






序言
2022年11月30日,OpenAI公司发布ChatGPT,瞬间引爆了全球互联网,拉开了生成式人工智能技术革命的序幕。当回顾这一年多的人工智能发展,任何现存词汇都无法形容其波澜壮阔,AIGC技术以前所未有的速度进化,通用人工智能的轮廓日渐清晰。
在这场势不可挡的技术革新洪流中,公众的情绪由最初的旁观、震惊,逐渐演变成一种夹杂着求知渴望的焦虑——这一切很大程度上源自于人工智能技术的神秘面纱。深入探究AI的奥秘要求深厚的理论基础,这对于大多数人而言并非易事。因此,我特推出本系列文章,旨在帮助广大读者揭开AIGC技术的神秘面纱,并逐步掌握其实用技巧,让技术更加平易近人。

有很多人将AIGC翻译为生成式人工智能,与GAI、AGI等缩略词产生混淆,以下是我对这几个缩略词的理解,供大家参考。
-
AGI (Artificial General Intelligence):可翻译为通用人工智能,指具有人类认知能力的人工智能,能够执行普通人类才可以完成的任务。
-
GAI (Generative Artificial Intelligence):可翻译为生成式人工智能,指具备生成新数据和内容能力的人工智能技术。
-
AIGC (Artificial Intelligence Generated Content):最初AIGC被用来指代内容,可被翻译为人工智能生成内容,所对应的是人们常说的PGC(平台生成内容)和UGC(用户生成内容);但越来越多人也用AIGC指代技术,这时将AIGC翻译为智能内容生成技术更为合适,以区分开更能精准表达生成式人工智能的GAI。
在这一波AIGC技术浪潮中,大语言模型(Large Language Models,简称LLM)首当其冲,率先成为公众瞩目的焦点,并快速转化为实际生产力。随之而来的,图像、视频及音乐领域的智能生成模型也逐步引起大量关注。本系列文章以大语言模型为启航点,带您一步步深入探索这片神奇领域,我希望以更通俗的语言让大众能够理解AI,很多表达并不严谨,请读者切勿用于对AI算法的精准理解。
大语言模型
大语言模型(Large Language Model, LLM)是一种由大量文本数据训练出来的自然语言处理模型,使用机器学习技术,来理解和生成人类语言。ChatGPT就是大语言模型的典型代表。
ChatGPT中的Chat比较容易理解:对话,那么其中的GPT到底是什么意思呢?其实,它是下面三个单词的缩写:
-
Generative:生成式的
-
Pre-trained:预训练的
-
Transformer:变形金刚
在这三个单词中,只有一个是名词,即Transformer,G和P都是修饰词,所以我们有必要先来了解一下什么是Transformer。
Transformer是什么?
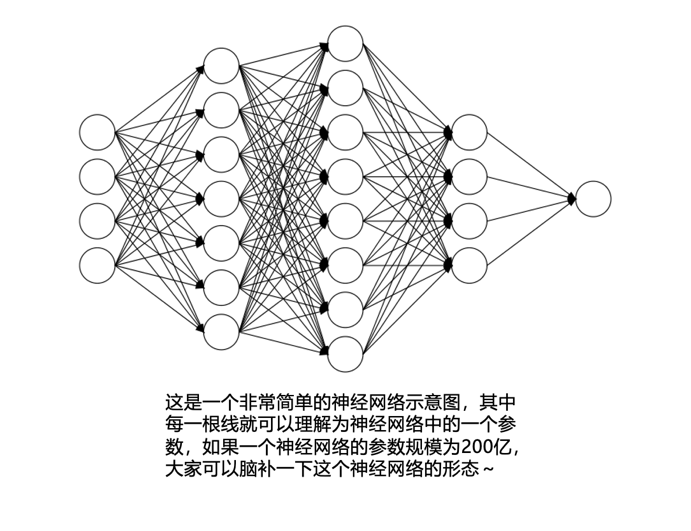
Transformer就是一个AI神经网络模型,这里的“网络”并不是我们日常家庭、公司所用于连接电脑和手机的网络,而是计算机科学家们用来模拟人脑工作机制的神经元网络,它一般由很多节点组成,每个节点用来模拟人脑神经元的工作机制,接收输入信息进行简单的计算,然后传递给下一个节点。通常神经元被分为很多层,每一层之间的神经元相互连接用来传递信息,每一个连接可以有一个数值来表达其传递信息的强度,这个数值就是我们通常所讲的大模型“参数”,现在我们会经常在各种文章中看到7B(70亿)、20B(200亿)等参数规模的描述,就可以脑补为这个模型中有数十亿到上千亿这种密密麻麻的神经元之间的连接。
Transformer是由Google在2017年6月份所发表的论文《Attention Is All You Need》中所提出。这篇论文是由一个8人团队完成,他们中既有当时还在读大学的实习生,也有Google的早期员工,但现如今他们都已经离开了Google,均在AI领域中开启了自己的创业生涯,有一篇文章专门讲述了这8个人撰写这篇论文的故事:《AI的伟大节点:Transformer 技术起源故事-谷歌八叛徒》,有兴趣的读者可以去读一下,挺有意思的。至于为什么叫Transformer,无从考证,据说是这个团队的发起者从小喜欢玩变形金刚的玩具,而这个模型最初就是用来解决翻译任务的,比较应景,所以就用了这样一个霸气的名称。
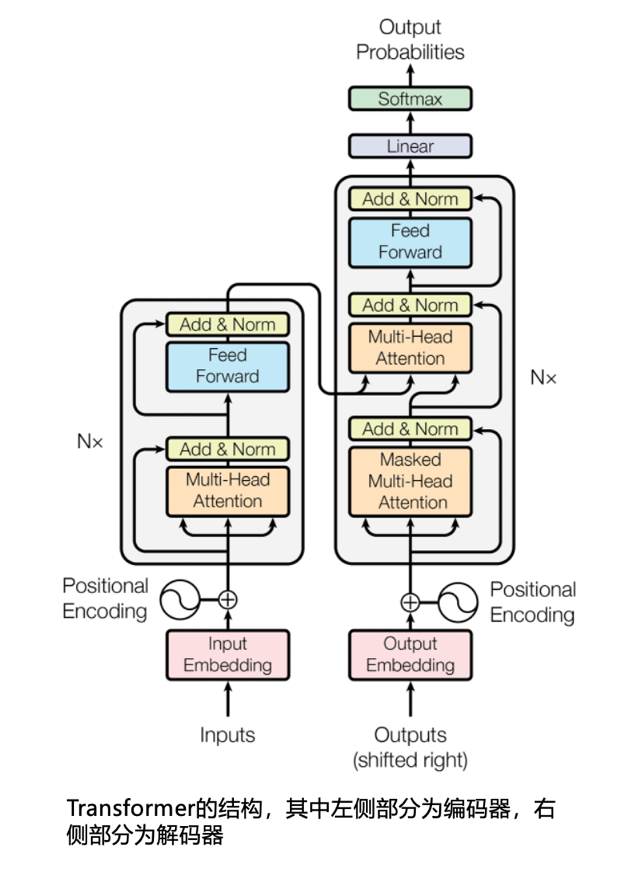
Transformer最初提出是希望解决翻译等任务的,其结构为编码器-解码器(Encoder-Decoder)架构,正如其论文标题“Attention Is All You Need”所揭示,其精髓就在于Attention,我们一般将其翻译为“注意力机制”。Attention是一种革命性的并行计算策略,它使模型能够高效地捕捉输入文本中每个词汇间的微妙联系,实现了对整体语境的快速理解。
语言是人类文明的瑰宝,人类可以用自然语言来表达丰富的内涵。我们自出生就生活在一个用语言来承载各种信息的环境中,这种环境使得我们从很小就能理解文字所表达的意思,能分辨哪些文字内容是相近的、哪些是无关的。
然而,想要让计算机也具备这个能力,就有一定难度了。因为,在计算机里面所有的信息的底层表示都是数字,我们可以用数字来存储和呈现文字、图像和视频等,但在智能时代,计算机科学家们想往前跨一大步:试图用数字来表达一段信息的语义,并进而实现复杂的推理任务。
为什么数字能够表达呢?我们用更直观的方式来进行解释。
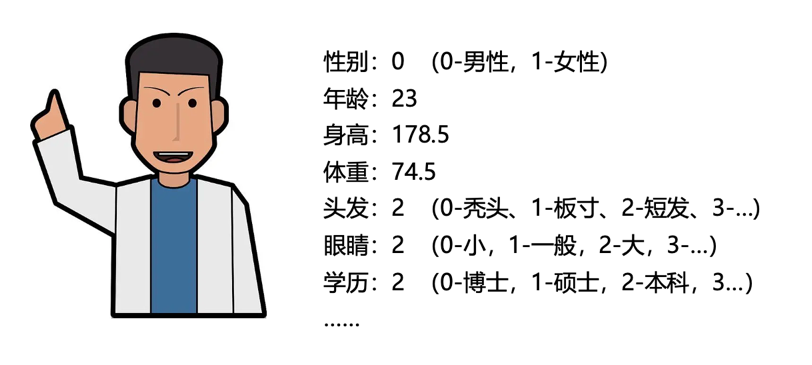
例如:我们想描述一个“人”,我们可以用性别、体重、身高、年龄这四个属性来描述,那么就可以用一组数字(0,74.5,178.5,23)来表征一个人:男性(0-男性,1-女性)、74.5公斤重、178.5cm高、23岁,如果想更精细的来描述这个人,还可以把肤色、眼睛大小、头发长短、学历、工作性质、性格特点、说话音色等都用数字来表达,描述的属性越多,我们脑补出这个人的形象也就越精准。而且,如果两个人的数值越接近,他们两个的相似性也就越高;反之,两个人的差异度也就越大。
除了直观的“人”可以用一组数字来表达外,其他的信息(例如图像、文字、视频)等也都可以通过抽取其特征形成一系列数字,数字的数量就是维度,当维度逐步扩大,其能表达和容纳的信息会越来越多,能够将生活中的万事万物都可以转换为一个高维的数字向量,也可以理解为高维空间中的一个点。经过这种映射,会发现一个很有意思的现象:我们生活中感觉含义比较相近的内容,在这个空间中的距离也很近;而我们生活中无关的信息,在这个空间中的距离也相对较远。很多神经网络模型的提出,就是在希望找到各种办法,能够更快更准的实现这种信息映射,然后再通过推理来解决现实生活中的各种任务。
Transformer的这篇论文,其核心就是采用的Attention机制来完成这个目标。Attention的特点是能够通过并行计算,快速关注到文本内容每个单词之间的相互关系,从而实现对整个输入内容语义的理解和推理。 在此之前所提出的算法,大都需要通过串行计算来顺序感知每个信息,导致计算效率不高,Attention的引入大大提升了这个效率。这种效率的提升带来了一个巨大的效应:大规模的训练成为了可能,有了大规模的训练,AI模型才涌现出后来让人瞠目结舌的各种能力。
Transformer包括两大部分:编码器(Encoder)和解码器(Decoder)。编码器扮演着翻译前的“理解者”角色,借助于Attention来快速分析输入的文字内容,理解其语义;而解码器是一位“推理者”,它根据编码器所理解的语义,推导出希望翻译的目标语言的文字内容,这种推导是逐词完成的:先输出第一个词,然后再把第一个词再次送入解码器,来推导第二个词,如此循环下去,直到解码器认为“结束翻译”是下一个输出为止。在解码器的推导过程中,Attention同样也发挥着重要作用,它被用来理解前面已经推导出来的信息,并且和编码器捕获的语义信息进行整合,以确保翻译工作的精准性。
GPT类大语言模型到底是怎么工作的?
Transformer提出后,分成了两大主要流派:一是沿着编码器部分进行更深入的探索,编码器的结构被设计为能够快速理解一段完整的文字,所以这个研究方向的成果很适合理解一段文字所表达的情感、对一段文字缺失的单词进行补全(完形填空)等;另一个方向是深入探讨解码器部分,这部分的结构被设计为根据已感知的信息,逐词推导后续内容,所以很适合用于做内容的续写、问题的回答,这个流派的代表性团队就是OpenAI。

自Transformer论文发表后,OpenAI公司的计算机科学家们敏锐的感知到其所蕴含的潜力,迅速组织团队开始深入研究,尤其是解码器部分。从2018年开始,OpenAI相继发布了GPT1.0、GPT2.0、GPT3.0、WebGPT、InstructGPT等,直到2022年11月30日发布ChatGPT。此后,几乎所有团队都把重心放到了解码器部分, 近一年多所发布的Claude、Llama、Gemini、通义千问、文心一言、ChatGLM、Baichuan等模型,几乎都是在解码器结构上训练出来的,所以,如果以后在一些文章里看到“Decoder-Only”的表述,指的就是Transformer的解码器结构的模型。
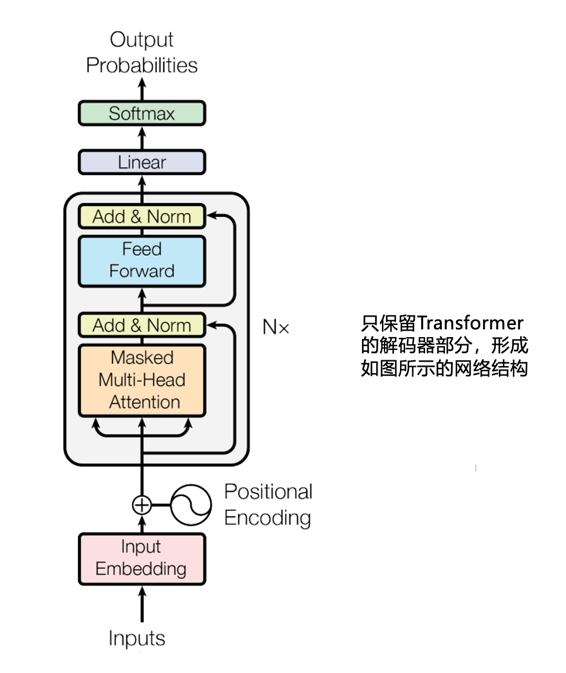
那么在解码器结构上所发展出来的GPT类大语言模型(为了表达简单,以下都简称为GPT)到底是怎么工作的呢?由于这一部分的结构的设计,是用Attention机制来快速感知已经获取的信息,来逐词推导后续的内容,所以,GPT的工作原理可以用一句话来解释:根据已知内容来预测下一个字是什么。
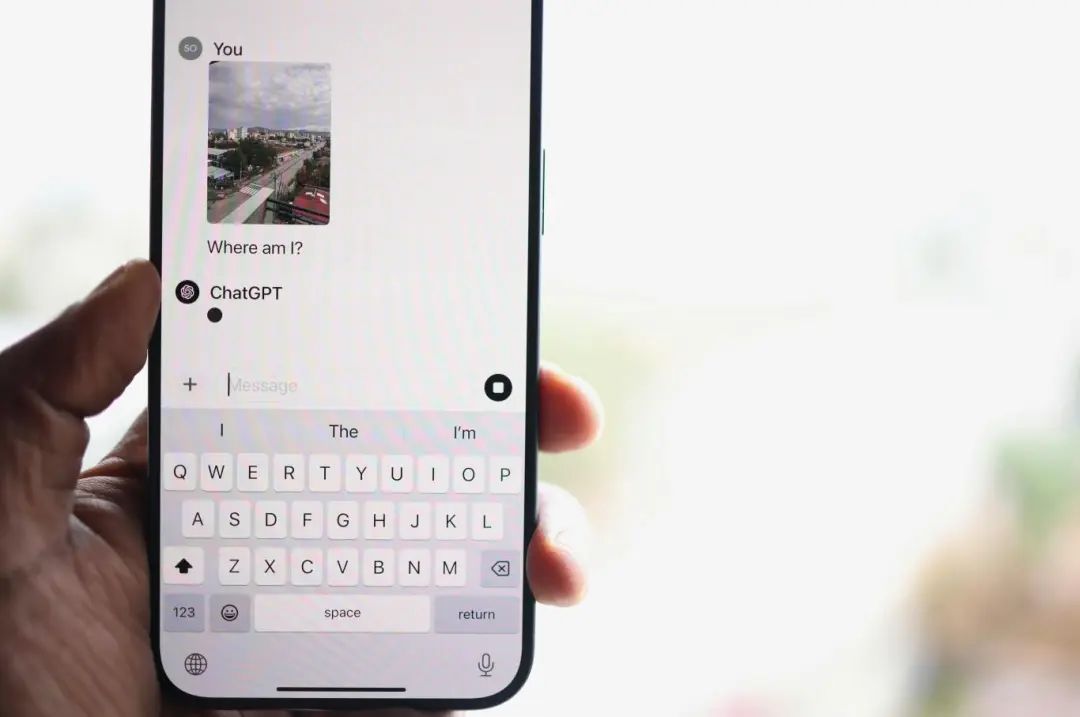
GPT最直观的类比,就是日常用的输入法,当我们输入了一个汉字后,输入法会将接下来最有可能继续输入的汉字提示出来,以供我们能够快速的完成输入。GPT强大的地方在于不仅仅能够感知上一个输入的字,而是可以感知前面已知所有信息,并根据这些信息来持续预测紧接着的下一个字。
我们可以把GPT理解为一个函数,这个函数的输入是已知的信息,输出是下一个字,假如我们向GPT提问的输入内容(这个输入内容一般被称为提示词,Prompt)是“请解释大语言模型的概念“,下图就是其工作机制的示意。

GPT会持续预测下一个字,直到它认为“结束当前回答”为止,这也是我们在使用GPT时,为什么是逐渐输出结果的原因。虽然这样看,其工作机制并不复杂,但GPT的强大之处在于即使人们向它提问非常复杂的问题,它也能够给出很高质量的回应,这需要庞大的模型、高质量的数据和强大的算力来完成这个模型的构建,在接下来的文章中,我们将进一步探讨GPT的训练过程,以及其所呈现出的关键能力。
Prompt(提示词):指的是给大语言模型提供的一段文本输入,用于引导模型生成相应的输出。这个提示词可以是一个问题、指令,也可以是一段话的引子,或者任何其他形式的文本,它的作用是设置上下文,让模型理解用户的意图,并生成与该上下文相关的回答或完成任务。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









