代表的 PEFT 方法和 MoE 框架进行结合,提出了 MoV、MoLORA、LoRAMOE 和 MOLA 等新的 PEFT 方法,相比原始版本的 LORA 进一步提升了大模型微调的效率。
本文将解读其中三篇具有代表作的工作,以下是太长不看版:
-
MoV 和 MoLORA [1]:提出于 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是 IA 和 LORA 的 MOE 版本,采用 token 级别的软路由(加权合并所有专家的输出)。作者发现,对 3B 和 11B 的 T5 大模型的 SFT,MoV 仅使用不到 1% 的可训练参数量就可以达到和全量微调相当的效果,显著优于同等可训练参数量设定下的 LoRA。
-
LoRAMOE [2]:提出于 2023 年 12 月,在 MoLORA [1] 的基础上,为解决微调大模型时的灾难遗忘问题,将同一位置的 LoRA 专家分为两组,分别负责保存预训练权重中的世界知识和微调时学习的新任务,并为此目标设计了新的负载均衡 loss。
-
MOLA [3]:提出于 2024 年 2 月,使用离散路由(每次只激活路由权重 top-2 的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升 LLaMa-2 微调的效果。
MoV和MoLORA:PEFT初见MoE,故事开始
论文标题:
Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning
论文链接:
https://arxiv.org/abs/2309.05444
该工作首次提出将 LoRA 类型的 PEFT 方法和 MoE 框架进行结合,实现了 MoV(IA 的 MOE)版本和 MoLORA(LORA 的 MOE)版本,发现 MoV 的性能在相等的可训练参数量设定下优于原始的 LORA,非常接近全参数微调。回顾下IA 的适配模块设计,即在 Transformer 的 K、V 和 FFN 的第一个全连接层的输出,各自点乘上一个可训练的向量 :
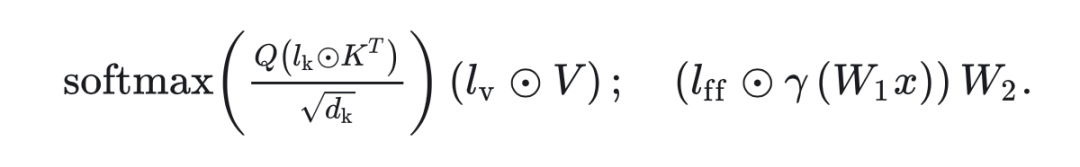
那么,MOV 就是将这些可训练向量各自复制 份参数(n 为专家个数),并加入一个路由模块接受 K/V/FFN 原本输出的隐向量 、输出各专家的激活权重,过 softmax 之后得到各专家的激活概率 ,以其为权重对各个可训练向量求和(之后向原始版本的 IA 一样,将求和后的向量点乘上原输出的隐向量)。图示如下:
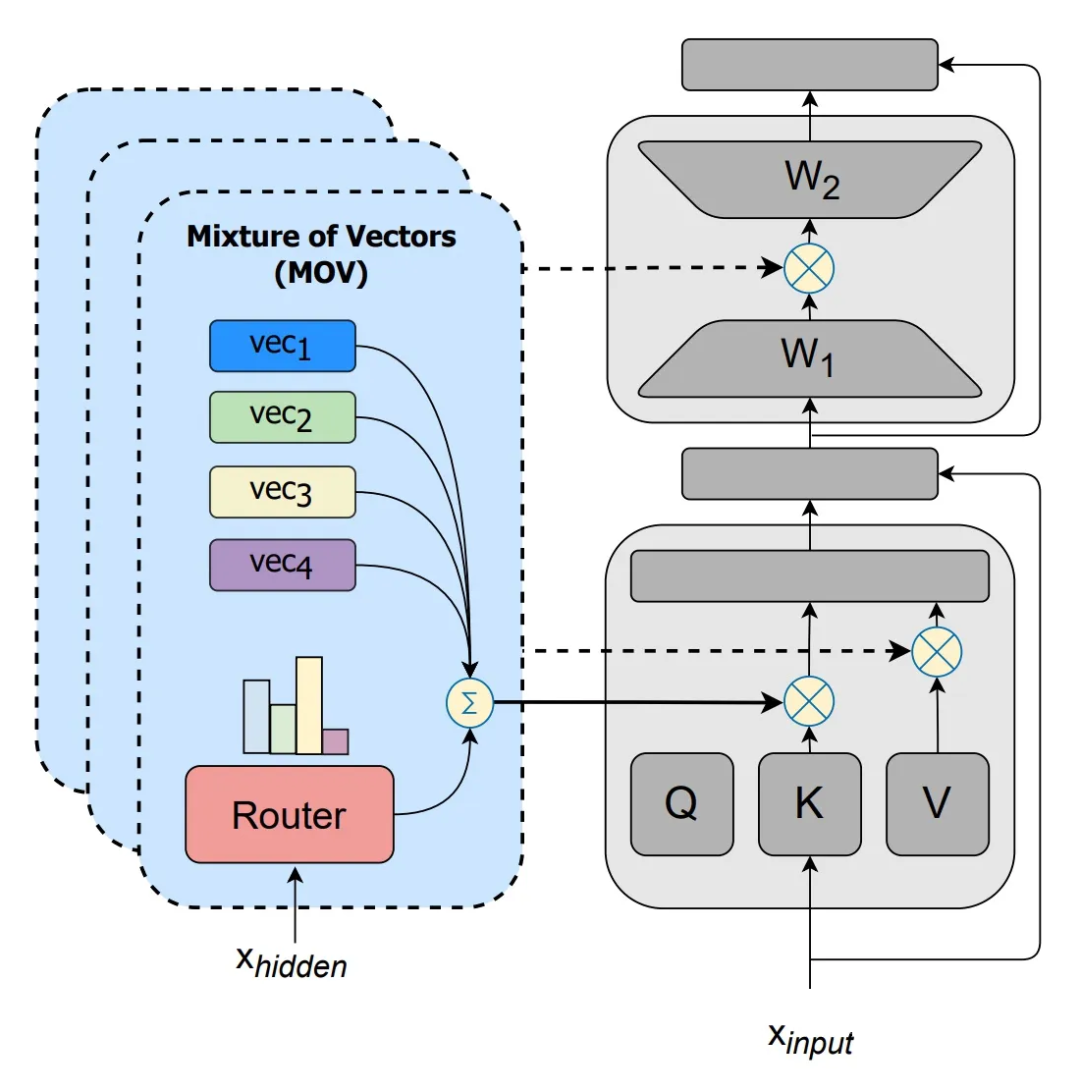
▲ MOV 方法的示意图,引自论文[1]。
实验部分,作者在 Public Pool of Prompts 数据集上指令微调了参数量从 770M 到 11B 的 T5 模型,在 8 个 held out 测试集上进行测试。实验的微调方法包括全量微调、原始版本的 IA 和 LORA、MoV 和 MoLORA。
从测试结果上来看,MoV的性能明显好于 MoLORA 和原始版本的 IA 和 LORA。例如,专家个数 的 MoV-10 只用 3B 模型 0.32% 的参数量,就能达到和全量微调相当的效果,明显优于同等可训练参数量的 IA 和 LORA,而使用 0.68% 可训练参数的 MoV-30(60.61)甚至超过全量微调。

▲ 3B 模型的测试结果,只使用 0.32% 可训练参数的MoV-10 的平均 accuracy(59.93)接近全量微调(60.06),明显优于使用 0.3% 可训练参数的原始版本 LORA(57.71)。使用 0.68% 可训练参数的 MoV-30(60.61)甚至超过全量微调。
此外,作者还对专家的专门程度(speciality,即每个任务依赖少数几个特定专家的程度)进行了分析,展示 MOV-5 微调的 770M 模型最后一层 FFN 中各专家路由概率的分布:
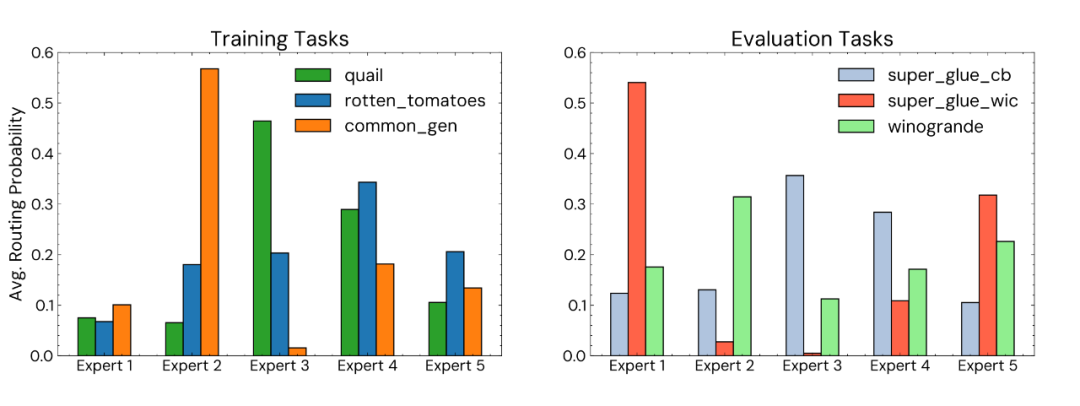
▲ 路由概率的分布,左侧为模型在训练集中见过的任务,右侧为测试集中模型未见过的任务。
可以看出,无论模型是否见过任务数据,大多数任务都有 1-2 个特别侧重的专家占据了大部分激活概率值,说明 MoV 这个 MoE 实现达成了专家的专门化。
LoRAMOE:LoRA专家分组,预训练知识记得更牢
论文标题:
LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment
论文链接:
https://arxiv.org/abs/2312.09979
此文为复旦大学 NLP 组的工作,研究动机是解决大模型微调过程中的灾难遗忘问题。
作者发现,随着所用数据量的增长,SFT 训练会导致模型参数大幅度偏离预训练参数,预训练阶段学习到的世界知识(world knowledge) 逐渐被遗忘,虽然模型的指令跟随能力增强、在常见的测试集上性能增长,但需要这些世界知识的 QA 任务性能大幅度下降:
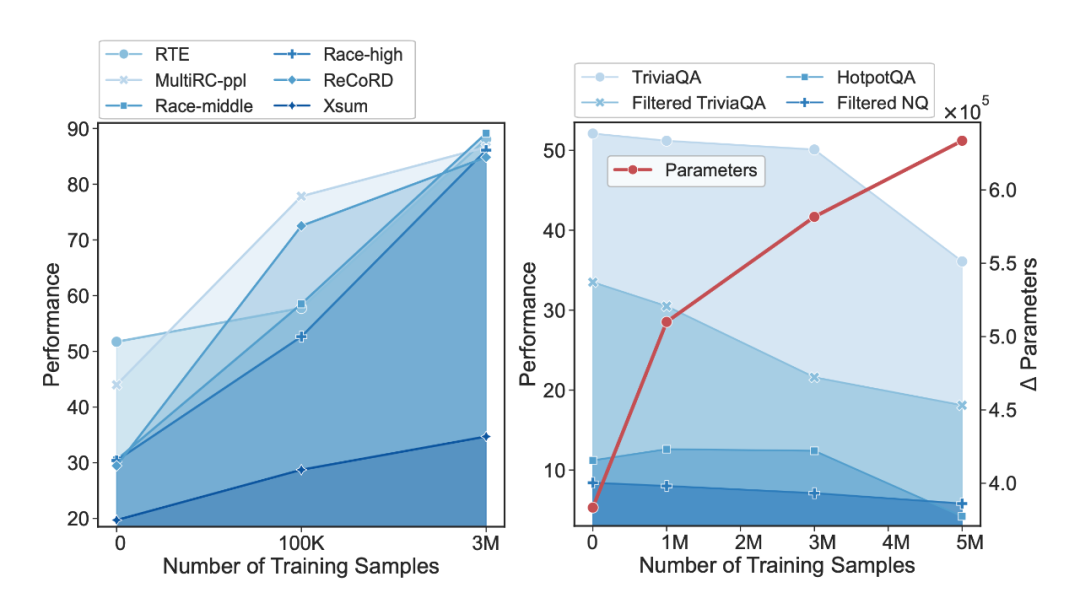
▲ 左侧为不需要世界知识的常见测试集上的性能,右侧为需要世界知识的 QA 测试集上的表现,横轴为 SFT 数据量,红线为模型参数的变化程度。
作者提出的解决方案是:
-
数据部分: 加入 world knowledge 的代表性数据集 CBQA,减缓模型对世界知识的遗忘;
-
模型部分: 以(1)减少模型参数变化、(2)隔离处理世界知识和新任务知识的参数为指导思想,在上一篇文章的 MoLORA 思想上设计了 LoRAMoE 方法,将 LoRA 专家们划分为两组,一组用于保留预训练参数就可以处理好的(和世界知识相关的)任务,一组用于学习 SFT 过程中见到的新任务,如下图所示:
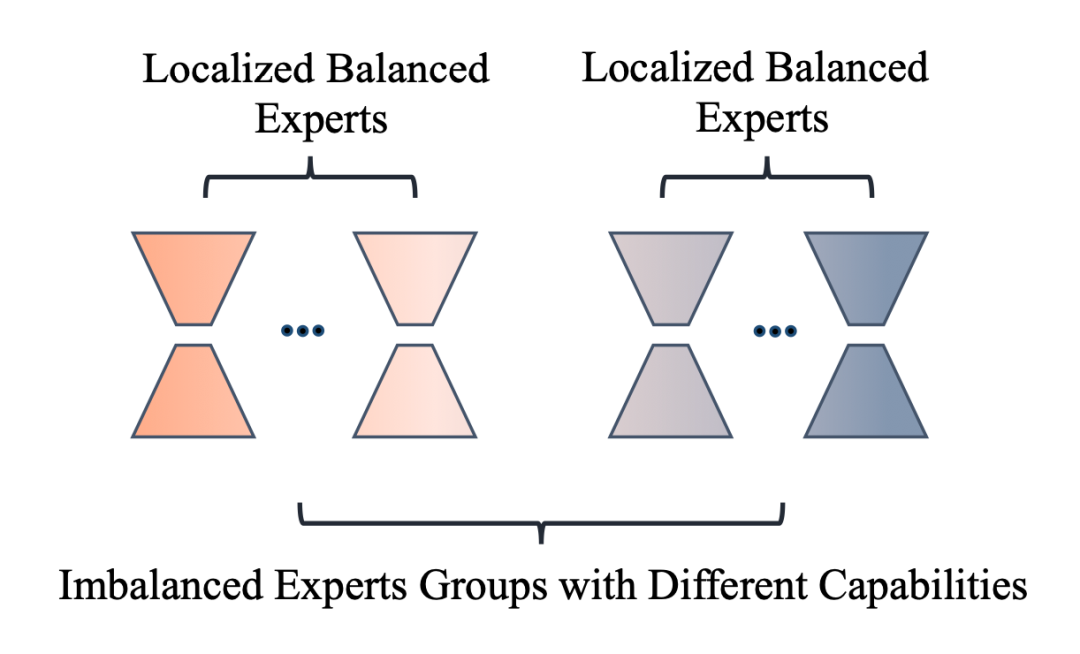
为了训练好这样的分组专家,让两组专家在组间各司其职(分别处理两类任务)、在组内均衡负载,作者设计了一种名为 localized balancing contraint 的负载均衡约束机制。具体地,假设 为路由模块输出的重要性矩阵, 代表第 个专家对第 个训练样本的权重, 作者定义的和 形状相同的矩阵:
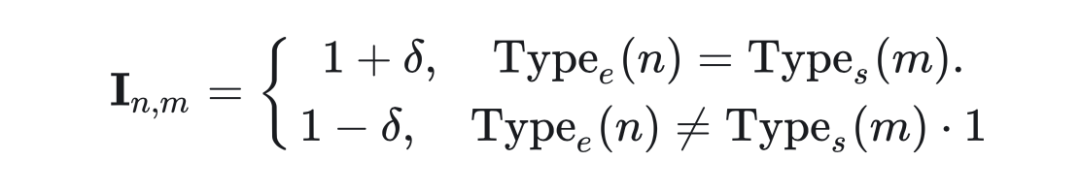
其中 为 0-1 之间的固定值(控制两组专家不平衡程度的超参), 为第 个专家的类型(设负责保留预训练知识的那组为 0,负责习新任务的那组为1), 为第 个样本的类型(设代表预训练知识的 CBQA 为 0,其他 SFT 数据为 1)。负载均衡损失 的定义为用 加权后的重要性矩阵 的方差除以均值:
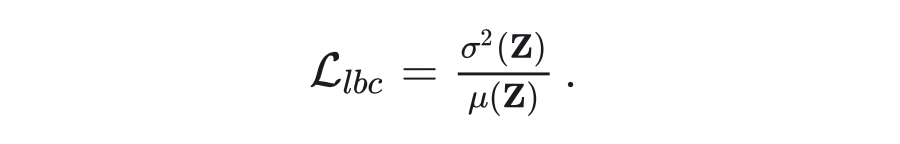
这样设计 loss 的用意是,对任意一种训练样本,两组 LoRA 专家组内的 值是相等的,优化 即降低组内路由权重的方差,使得组内负载均衡;两组专家之间,设专家组 A 对当前类型的数据更擅长,则其 值大于另一组专家 B,训练起始阶段的 A 的激活权重就显著大于 B,A 对这种数据得到的训练机会更多,路由模块在训练过程中逐渐更倾向对这种数据选择A组的专家。
这种 “强者愈强”的极化现象 是 MoE 领域的经典问题,可以参见经典的 sMoE 论文 The Sparsely-Gated Mixture-of-Experts Layer [4] 对该问题的阐述。
这样一来,即使推理阶段没有数据类型 的信息,A 对这种数据的路由值 也会显著大于 B 的相应值,这就实现了两组专家各司其职的目标。
实验部分,作者在 CBQA 和一些列下游任务数据集混合而成的 SFT 数据上微调了 LLaMA-2-7B,对比了全量 SFT、普通 LORA 和作者所提的 LoRAMoE 的性能。
结果显示,LoRAMoE 有效克服了大模型 SFT 过程中的灾难性遗忘问题,在需要世界知识的 QA 任务(下表下半部分)上性能最佳,在与 SFT 训练数据关系更大的其他任务上平均来说基本与 SFT 训练的模型相当:

MOLA:统筹增效,更接近输出端的高层需要更多专家
论文标题:
Higher Layers Need More LoRA Experts
论文链接:
https://arxiv.org/abs/2402.08562
该工作受到 MoE 领域先前工作 [5] 发现的专家个数过多容易导致性能下降的现象之启发,提出了两个问题:
-
现有 PEFT+MoE 的微调方法是否存在专家冗余的问题?
-
如何在不同中间层之间分配专家个数?
为了解答问题 1,作者训练了每层专家个数均为 5 的 LoRA+MoE(基座模型为 32 层的 LLaMa-2 7B),路由机制采用 Top-2 离散路由,计算了每层 self-attention 的 Q、K、V、O 各组专家权重内两两之间求差的 Frobenius 范数的平均值,可视化如下:
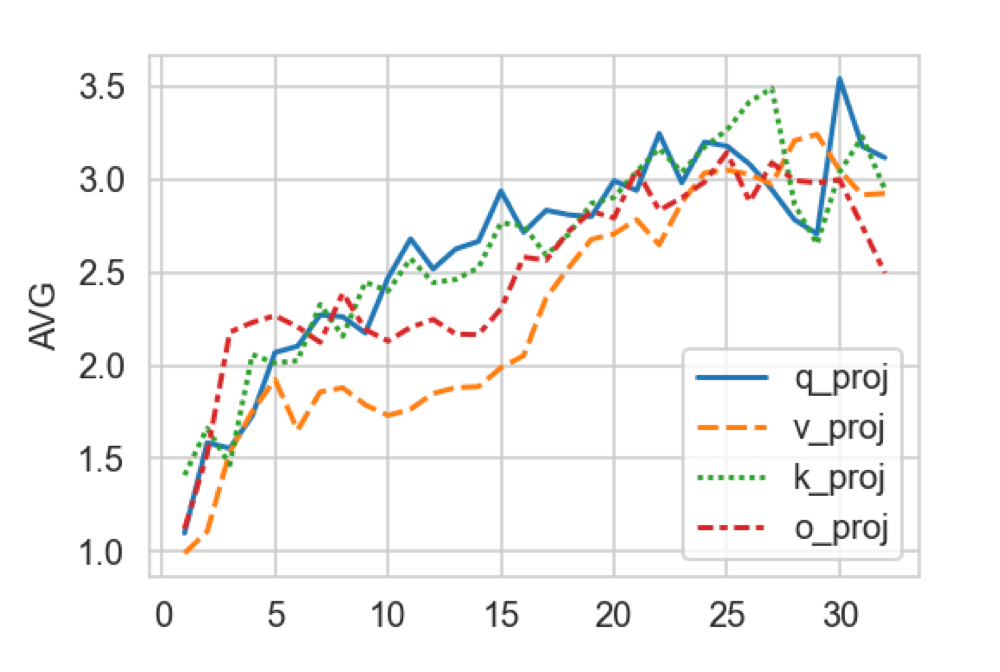
▲ 横轴为模型层数,纵轴为专家权重之间的差异程度。
可以看出,层数越高(约接近输出端),专家之间的差异程度越大,而低层的专家之间差异程度非常小,大模型底层的 LoRA 专家权重存在冗余。该观察自然导出了对问题 2 答案的猜想:高层需要更多专家,在各层的专家个数之和固定的预算约束下,应该把底层的一部分专家挪到高层,用原文标题来说就是:
Higher Layers Need More Experts
为了验证该猜想,作者提出了四个版本的专家个数划分方式分别严重性能,它们统称为 MoLA(MoE-LoRA with Layer-wise Expert Allocation),分别是:
-
MoLA-△:正三角形,底层专家个数多,高层专家个数少;
-
MoLA-▽:倒三角形,底层少,高层多;
-
MoLA-▷◁: 沙漏型,两头多、中间少;
-
MoLA-□:正方形,即默认的均匀分配。
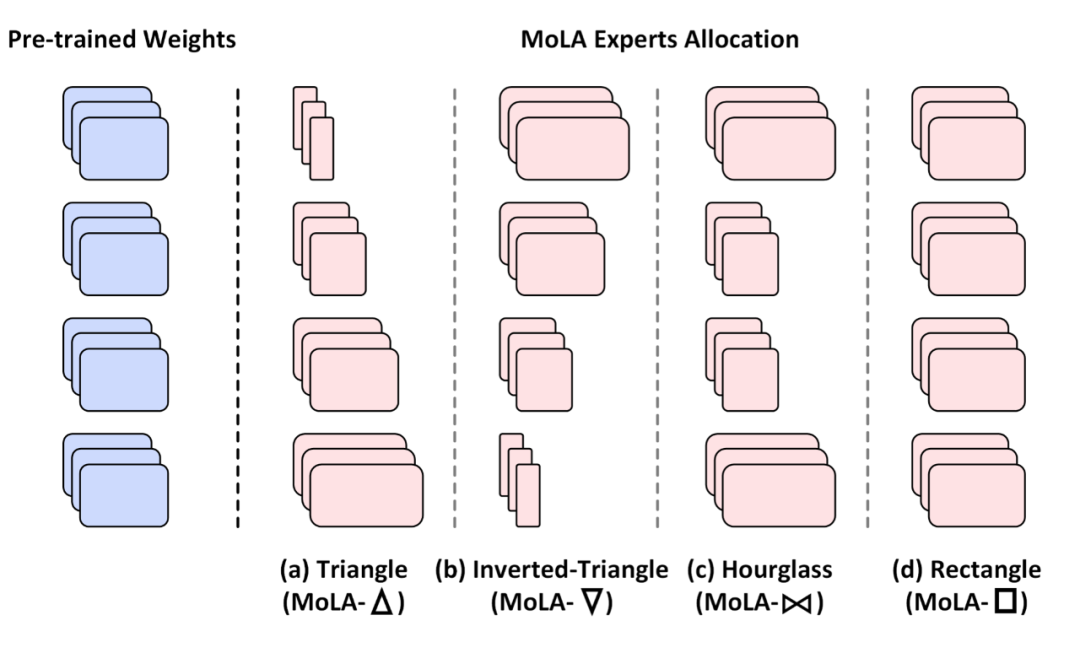
▲ 四种在不同中间层之间划分专家个数的方式。
具体实现中,作者将 LLaMA 的 32 层从低到高分为 4 组,分别是 1-8、9-16、17-24、25 到 32 层,以上四种划分方式总的专家个数相等,具体划分分别为:
-
MoLA-△:8-6-4-2
-
MoLA-▽:2-4-6-8;
-
MoLA-▷◁: 8-2-2-8;
-
MoLA-□:5-5-5-5。
路由机制为 token 级别的 Top-2 路由,训练时加入了负载均衡损失。MoLA 的 LoRA rank=8,基线方法中 LoRA 的秩为 64(可训练参数量略大于上述四种 MoLA,与 MOLA-□ 的 8-8-8-8 版本相同)评测数据集为 MPRC、RTE、COLA、ScienceQA、CommenseQA 和 OenBookQA,在两种设定下训练模型:
-
设定1:直接在各数据集的训练集上分别微调模型;
-
设定2:先在 OpenOrac 指令跟随数据集上进行 SFT,再在各数据集的训练集上分别微调模型。
从以下实验结果可以看出,在设定 1 下,MoLA-▽ 都在大多数数据集上都取得了 PEFT 类型方法的最佳性能,远超可训练参数量更大的原始版本 LoRA 和 LLaMA-Adapter,相当接近全量微调的结果。
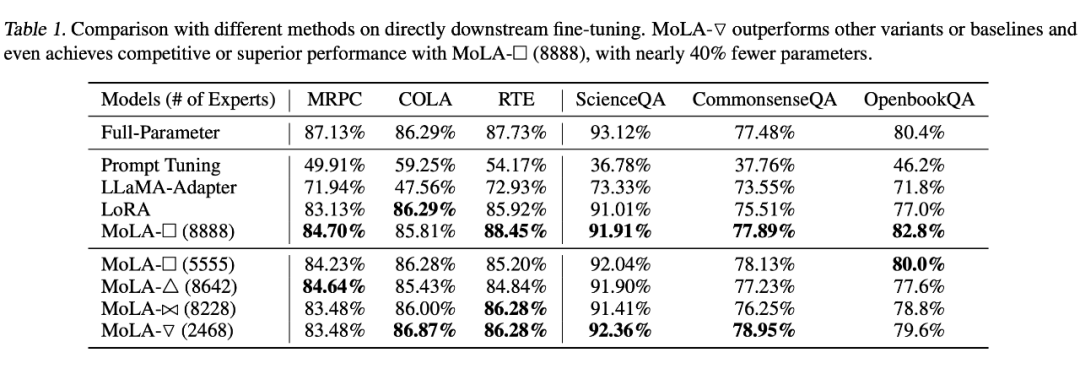
▲ 设定1下的实验结果
在设定 2 下,也是倒三角形的专家个数分配方式 MoLA-▽ 最优,验证了“高层需要更多专家”的猜想。
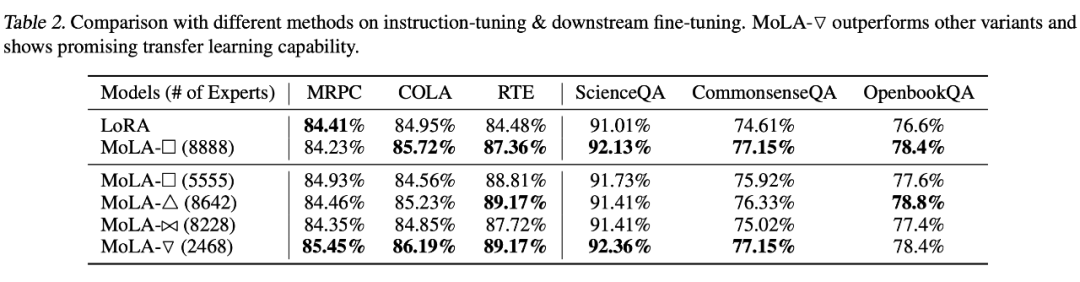
笔者点评:从直觉来看,模型的高层编码更 high-level 的信息,也和目标任务的训练信号更接近,和编码基础语言属性的底层参数相比需要更多调整,和此文的发现相符,也和迁移学习中常见的 layer-wise 学习率设定方式(顶层设定较高学习率,底层设定较低学习率)的思想不谋而合,未来可以探索二者的结合是否能带来进一步的提升。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









