







1、结论写前面
论文对LLMs在对各种任务建模时利用异构表格数据的首次全面调查,包括预测、数据合成、问题回答和表格理解。论文深入研究了LLM摄取表格数据所需的基本步骤,包括序列化、表格操作和提示工程。此外,论文系统地比较了每个任务的数据集、方法学、度量标准和模型,强调了在理解、推断和生成表格数据方面的主要挑战和最新进展。论文为特定任务定制了数据集和模型选择的建议,旨在帮助机器学习研究人员和从业者选择使用不同LLMs进行表格数据建模的合适解决方案。此外,论文检查了当前方法的局限性,如易感于幻觉、公平性问题、数据预处理复杂性和结果可解释性挑战。鉴于这些限制,论文讨论了未来研究中值得进一步探讨的方向。
随着LLMs的快速发展和它们令人印象深刻的新兴能力,人们对探索它们在为各种任务建模结构化数据的潜力的新思路和研究的需求不断增长。通过这次全面的审查,论文希望它能为感兴趣的读者提供相关的参考和深刻的视角,使他们具备必要的工具和知识,以有效地应对和解决该领域的当前挑战。
2、背景
大型语言模型(LLMs)是在大量数据上训练的深度学习模型,赋予它们多才多艺的问题解决能力,远远超出了自然语言处理(NLP)任务的范围(Fu&Khot,2022)。最近的研究揭示了LLMs的新兴能力,例如在少样本提示任务上的性能提升(Wei et al.,2022b)。LLMs的卓越性能引起了学术界和工业界的兴趣,人们相信它们可能成为本时代人工通用智能(AGI)的基础(Chang等,2024;Zhao等,2023b;Wei等,2022b)。一个显著的例子是ChatGPT,专为参与人类对话而设计,它表现出理解和生成人类语言文本的能力(Liu等,2023g)。
在LLMs之前,研究人员一直在探索将表格数据与神经网络集成,用于NLP和数据管理任务(Badaro等,2023)。如今,研究人员渴望探讨LLMs在处理各种任务时的能力,例如预测、表格理解、定量推理和数据生成(Hegselmann等,2023;Sui等,2023c;Borisov等,2023a)。表格数据是机器学习(ML)中普遍且重要的数据格式之一,在金融、医学、商业、农业、教育等领域广泛应用,这些领域严重依赖关系数据库(Sahakyan等,2021;Rundo等,2019;Hernandez等,2022;Umer等,2019;Luan&Tsai,2021)。表格数据,通常称为结构化数据,是指按行和列组织的数据,其中每列代表特定的特征。在本节中,论文首先介绍表格数据的特征,然后简要回顾了为这一领域量身定制的传统、深度学习和LLM方法。最后,论文阐述了本文的贡献,并提供了后续章节的布局。
2.1 表格数据的特征
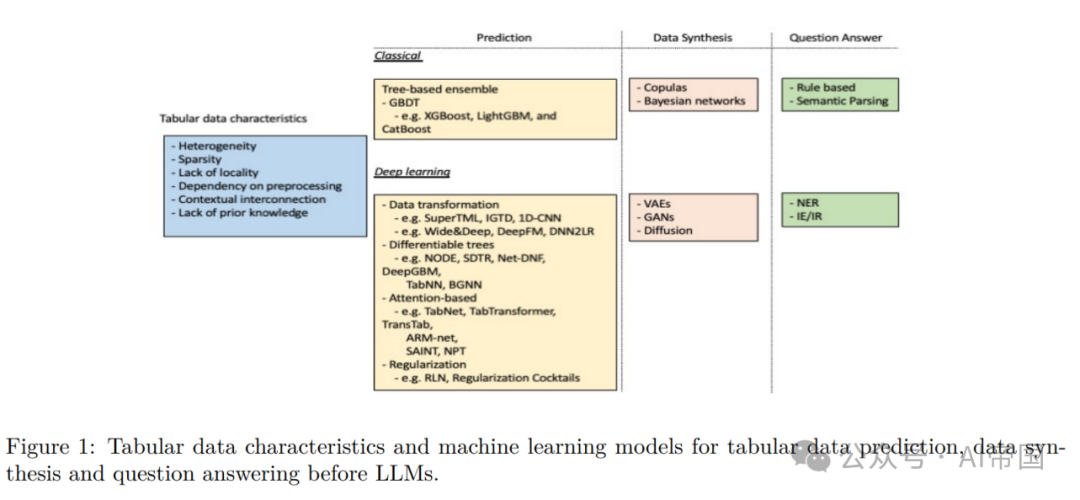
这里讨论表格数据的独特特征和带来的挑战(JQ-:建议在表格数据、表格数据、相关等术语的命名上添加一些澄清):
1.多样性:表格数据可以包含不同类型的特征:分类、数值、二进制和文本。因此,特征可以从密集的数值特征到稀疏或高基数的分类特征(Borisov等,2022)。
2.稀疏性:实际应用,如临床试验、流行病学研究、欺诈检测等,通常涉及到不平衡的类别标签和缺失值,导致训练样本中的长尾分布(Sauber-Cole和Khoshgoftaar,2022)。
3.对预处理的依赖性:在处理表格数据时,数据预处理对特定应用至关重要。对于数值数值,常见的技术包括数据归一化或缩放、分类值编码、缺失值插补和异常值移除。对于分类值,常见的技术包括标签编码或独热编码。不恰当的预处理可能导致信息丢失、稀疏矩阵,并引入多重共线性(例如,使用独热编码)或合成排序(例如,使用有序编码)(Borisov等,2023a)。
4.基于上下文的相互连接:在表格数据中,特征可以相关联。例如,人口统计表中的年龄、教育和饮酒量是相互关联的:年轻时很难获得博士学位,而法定饮酒年龄有一个最低限制。在回归中包含相关的回归变量会导致有偏的系数,因此,模型师必须注意这些复杂性(Liu等,2023d)。
5.无序性:在表格数据中,示例可以进行排序。然而,与与文本和图像数据相反,文本或像素在文本或图像中的位置本质上与之相关,表格示例相对无序。因此,基于位置的方法(例如,空间相关性、妨碍归纳偏见、卷积神经网络(CNN))对于表格数据建模的适用性较差(Borisov等,2022)。
6.缺乏先验知识:在图像或音频数据中,通常存在有关数据的空间或时间结构的先验知识,模型在训练过程中可以利用这些知识。然而,在表格数据中,这样的先验知识通常是缺乏的,使得模型难以理解特征之间的固有关系(Borisov等,2022;2023a)。
2.2 传统与深度学习在表格数据中的应用
传统的基于树的集成方法,如梯度提升决策树(GBDT),仍然是表格数据预测的最新技术(Borisov等,2022; Gorishniy等,2021)。在提升集成方法中,基学习者按顺序学习,以减小先前学习者的错误,直到不再取得显著改进,使其相对于单一学习者更为稳定和准确(Chen&Guestrin,2016)。传统的基于树的模型以其高性能、训练效率高、调整容易和易于解释而闻名。然而,与深度学习模型相比,它们存在一些局限性:
1.基于树的模型对特征工程的敏感性较高,特别是对于分类特征,而深度学习可以在训练期间隐式地学习表示(Goodfellow等,2016)。
2. 基于树的模型不太适用于处理序列数据,例如时间序列,而深度学习模型,如循环神经网络(RNN)和transformers,在处理序列依赖性方面表现出色。
3. 基于树的模型有时在泛化到未见数据方面存在困难,特别是如果训练数据不代表整个分布,而深度学习方法可能对多样化数据集具有更好的泛化能力,因为它们能够学习复杂的表示(Goodfellow等,2016)。
近年来,许多研究探讨了将深度学习用于表格数据建模。这些方法可以大致分为以下几类:
1.数据转换。这些模型要么努力将异构表格输入转换为更适合神经网络的同质数据,如图像,可以在其上应用类似于CNN的机制(SuperTML(Sun等,2019),IGTD(Zhu等,2021b),1D-CNN(Kiranyaz等,2019)),要么关注将特征变换与深度神经网络结合使用(Wide&Deep(Cheng等,2016; Guo&Berkhahn,2016),DeepFM(Guo等,2017),DNN2LR(Liu等,2021))。
2.可微分树。受到集成树性能的启发,这一类方法试图通过平滑决策函数使树可微分(NODE(Popov等,2019),SDTR(Luo等,2021),Net-DNF(Katzir等,2020))。另一类方法将基于树的模型与深度神经网络结合使用,因此可以保持树对处理稀疏分类特征的能力(DeepGBM(Ke等,2019a)),从树中借用先前的结构知识(TabNN(Ke等,2019b)),或通过将结构化数据转换为有向图来利用拓扑信息(BGNN(Ivanov&Prokhorenkova,2021)。
3.基于注意力的方法。这些模型通过注意机制进行特征选择和推理(TabNet(Arik&Pfister,2020),TransTab(Wang&Sun,2022),TabTransformer(Huang等,2020),ARMnet(Cai等,2021)),或者协助样本内信息共享(SAINT(Somepalli等,2021),NPT(Kossen等,2022))。
4.正则化方法。在表格数据中,与图像或文本数据相比,特征的重要性变化较大。因此,这一研究领域试图设计一种优化的动态正则化机制,以调整模型对某些输入的敏感性(例如,RLN(Shavitt&Segal,2018),正则化鸡尾酒(Kadra等,2021)。
尽管在将深度学习应用于表格数据建模方面进行了大量努力,包括XGBoost、LightGBM和CatBoost(Prokhorenkova等,2019)等GBDT算法在大多数数据集中仍然优于深度学习方法,并具有在快速训练时间、高可解释性和易优化性方面的额外优势(Shwartz-Ziv&Armon,2022; Gorishniy等,2021; Grinsztajn等,2022)。然而,在某些情况下,深度学习模型可能在某些方面优于传统方法,例如在面对非常大的数据集或数据主要由分类特征组成的情况下(Borisov等,2022)。
表格数据建模的另一个重要任务是数据合成。合成真实且高质量数据的能力对于模型开发至关重要。当数据稀缺时,数据生成用于增强(Onishi&Meguro,2023),填充缺失值(Jolicoeur-Martineau等,2023)和平衡不平衡数据中的类(Sauber-Cole&Khoshgoftaar,2022)。传统的合成数据生成方法主要基于Copulas(Patki等,2016; Li等,2020)和贝叶斯网络(Zhang等,2017; Madl等,2023),而生成模型的最新进展,如变分自编码器(VAEs)(Ma等,2020; Darabi&Elor,2021; Vardhan&Kok,2020; Liu等,2023d; Xu等,2023b),生成对抗网络(GANs)(Park等,2018; Choi等,2018; Baowaly等,2019; Xu等,2019),扩散(Kotelnikov等,2022; Xu等,2023a; Kim等,2022b; a; Lee等,2023; Zhang等,2023c)和LLMs,开辟了许多新机会。与经典方法(如贝叶斯网络(Xu等,2019))相比,这些深度学习方法在合成数据生成方面表现出更高的性能。
表格问答(QA)是来自表格数据的自然语言研究问题。许多早期的方法对BERT(Devlin等,2019)进行微调,使其成为表格相关任务的表格编码器,例如TAPAS(Herzig等,2020),TABERT(Yin等,2020b),TURL(Deng等,2022a),TUTA(Wang等,2021)和TABBIE(Iida等,2021)。例如,
•TAPAS通过引入额外的嵌入来捕获表格结构,从而扩展了BERT的掩码语言模型目标,以适应结构化数据。它还集成了两个分类层,以促进单元格的选择并预测相应的聚合运算符。
•特定的表格QA任务Text2SQL涉及将自然语言问题转换为结构查询语言(SQL)。早期的研究通过手工制作的特征和语法规则进行语义解析(Pasupat&Liang,2015b)。
•当表格不是来自非数据库表格时,如Web表格、电子表格表格等,语义解析也用于(Jin等,2022)。
•Seq2SQL是一个通过强化学习使用序列到序列深度神经网络来生成WikiSQL任务中查询条件的方法(Zhong等,2017a)。
•一些方法是基于草图的,其中将自然语言问题转换为草图。随后,使用类似于类型导向草图完成和自动修复的编程语言技术,以迭代方式完善初始草图,最终生成最终查询(例如SQLizer(Yaghmazadeh等,2017))。
•另一个例子是SQLNet(Xu等,2017),它使用列注意机制基于依赖图相关的草图合成查询。
•SQLNet的一个衍生物是TYPESQL(Yu等,2018a),它也是一种基于草图的槽填充方法,涉及提取用于填充各自插槽的基本特征。
•与先前的监督式端到端模型不同,TableQuery是一个在自由文本的QA上进行预训练的NL2SQL模型,它消除了将整个数据集加载到内存并序列化数据库的必要性。
2.3 大模型(LLMs)概述
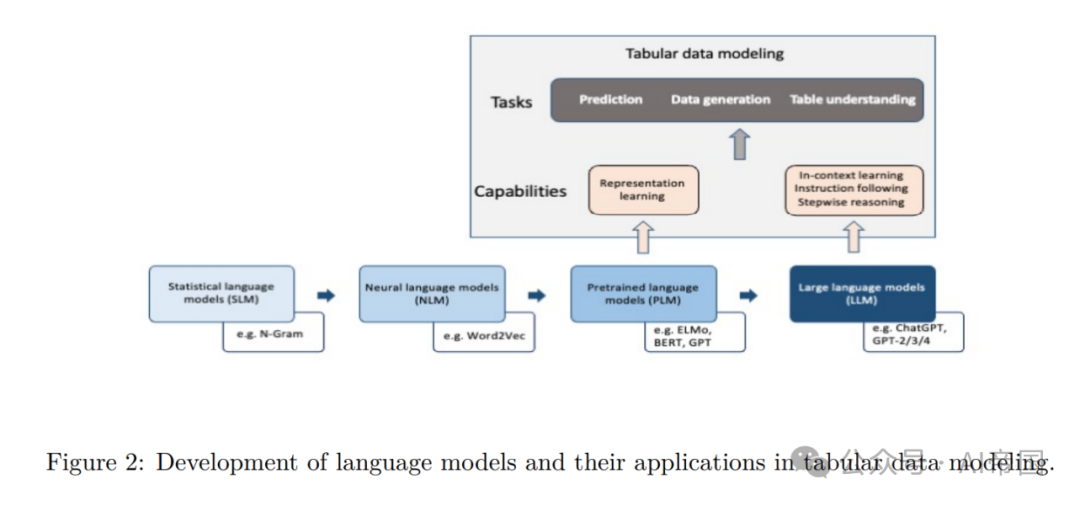
语言模型(LM)是一种概率模型,用于预测单词序列中未来或缺失标记的生成可能性。赵等人(2023b)对LM的发展进行了全面审查,并将其划分为四个不同阶段:第一阶段是统计语言模型(SLM),它学习了来自先前单词的示例序列的单词出现概率(例如N-Gram),基于马尔可夫假设(Saul&Pereira,1997)。尽管通过增加上下文窗口可以实现更准确的预测,但SML受到高维度和高计算需求的限制(Bengio等人,2000)。接下来,神经语言模型(NLM)利用神经网络(例如循环神经网络(RNN))作为概率分类器(Kim等人,2016)。
除了学习单词序列的概率函数之外,NLM的一个关键优势是它们可以学习每个单词的分布式表示(即词嵌入),使相似的单词在嵌入空间中靠近彼此(例如Word2Vec),从而使模型对未在训练数据中出现的序列进行泛化,并有助于缓解维度灾难(Bengio等人,2000)。
后来,与学习静态词嵌入不同,引入了通过在大规模未注释的语料库上进行预训练的上下文感知表示学习,该表示考虑了上下文(例如,ELMo(Peters等人,2018a)),在各种自然语言处理(NLP)任务中显示出显著的性能提升(Wang等人,2022a; Peters等人,2018b)。沿着这一线路,提出了几种其他预训练语言模型(PLM),利用具有自注意机制的变压器架构,包括BERT和GPT2(Ding等人,2023)。
与转移学习密切相关的预训练和微调范式使模型能够在文本语料库上获得一般的句法和语义理解,然后在特定于任务的目标上进行训练以适应各种任务。LM的最终和最近的阶段是大型语言模型(LLMs),将是本文的重点。由于观察到扩大数据和模型规模通常会带来更好的性能,研究人员试图测试更大尺寸的PLM性能的边界,例如文本到文本转移变压器(T5)(Raffel等人,2023),GPT-3(Brown等人,2020)等。有趣的是,一些先进的能力也随之出现。这些大型PLMs(即LLMs)展示了超越传统语言建模的前所未有的强大能力(也称为新兴能力),开始具备解决更一般和复杂任务的能力,这在PLM中是看不到的。正式地,论文如下定义LLM:
定义1(大型语言模型)。由θ参数化的大型语言模型(LLM)M是一个基于变压器的模型,其架构可以是自回归、自编码或编码器-解码器。它已在包含数百万到数万亿令牌的大型语料库上进行训练。LLMs包括预训练模型,并且对于论文的调查,指的是具有至少10亿参数的模型。
LLMs的一些关键新兴能力对于数据理解和建模至关重要,包括上下文学习、遵循指令和多步推理。上下文学习是指设计大型自回归语言模型,该模型在未见任务上生成响应,而不通过梯度更新,仅通过自然语言任务描述和在提示中提供的一些上下文示例进行学习。具有1750亿参数的GPT3模型(Brown等人,2020)展示了在较小模型中看不到的令人印象深刻的上下文学习能力。LLMs还通过仅遵循任务描述的指令(也称为零提示)展示了完成新任务的能力。
一些论文还报告了在各种任务上对LLMs进行微调,这些任务被呈现为指令(Thoppilan等人,2022)。然而,据报道,仅对更大尺寸的模型(Wei等人,2022a; Chung等人,2022)进行指令微调效果最好。对于LLMs来说,解决涉及多个步骤的复杂任务一直是具有挑战性的。通过包含中间推理步骤,提示策略,如链式思考(CoT),已被证明有助于解锁LLM处理复杂算术、常识和符号推理任务的能力(Wei等人,2023)。LLMs的这些新能力为探索将它们整合到超越传统NLP应用的复杂任务中奠定了基础,涵盖了各种数据类型。
2.3.1 LLMs在表格数据中的应用
尽管语言模型在处理自然语言处理任务方面具有出色的能力,但其在表格数据学习方面的利用受到固有数据结构差异的限制。一些研究努力试图利用PLM中包含的通用语义知识,主要是基于BERT的模型,来建模表格数据(图2)。这涉及使用PLM学习考虑头信息的语义信息的上下文表示(Chen等人,2020b)。典型的方法包括通过序列化将表格数据转换为文本(在第2节中有详细解释),并采用类似BERT中的掩码语言建模(MLM)方法对PLM进行微调,如PTab、CT-BERT、TABERT(Liu等人,2022a; Ye等人,2023a; Yin等人,2020a)所示。除了能够整合来自列名的语义知识外,将异构表格数据转换为文本表示还使PLM能够接受来自各种表格的输入,从而实现跨表格训练。
此外,由于表格数据缺乏局部性质,模型需要展现特征列的排列不变性(Ye等人,2023a)。因此,TABERT被提出作为在自然语言句子和结构化数据上训练的PLM(Yin等人,2020a),PTab证明了跨表格训练对于增强表示学习的重要性(Liu等人,2022a),CT-BERT采用了掩码表格建模(MTM)和对比学习进行跨表格预训练,优于基于树的模型(Ye等人,2023a)。然而,以前的研究主要集中在使用LM进行表示学习,这相当有限。
2.3.2 LLMs在表格数据建模中的机会
今天许多研究探讨了使用LLMs在各种表格数据任务中的潜力,包括预测、数据生成以及数据理解(进一步细分为问答和数据推理)。这一探索受到了LLMs的独特能力的推动,如上下文学习、遵循指令和逐步推理。将LLMs应用于表格数据建模的机会如下:
1.深度学习方法通常在其最初未经训练的数据集上表现不佳,因此使用预训练和微调范式进行迁移学习非常有前景(Shwartz-Ziv&Armon,2022)。
2.将表格数据转换为LLM可读的自然语言可以解决在表格预处理期间使用高维分类数据的单热编码所带来的维度灾难。
3.新兴能力,例如通过CoT进行的逐步推理,已将LM从语言建模转变为更一般的任务解决工具。需要研究LLM在表格数据建模中新兴能力的极限。
在本文的其余部分,论文将全面回顾使用LLMs建模表格数据的最新进展。在第2节中,论文介绍了与为LLMs调整表格数据相关的关键技术。随后,论文涵盖了LLMs在预测任务中的应用(第3节),数据增强和丰富任务(第4节),以及问答/表格理解任务(第5节)。最后,第6节讨论了限制和未来方向,第7节总结。
2. 4 贡献
本工作的主要贡献如下:
1.对LLMs在表格数据应用中关键技术的正式拆分。论文将LLM在表格数据中的应用拆分为表格数据预测、表格数据合成、表格数据问答和表格理解。论文进一步提取可适用于所有应用的关键技术。论文将这些关键技术组织成一个分类体系,研究人员和从业者可以利用该体系来描述其方法、找到相关技术并了解这些技术之间的区别。论文进一步将每个技术细分为子部分,以便研究人员能够轻松找到相关的基准技术,并正确分类其提出的技术。
2.LLMs在表格数据应用中的度量调查和分类。对于每个应用,论文对可以用于评估该应用性能的各种度量进行分类和讨论。对于每个应用,论文记录了所有相关方法的度量,并确定了每类度量的优势/局限性,以捕捉应用性能。在必要时,论文还提供了推荐的度量。
3.LLMs在表格数据应用中的数据集调查和分类。对于每个应用,论文确定了通常用于基准测试的数据集。对于表格理解和问题回答,论文通过其下游应用进一步按数据集进行分类:问题回答、自然语言生成、分类、自然语言推理和文本到SQL。论文还根据任务和其GitHub链接提供了推荐的数据集。从业者和研究人员可以查看该部分,轻松找到相关数据集。
4.LLMs在表格数据应用中的技术调查和分类。对于每个应用,论文通过步骤细分了广泛的表格数据建模方法。例如,表格数据预测可以通过预处理(修改模型输入)、目标增强(修改输出)、微调(微调模型)进行细分。论文在每个阶段构建了细粒度的子类别,以便在方法类别之间绘制相似性和趋势,并以主要技术的示例进行说明。从业者和研究人员可以查看该部分,了解每种技术的差异。论文仅推荐基准方法,并提供这些技术的GitHub链接供参考和基准。
5.对未来工作应解决的关键问题和挑战的概述。论文挑战未来的研究解决表格数据建模中的偏见问题,减轻幻觉,找到更好的数值数据表示,提高模型容量,形成标准基准,提高模型可解释性,创建集成工作流程,设计更好的微调策略,并提高下游应用的性能。
3 LLMs在表格数据中的关键技术
在进行调查时,论文注意到在使用LLMs模型对各种任务中的表格数据进行建模时有一些共同的组件。论文在本节中讨论了常见的技术,如序列化、表格操作、提示工程和构建端到端系统。微调LLMs也很受欢迎,但往往是应用特定的,因此论文将有关微调的讨论留在第3和第5节。
3.1 序列化
由于LLMs是序列到序列模型,为了将结构化的表格数据作为输入馈送到LLMs中,论文必须将结构化的表格数据转换为文本格式(Sui等人,2023b; Jaitly等人,2023)。

基于文本:表1描述了文献中常见的基于文本的序列化方法。一种直接的方法是直接输入一个可读的编程语言数据结构(例如Python的Pandas DataFrame Loader,以行分隔的JSON文件格式,由列表表示的数据矩阵,反映表的HTML代码等)。或者,可以将表格转换为X分隔值,其中X可以是任何合理的分隔符,如逗号或制表符。一些论文使用基于列标题和单元格值的模板将表格转换为人类可读的句子。根据论文的调查,最常见的方法是Markdown格式。
基于嵌入的方法:许多论文还采用了来自预训练语言模型(PLMs)的表格编码器进行微调,以将表格数据编码为数值表示,作为LLMs的输入。有多个基于BERT(Devlin等,2019)构建的表格编码器,用于处理与表格相关的任务,如TAPAS(Herzig等,2020)、TABERT(Yin等,2020b)、TURL(Deng等,2022a)、TUTA(Wang等,2021)、TABBIE(Iida等,2021)和UTP(Chen等,2023a)。对于参数超过1B的LLMs,存在UniTabPT(Sarkar&Lausen,2023)(基于T5和Flan-T5模型,拥有3B参数)、TableGPT(Gong等,2020)(基于GPT2,拥有1.5B参数)和TableGPT2(Zha等,2023)(基于Phoenix(Chen等,2023b),拥有7B参数)等模型。
基于图和树的方法:一种可能的、但较少探索的序列化方法涉及将表格转换为图形或树状数据结构。然而,在使用序列到序列模型时,这些结构仍然必须转换回文本。对于Zhao等人(2023a)来说,将表格转换成树形结构后,将每个单元格的分层结构、位置信息和内容表示为元组,然后输入到GPT3.5中。
比较:研究表明,LLMs的性能对输入表格格式敏感。Singha等人(2023)发现DFLoader和JSON格式对于查找事实和表格转换任务更为适用。与此同时,Sui等人(2023a)发现HTML或XML表格格式比X分隔格式更容易被GPT模型理解,适用于表格问答和FV任务,但它们需要更多的标记。同样,Sui等人(2023b)还发现,对于GPT3.5和GPT4,标记语言,特别是HTML,优于X分隔格式。他们的假设是GPT模型在大量网络数据上进行了训练,因此在解释表格时可能更多地暴露于HTML和XML格式。
除了手动模板外,Hegselmann等人(2023)还使用了LLMs(在ToTTo(Parikh等,2020b)、T0++(Sanh等,2022)、GPT-3(Ouyang等,2022)上进行了微调的BLOOM模型)生成表的描述作为句子,模糊了基于文本和基于嵌入的序列化方法之间的界限。然而,在Few-shot分类任务中,他们发现传统的列表和文本模板优于基于LLM的序列化方法。在LLMs中,模型越复杂越大,性能越好(GPT-3具有175B,T0具有11B,微调的BLOOM模型具有0.56B参数)。导致LLMs在将表格序列化为句子时表现较差的一个关键原因是LLMs具有产生幻觉的倾向:LLMs会用无关的表达方式回应,添加新数据或返回不忠实的特征。
3.2 表格操作
表格数据的一个重要特点是其在结构和内容上的异构性。它们通常具有不同维度、涵盖各种特征类型的大型尺寸。为了使大型语言模型(LLMs)能够有效地摄取表格数据,将表格紧凑地适应上下文长度是很重要的,这有助于提高性能并降低成本。
将表格压缩以适应上下文长度,以提高性能和降低成本 对于较小的表格,可能可以在提示中包含整个表格。然而,对于较大的表格,存在三个挑战:
首先,一些模型具有较短的上下文长度(例如,Flan-UL2(Tay et al., 2023b)支持2048个标记,Llama 2(Touvron et al., 2023b)支持4096个上下文标记),即使支持较大上下文长度的模型如果表格超过20万行,仍然可能不足够(Claude 2.1支持最多20万个标记)。
其次,即使表格可以适应上下文长度,由于自注意力的二次复杂度(Sui et al., 2023b; Tay et al., 2023a; Vaswani et al., 2017),大多数LLMs在处理长句子时效率较低。当模型必须在长上下文中访问相关信息时,即使对于明确支持长上下文的模型(Liu et al., 2023b),LLMs的性能在处理长上下文时也会显着降低。对于表格数据,Cheng et al. (2023); Sui et al. (2023c)强调,在大型表格中,噪声信息成为LLMs的一个问题。
第三,更长的提示会导致更高的成本,特别是对于构建在LLM API上的应用程序。
为解决这些问题,Herzig et al. (2020); Liu et al. (2022c)提出了根据最大序列长度截断输入的朴素方法。Sui et al. (2023b)引入了预定义的某些限制,以满足LLM调用请求。另一种策略是进行搜索和检索,仅获取高度相关的表格、行、列或单元格,论文将在后面的第5节中讨论。
为了提高性能而添加表格的额外信息 除了表格之外,一些论文还探讨了将表格模式和统计信息作为提示的一部分。Sui et al. (2023c)探讨了在提示的一部分中包含有关表格的其他信息:例如,“维度、度量、语义字段类型”这样的信息有助于LLM在探索的六个数据集中实现更高的准确性。“统计特征”提高了包含较高比例统计单元格内容的任务和数据集的性能,如FEVEROUS(Aly et al., 2021)。与此同时,“文档引用”和“术语解释”为表格添加了上下文和语义含义。“表格大小”带来的改进较小,而“标题层次结构”增加了不必要的复杂性,并影响了性能。
LLM对表格操作的性能鲁棒性 Liu et al. (2023e)对GPT3.5在表格结构扰动(转置和洗牌)中的性能鲁棒性进行了批判性分析。他们发现,LLMs在解释表格方向时受到结构偏见的影响,当被要求对表格进行转置时,LLMs的性能非常差(准确率50%)。然而,LLMs可以确定第一行或第一列是否是标题(准确率94-97%)。Zhao et al. (2023e)研究了SOTA表格QA模型对表头、表格内容和自然语言问题(措辞)的操纵的影响。他们发现,所有受检视的表格QA模型(TaPas、TableFormer、TaPEX、OmniTab、GPT3)在对抗性攻击下都不具有鲁棒性。
3.3 提示工程
提示是输入到LLM的文本。设计一个有效的提示是一项非常复杂的任务,而且许多研究主题都是从单纯的提示工程中延伸出来的。在本小节中,论文涵盖了提示工程中常用的技术,以及研究人员如何在涉及表格的任务中使用它们。
提示格式 最简单的格式是将任务描述与序列化的表格拼接成字符串。然后,LLM将尝试执行描述的任务并返回基于文本的答案。清晰定义和格式良好的任务描述被报道为有效的提示(Marvin et al., 2023)。一些改进性能的策略在接下来的几段中描述。Sui等人(2023b)建议在提示中将外部信息(如问题和陈述)放在表格之前,以提高性能。
上下文学习 作为LLM的新兴能力之一(见1.3),上下文学习是指将类似的例子纳入以帮助LLM理解所需输出。Sui等人(2023b)观察到,在从1-shot设置更改为0-shot设置时,性能大幅下降,所有任务的整体准确性降低了30.38%。在选择适当的例子方面,Narayan等人(2022)发现,他们手动策划的例子在平均F1分数上比随机选择的例子表现更好,提高了14.7个点。对于Chen(2023)来说,从1-shot增加到2-shot通常可以使模型受益,然而,进一步增加并没有导致更多的性能提升。
思维链和自一致性 思维链(CoT)(Wei等人,2022c)促使LLM通过逐步思考来分解任务,从而实现更好的推理。思维方案(Chen等人,2022)使用与代码相关的注释来指导LLM,例如“论文逐步编写一个程序…”。Zhao等人(2023d)探讨了数值QA任务的CoT和PoT策略。Yang等人(2023)用一个shot CoT演示例子来促使LLM生成推理和答案。随后,他们将推理文本(由特殊的“”标记表示)作为输入的一部分,用于微调较小的模型以生成最终答案。
自一致性(Self-consistency,SC)(Wang等人,2023b)利用了这样一个直觉,即复杂的推理问题通常有多种不同的思考方式,从而导致唯一的正确答案。SC从LLM中采样多种不同的推理路径,然后通过边缘化采样的推理路径选择最一致的答案。在这些策略的启发下,Zhao等人(2023a); Ye等人(2023b)尝试了多轮对话策略,他们将原始问题分解为子任务或子问题,以引导LLM的推理。Sui等人(2023c)指导LLM“识别与陈述相关的最后一个表的关键值和范围”以获取被馈送到最终LLM的额外信息,为五个数据集获得了更高的得分。Liu等人(2023e)还研究了围绕SC的策略,以及自我评估,后者根据问题的性质和每个答案的清晰度引导LLM在两种推理方法之间进行选择。Deng等人(2022b)对一组候选序列进行共识投票,然后通过多数投票对基于多数投票的派生响应进行整体选择最终响应。
Chen(2023)研究了CoT和SC对QA和FV任务的影响。在调查LLM预测的可解释性时,Dinh等人(2022)尝试了一个多轮的方法,要求GPT3解释其自上一轮的预测,然后使用CoT引导解释响应,通过添加行“让论文逻辑思考。这是因为”的方式。
检索增强生成(RAG) 检索增强生成(RAG)依赖于这样一种直觉,即LLMs是通用模型,但如果用户在提示中包含相关上下文,它们可以被引导到领域特定的答案。通过将表格作为提示的一部分,本次调查中描述的大多数论文都可以归因为RAG系统。在RAG中的一个特定挑战是从大量数据中提取最相关的信息以更好地为LLMs提供信息。这个挑战在2.2节中稍有重叠,提到了表格抽样的策略。除了前面提到的方法之外,Sundar&Heck(2023)设计了一种基于双编码器的Dense Table Retrieval(DTR)模型,以对表格的单元格进行排序以适应查询的相关性。排名的知识源被纳入提示,并导致顶级ROUGE分数。
角色扮演 另一种流行的提示工程技术是角色扮演,它是指在提示中包含有关LLM应在完成任务时扮演的角色的描述。例如,Zhao等人(2023a)尝试了提示“假设你是统计分析专家”。
3.4 端到端系统
由于LLMs能够生成任何基于文本的输出,除了生成可读的人类响应外,它还可以生成其他程序可读的代码。Abraham等人(2022)设计了一个模型,将自然语言查询转换为结构化查询,可以针对数据库或电子表格运行。刘等人(2023e)设计了一个系统,其中LLM可以与Python进行交互,执行命令,处理数据,并在Pandas DataFrame中详细检查结果,最多进行五次迭代。张等人(2023d)演示了论文可以从SQL工具中获得错误,然后将其馈送回LLMs。通过实施这种调用LLMs的迭代过程,他们提高了SQL查询生成的成功率。最后,刘等人(2023c)提出了一种无代码数据分析平台,该平台使用LLMs生成数据摘要,包括生成用于分析所需的相关问题以及对数据解析器的查询。张等人(2023g)的一项调查涵盖了有关用于表格数据查询和可视化的自然语言界面的更多概念,深入研究了文本转SQL和文本转Vis领域的最新进展。
4 LLMs 用于预测
有几项研究试图利用LLMs进行来自表格数据的预测任务。本节将深入探讨与两类表格数据相关的现有方法和进展:标准基于特征的表格数据和时间序列数据。与普通基于特征的表格数据不同,时间序列预测的预测能力主要依赖于过去的时间序列数值。对于每个类别,论文将其划分为包括预处理、微调和目标增强在内的不同步骤。预处理解释了不同预测方法如何为语言模型生成输入。预处理包括序列化、表格操作和提示工程。目标增强将LLMs的文本输出映射到预测任务的目标标签。最后,论文将简要介绍使用LLMs的特定领域预测方法。
4.1 数据集
对于任务特定的微调,大多数预测任务的数据集都来自UCI ML、OpenML或Manikandan等人(2023)创建的9个数据集的组合。论文将所有细节放在表2中。建议使用这9个数据集的组合,因为它包含比OpenML和UCI ML更大规模的数据集和更多样的特征集。对于一般的微调,现有的方法选择Kaggle API,因为它有169个数据集,并且这些数据集非常多样。
4.2 表格预测
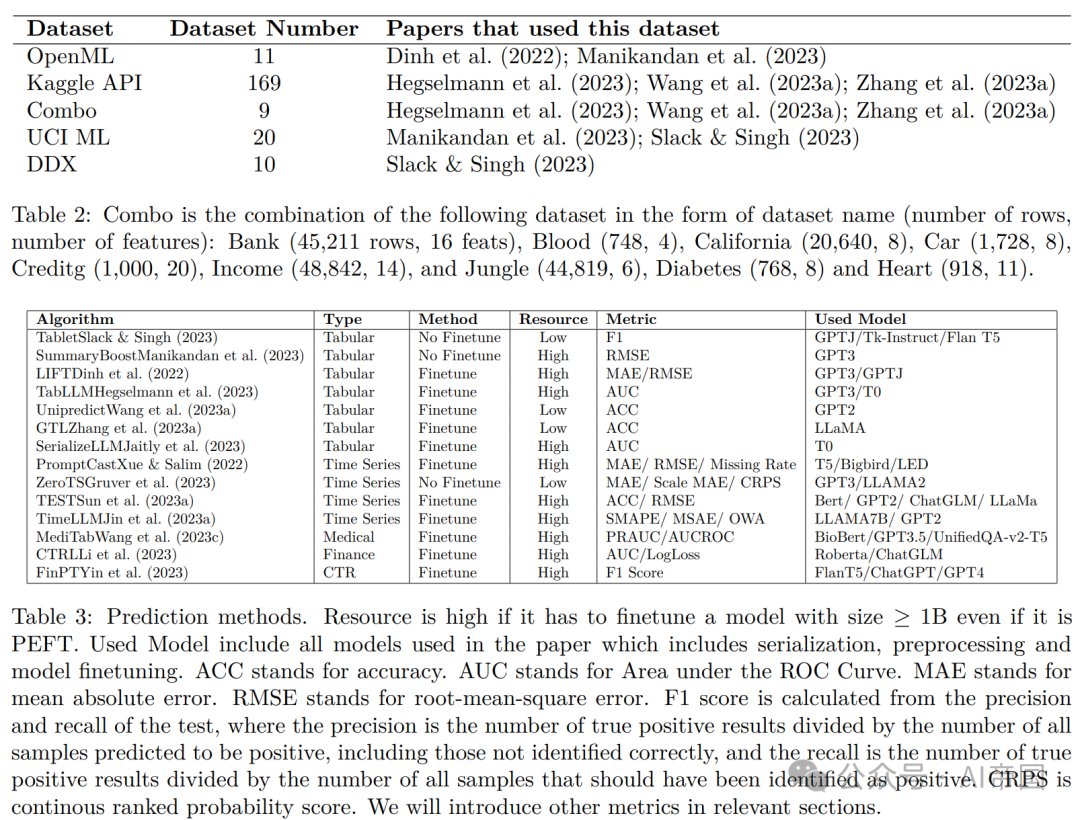
预处理:在预测任务中,序列化主要是基于文本的。表格操作包括数据集的统计数据和元数据。提示工程包括特定任务提示和相关样本。论文在表4中对不同的预处理方法进行了说明。
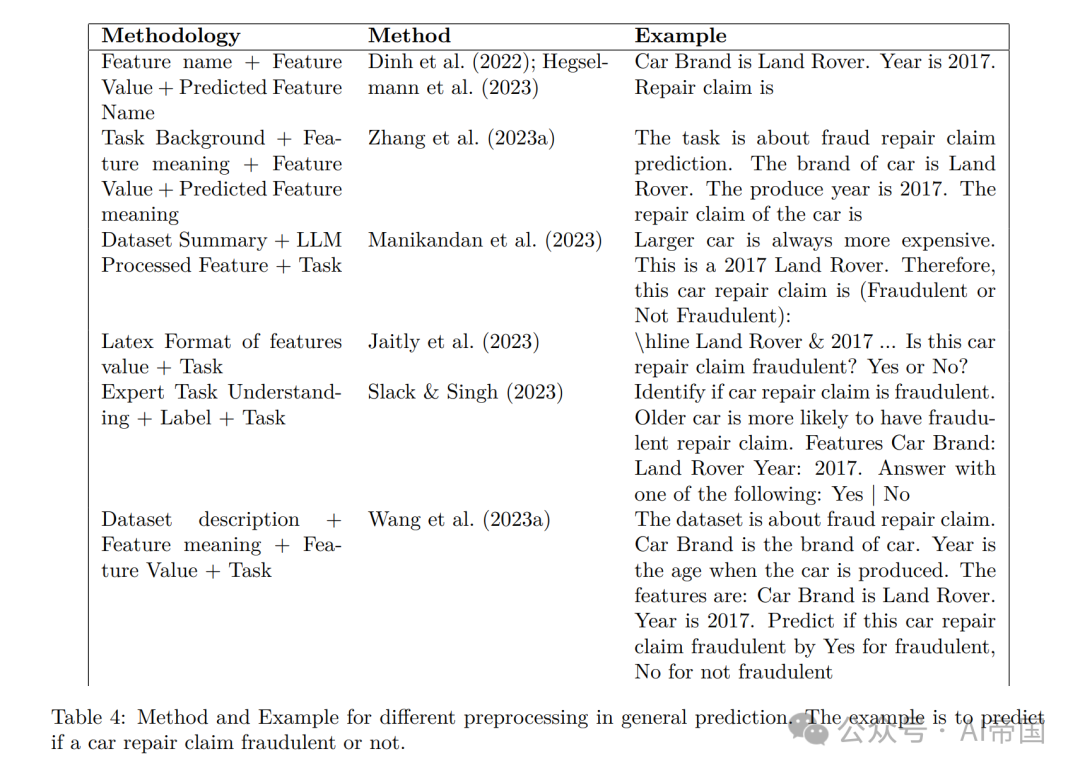
作为最早的尝试之一,LIFT(Dinh等人,2022)尝试了一些不同的序列化方法,例如将特征和值作为自然语句,如“列名为Value”,或一系列方程式,如col1 = val1,col2 = val2,…前者被证明在低维任务中尤其能够取得更高的预测准确性。TabLLM(Hegselmann等人,2023)也得出了相同的结论,他们评估了9种不同的序列化方法。他们发现对所有特征进行文本枚举 - '列名为Value’的方法效果最好。他们还为分类问题添加了描述。对于医学预测,他们模仿了医学专业人员的思考过程作为提示工程。他们发现,在Few Shot Learning的设置中,LLMs实际上利用了列名及其关系。
在随后的研究中,TABLET(Slack&Singh,2023)除了示例序列化外,还包括了自然发生的说明。在这种情况下,任务是进行医学状况预测,自然发生的说明来自于消费者友好的来源,例如政府健康网站或技术参考文献,如默克手册。它包括说明、示例和测试数据点。他们发现,这些说明显著提高了零样本F1性能。然而,LLMs有时仍会忽略说明,导致预测失败。沿着这个思路,更多的研究测试了比简单连接特征和值更复杂的序列化和提示工程方法。基于模式的提示工程通常包括数据集的背景信息、任务描述、摘要和示例数据点。Summary Boosting(Manikandan等人,2023)将数据和元数据序列化为文本提示,用于摘要生成。这包括对数值特征进行分类,并使用基于语言嵌入的加权分层抽样选择的代表性数据集子集。Serilize-LM(Jaitly等人,2023)引入了3种提高LLM性能在特定领域数据集中的序列化技术。他们将相关特征组合成一个句子,使提示更具描述性且更易于LLM理解。以车辆分类为例,像制造商、颜色和车身类型等属性现在被合并成一个更丰富的句子。它利用协方差识别最相关的特征,并将其标记为关键,或添加一句话来解释最重要的特征。最后,他们将表格数据转换为LaTeX代码格式。然后,该表的LaTeX表示法被用作微调LLM的输入,只需通过带有hline标记的行表示,而不需要任何标题。UniPredict(Wang等人,2023a)通过将任意输入M合并为目标描述和特征的语义描述,对元数据进行了重新格式化。特征序列化遵循“列名为值”的格式,…目标是最小化适应的LLM函数生成的输出序列与从目标增强生成的参考输出序列之间的差异(由序列化目标表示)。生成式表格学习(GTL)由(Zhang等人,2023a)提出,包括两个部分:1)第一部分指定任务背景和描述,可选地包括一些上下文示例(提示工程);2)第二部分描述要推断的当前实例的特征含义和值(序列化);对于研究人员和从业者,论文建议对LIFT、TABLET和TabLLM进行新的预处理方法基准测试,因为它们的方法具有代表性且文档清晰。其代码可供使用。
其他一些方法利用LLM来重写序列化或进行提示工程。TabLLM(Hegselmann等人,2023)表明LLM在序列化方面表现不佳,因为它不是忠实的,可能会产生幻觉。Summary Boosting(Manikandan等人,2023)使用GPT3将元数据转换为数据描述,并为每个样本轮生成子集数据的摘要。TABLET(Slack&Singh,2023)适应简单的模型,如单层规则集模型或在任务的完整训练数据上选择的10个最重要的特征原型。然后,它使用模板将逻辑序列化为文本,并使用GPT3修改模板。根据他们的实验,生成的指导并没有显著提高性能。因此,除非序列化需要总结长输入,否则不建议使用LLM来重写序列化。
目标增强:LLMs可以通过文本生成解决复杂任务,然而,输出并不总是可控的(Dinh等人,2022)。因此,将LLMs的文本输出映射到预测任务的目标标签是必不可少的。论文称之为目标增强。一个直接但费时的方法是手动标记,Serilize-LM(Jaitly等人,2023)采用这种方法。LIFT(Dinh等人,2022)使用###和@@@进行问题-答案分离和生成结束,将答案放在两者之间。为了减轻无效推理,LIFT进行了五次推理尝试,如果全部失败,则默认使用训练集的平均值。TabLLM(Hegselmann等人,2023)使用口头化器(Cui等人,2022)将答案映射到有效类别。UniPredict(Wang等人,2023a)具有最复杂的目标增强。他们通过称为“增强”的函数将目标标签转化为每个类别的概率集。形式上,对于任意数据集D中的目标T,他们定义了一个函数增强(T) = C,P,其中C是具有语义意义的新目标的类别,P是分配给每个类别的概率。他们将目标扩展为分类的独热编码,然后使用外部预测器创建校准的概率分布。这取代了0/1的独热编码,同时保持最终的预测结果。形式上,给定目标类别t ∈ 0,…,|C|和目标概率p ∈ P,他们定义了一个函数serialize target(t, p),将目标类别和概率序列化为格式为“class t1: p1, t2: p2,…”的序列。论文在5中为每种方法提供了一个示例。虽然在某些情况下,定制的目标增强可能是有用的,但出于其易于实现的便利性,简单的Verbalizer是推荐的,并且可以为输出分配概率。
仅推理预测:一些工作直接使用LLMs进行预测,而无需进行微调,论文将这些方法称为仅推理预测。TABLET(Slack&Singh,2023)利用Tk-Instruct(Wang等人,2022b)11b,Flan-T5(Chung等人,2022)11b,GPT-J(Black等人,2022)6b和ChatGPT等模型进行推理,但发现使用类似的例子和说明时,采用具有来自XGBoost的特征权重的KNN方法超过了Flan-T5 11b的性能。Summary Boosting(Manikandan等人,2023)通过序列化步骤创建多个输入。然后,AdaBoost算法通过基于摘要的弱学习器创建一个集成。虽然非微调的LLMs在处理连续属性时效果不佳,但在较小的数据集上,摘要增强是有效的。此外,通过利用现有模型知识使用GPT生成的描述来增强其性能,突显了LLMs在有限数据领域中的潜力。然而,在存在许多连续变量时,其性能不佳。对于没有任何微调的新LLM基于预测的方法,论文建议对LIFT和TABLET进行基准测试。LIFT是基于推理的预测的第一种LLM方法。与LIFT相比,TABLET显示了明显更好的性能。这两种方法都有可用的代码。
微调:对于涉及微调的研究,它们通常采用两种不同的方法之一。第一种方法是在大型数据集上训练LLM模型,以学习在将其适应特定预测任务之前的基本特征。第二种方法是采用预先训练的LLM,并在更小的、特定的预测数据集上进行进一步的训练,以专门化其知识并提高其在预测中的性能。LIFT(Dinh等人,2022)使用低秩适应(LoRA)对训练集上的预训练语言模型进行微调,如GPT-3和GPT-J。他们发现,具有通用预训练的LLM能够提高性能。但是,这种方法的性能并不超过上下文学习结果。TabLLM(Hegselmann等人,2023)使用T0模型(Sanh等人,2021)和t few(?)进行微调。TabLLM展示了卓
越的few-shot学习能力,超过了传统的深度学习方法和梯度提升树。TabLLM的效力在于其能够利用预先训练的LLM中编码的丰富知识,需要最少的标记数据。然而,TabLLM的样本效率在很大程度上取决于任务。Jaitly等人(2023)使用T0(Sanh等人,2021)。它使用内在基于关注的提示调整(IA3)(Liu等人,2022b)进行训练。然而,这种方法只适用于few-shot学习,当shots数量大于或等于128时,性能不及基线。T0模型(Sanh等人,2021)通常用作表格预测微调的基本模型。
UniPredict(Wang等人,2023a)在包含169个表格数据集的聚合上训练单个LLM(GPT2),观察到比现有方法更大的优势。该模型不需要在特定数据集上微调LLM。当样本数较小时,模型的准确性和排名比XGBoost好。在进行了目标增强的情况下,该模型的性能明显优于没有增强的模型。当列数过多或特征较少时,其性能不佳。TabFMs(Zhang等人,2023a)微调LLaMA以预测下一个标记。论文还剩下115个表格数据集。为了平衡不同数据集之间的实例数量,论文从每个表格数据集中随机抽取多达2048个实例进行GTL。他们采用了GTL,显著改善了LLaMA在大多数零射击场景中的性能。根据当前的证据,论文认为在大量数据集上进行微调可能会进一步提高性能。然而,UniPredict和GTL都尚未发布其代码。
度量:论文建议在分类预测中报告AUC,而在回归中报告RMSE,因为它们在文献中通常是最常用的。
4.3 时间序列预测
与基于特征的表格数据预测(具有数值和分类特征)相比,时间序列预测更注重数值特征和时间关系。因此,序列化和目标增强更关注如何最好地表示数值特征。许多论文声称它们使用LLM进行时间序列预测。然而,这些论文中大多数使用的LLM都小于1B。论文将不在此处讨论这些方法。请参阅(Jin等人,2023b)以获取这些方法的完整介绍。
预处理:PromptCast(Xue&Salim,2022)使用输入时间序列数据本身,并将其转换为具有任务最小描述的测试格式,将目标作为句子转换为输出。ZeroTS(Gruver等人,2023)声称数字在原始LLM编码方法中未被很好地编码。因此,它通过将数字分解为GPT-3和LLaMA分别的几位数字或每个单个数字来进行编码。它使用空格和逗号进行分隔并省略小数点。Time LLM(Jin等人,2023a)涉及将时间序列修补为嵌入,并将它们与单词嵌入集成以创建全面的输入。这个输入通过数据集上下文、任务说明和输入统计作为前缀进行补充。TEST(Sun等人,2023a)引入了一个专门为LLMs定制的嵌入层,使用指数扩张的因果卷积网络进行时间序列处理。通过对比学习生成嵌入,其中包含唯一的正对和使用相似性度量对齐文本和时间序列标记。序列化涉及两个QA模板,将多变量时间序列视为顺序模板填充的单变量序列。
目标增强:在输出映射方面,ZeroTS(Gruver等人,2023)涉及绘制多个样本,并使用统计方法或分位数进行点估计或范围。对于Time-LLM(Jin等人,2023a),输出处理通过展平和线性投影完成。ZeroTS的目标增强方法易于实施7,而TimeLLM的代码不可用。
仅推理预测:与基于特征的表格预测类似,研究人员探索了LLMs在无需微调的情况下进行时间序列预测的性能。ZeroTS(Gruver等人,2023)检查了LLMs(如GPT-3(Brown等人,2020)和LLaMA-70B Touvron等人(2023a))在时间序列预测中的直接使用。它使用平均绝对误差(MAE)、尺度MAE和连续排名概率分数(CRPS)评估模型,指出LLMs对基于规则的简单完成、趋势重复和捕捉的偏好。研究注意到LLMs能够捕捉时间序列数据分布并在没有特殊处理的情况下处理缺失数据。然而,该方法受制于窗口大小和算术能力,阻碍了进一步的改进。
微调:对于时间序列预测,微调模型在当前研究中更常见。PromptCast(Xue&Salim,2022)尝试了推理预测或在特定任务数据集上进行微调的方法。它表明更大的模型始终表现更好。Time LLM(Jin等人,2023a)通过对LLMs进行微调,如LLaMa Touvron等人(2023a)和GPT-2(Brown等人,2020),提出了一种新颖的时间序列预测方法。Time-LLM使用对称平均绝对百分比误差(SMAPE)、平均绝对缩放误差(MSAE)和总体加权平均(OWA)等指标进行评估。它在仅使用5%或10%的数据的few-shot学习场景中展示了显著的性能。这种创新的技术强调了LLMs在处理复杂预测任务中的多功能性。对于TEST(Sun等人,2023a),使用了软提示进行微调。该论文评估了像Bert、GPT-2(Brown等人,2020)、ChatGLM(Zeng等人,2023)和LLaMa Touvron等人(2023a)这样的模型,使用分类准确性和RMSE等指标。然而,结果表明这种方法不如训练小型面向任务的模型高效和准确。总体而言,目前LLaMa是最常用的模型,而软提示似乎是微调的一种合适方法。
度量:均方误差(MAE)是最常见的度量标准。连续排名概率得分(CRPS)捕捉分布特性,允许比较生成样本而无需似然的模型。CRPS被认为是对MAE的改进,因为它不会忽视数据结构,如时间步之间的相关性。对称平均绝对百分比误差(SMAPE)基于百分比误差测量准确性,均值绝对缩放误差(MASE)是一个无尺度误差度量,通过天真基准模型的样本内均方误差进行标准化,而总体加权平均(OWA)是一个综合度量,平均排名SMAPE和MASE,以比较不同方法的性能。尽管引入了新的度量标准,但在文献中,MAE和RMSE仍然是最常用的。我们仍然建议使用MAE和RMSE,因为它们易于实施且易于基准化。

4.4 LLM预测的应用
医学预测:发现像DeBERTa这样的PTL在电子健康记录(EHR)预测任务中表现优于XGBoost(McMaster等,2023)。对于预处理,Meditab Wang等人(2023c)利用GPT-3.5 Brown等人(2020)将表格数据转换为文本格式,重点关注提取关键值。随后,它采用线性化、提示和合理性检查等技术,以确保准确性并减少错误。在微调中,系统进一步利用领域特定数据集上的多任务学习,在额外数据上生成伪标签,并使用数据Shapley分数进行改进。在精炼数据集上进行预训练,然后使用原始数据进行微调。生成的模型支持新数据集的零样本学习和少样本学习。通过OpenAI的API访问的GPT-3.5促进了数据整合和增强,而UnifiedQA-v2-T5 Khashabi等人(2022)用于合理性检查。此外,Meditab还利用了预训练的BioBert分类器Lee等人(2019)。该系统在医学领域内进行了全面评估,展示了与梯度提升方法和现有LLM方法相比的卓越性能。然而,它在医学领域之外的适用性可能有限。我们建议探索提供的代码8,特别是在医学领域的表格预测任务中。除了AUCROC之外,他们还使用精确率召回曲线(PRAUC)进行评估。PRAUC在不平衡的数据集中很有用,而这在医学数据中总是存在的。
金融预测:FinPT(Yin等人,2023)提出了一种基于LLM的金融风险预测方法。该方法涉及将表格金融数据填入预定义的模板中,提示LLM(如ChatGPT和GPT-4)生成自然语言客户概况。然后,这些概况用于微调大型基础模型,如BERT(Devlin等人,2019),采用模型的官方分词器。这个过程增强了这些模型预测金融风险的能力,Flan-T5在这个背景下成为最有效的骨干模型,特别是在八个数据集中。对于金融数据,建议使用9并与FinPT10进行基准测试。
推荐预测:CTRL(Li等人,2023)提出了一种通过使用人为设计的提示将表格数据转换为文本来进行点击率(CTR)预测的新方法,使其能够被语言模型理解。该模型将表格数据和生成的文本数据视为独立的模态,分别输入到协作CTR模型和预训练语言模型(如ChatGLM(Zeng等人,2023))中。CTRL采用两阶段培训过程:第一阶段涉及跨模态对比学习,用于精细的知识对齐,而第二阶段专注于为下游任务微调轻量级协作模型。该方法在三个数据集上超过了所有SOTA基线,包括语义和协作模型,显示了协同和语义信号相结合的范式的卓越预测能力。然而,该方法的代码不可用。他们使用LogLoss和AUC来评估该方法。对于LogLoss,LogLoss的下限为0表示两个分布完全匹配,而较小的值表示更好的性能。
5 LLMs用于表格数据合成
论文专注于数据合成的关键作用。对于复杂数据集的不断需求促使对利用LLMs增强表格数据的新方法进行探索。本节审查了阐明将LLMs与表格数据结合起来进行数据合成的变革潜力的方法。
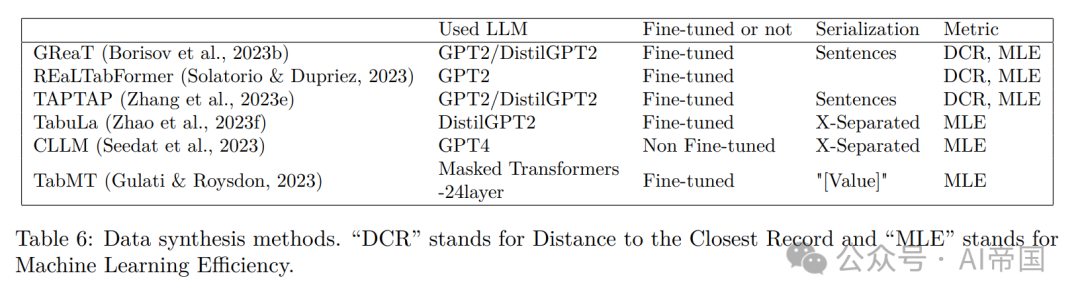
5.1 方法论
Borisov等人(2023b)提出了GReaT11(生成真实表格数据),用于生成具有原始表格数据特征的合成样本。GReaT数据流程包括一个文本编码步骤,使用表1中显示的句子序列化方法将表格数据转换为有意义的文本,然后进行GPT-2或GPT-2 distill模型的微调。此外,特征顺序置换步骤在使用获取的句子进行LLM微调之前。
REaLTabFormer(Solatorio&Dupriez,2023)通过生成合成的非关联和关联表格数据,扩展了GReaT。它使用一个自回归的GPT-2模型生成一个父表,并使用条件于父表的序列到序列模型进行关联数据集。该模型实现了目标掩码以防止数据复制,并引入了用于检测过拟合的统计方法。它在捕捉关联结构方面表现出优越性能,并在不需要微调的情况下在预测任务中取得了最先进的结果。
在相似的范式下,Zhang等人(2023e)提出了TAPTAP12(表格预训练用于表格预测),该方法融入了几个增强功能。该方法涉及对GPT2进行450个Kaggle/UCI/OpenML表格的预微调,使用机器学习模型生成标签列。声称的改进包括修订的数值编码方案和使用外部模型(如GBDT)生成伪标签,偏离传统的基于语言模型的方法。然而,该工作没有与基于扩散的模型(如TabDDPM)进行比较,而且(Gruver等人,2023)中突出显示的数值编码方案的改进取决于所使用的模型。在相关工作中(Wang等人,2023a),采用了类似的方法生成伪标签,其中标签表示为概率向量。
TabuLa(Zhao等人,2023f)通过倡导将随机初始化的模型作为起点,解决了LLMs训练时间较长的问题,并展示了通过对连续表格数据任务进行迭代微调来持续改进的潜力13。它引入了一种标记序列压缩方法和中间填充策略,以简化训练数据表示并提高性能,从而在保持或提高合成数据质量的同时显著减少了训练时间。
Seedat等人(2023)引入了Curated LLM,这是一个利用学习动态和两个新颖策划指标(置信度和不确定性)的框架。这些指标用于在分类器的训练过程中过滤掉不理想的生成样本,旨在产生高质量的合成数据。具体而言,这两个指标是为每个样本计算的,利用对这些样本进行训练的分类器。此外,CLLM通过不需要LLMs的任何微调来区分自己,特别是利用GPT-4。
TabMT(Gulati&Roysdon,2023)采用了一种基于掩码变换器的体系结构。该设计能够有效处理各种数据类型,并支持缺失数据插补。它利用掩码机制增强隐私和数据效用,确保在数据真实性和隐私保护之间取得平衡。TabMT的体系结构是可扩展的,适用于各种数据集,并在合成数据生成任务中展示出改进的性能。
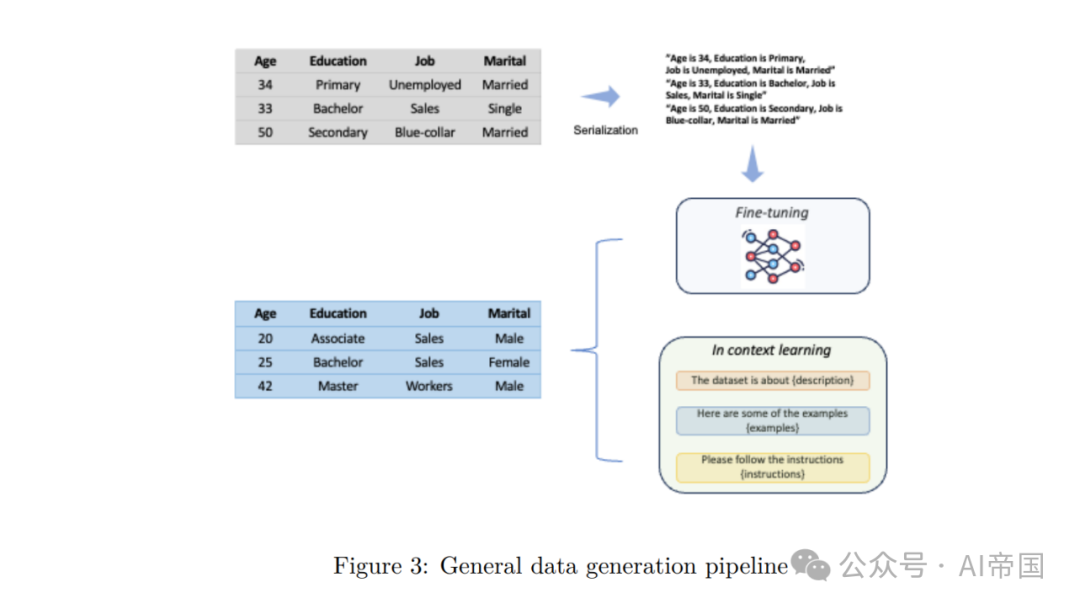
5.2 评估
正如Zhang等人(2023c)所述,可以从四个不同的维度来评估合成数据的质量:
1.低阶统计 - 逐列密度和逐对列相关性,估计单个列密度和列对之间的关系动态。
2.高阶指标 - 计算α-精度和β-召回分数,用于测量合成数据的整体保真度和多样性。
3.隐私保护 - DCR分数,代表原始数据的中位数到最接近记录(DCR)的距离,用于评估原始数据的隐私级别。
4.在下游任务上的性能 - 如机器学习效率(MLE)和缺失值插补。MLE用于在合成生成的表格数据上训练时,与在真实数据上测试的测试准确度进行比较。此外,数据生成的质量还可以通过其在缺失值插补任务中的性能来评估,该任务侧重于使用可用的部分列数据补充不完整的特征/标签。
6 LLMs用于问答和表格理解
在本节中,论文涵盖了研究人员探讨问题回答(QA),事实验证(FV)和表格推理任务所使用的数据集、趋势和方法。有许多论文致力于数据库操作、管理和集成(Lobo等人,2023; Fernandez等人,2023; Narayan等人,2022; Zhang等人,2023b),其中还包括对LLMs的指令和表格输入。然而,它们通常不被称为QA任务,本文不会涵盖这些内容。
6.1 数据集
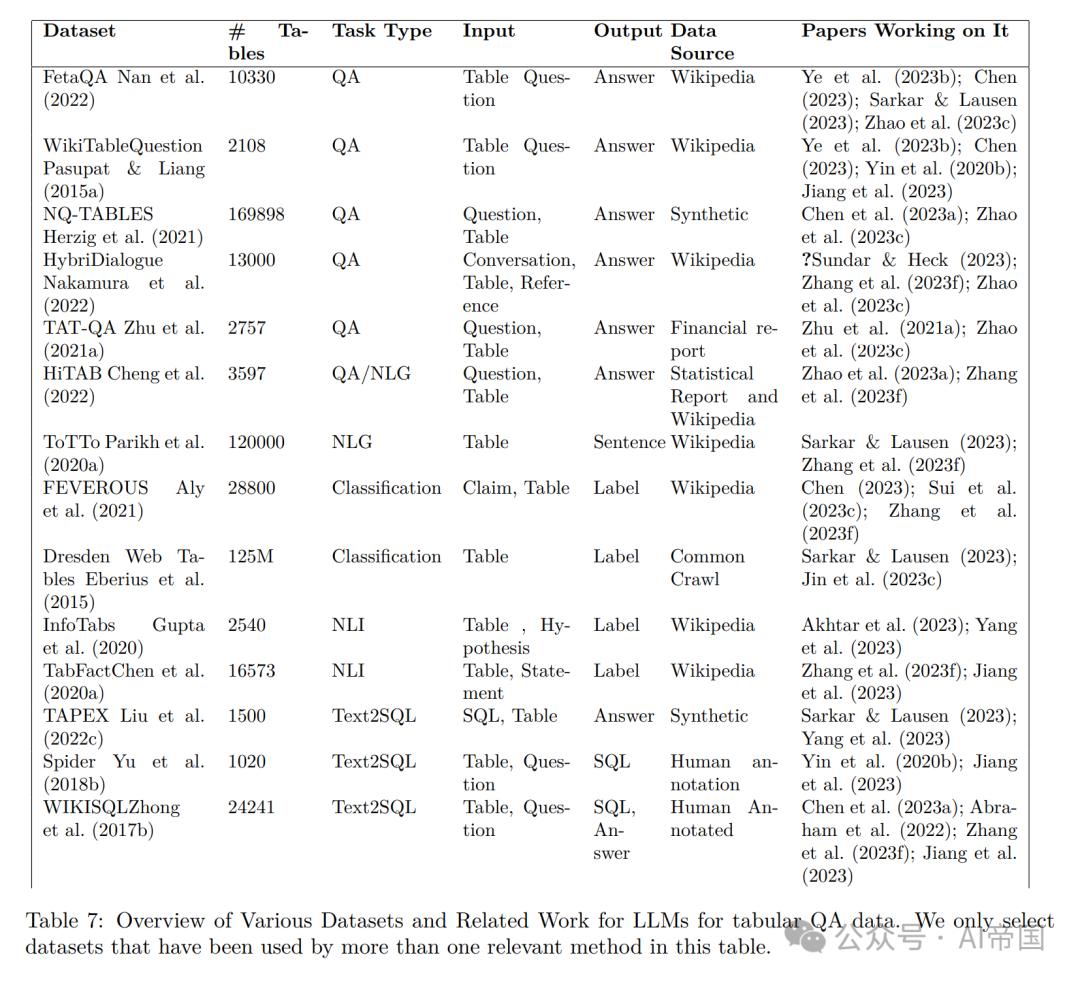
表7概述了文献中用于表格QA任务的一些流行数据集和基准。
•Table QA:对于表格QA数据集,论文建议在WikiTableQuestion(Pasupat&Liang,2015a)之上对FetaQA(Nan等人,2022)进行基准测试。与侧重于评估QA系统理解查询并从表格数据中检索短格式答案的WikiTableQuestions不同,FeTaQA引入了需要更深层次推理和信息集成的元素。这包括生成涉及从结构化知识源(如表格)中检索、推理和集成多个不连续事实的自由文本答案。这要求模型生成长、详细且自由形式的答案。
•NQ-TABLES:Herzig等人(2021)的NQ-TABLES比先前提到的表格更大。其优势在于强调可以使用结构化表格数据回答的开放领域问题。代码在脚注14中。
•Table and Conversation QA:对于涉及对话和表格的QA任务,论文建议使用HybriDialogue(Nakamura等人,2022)。HybriDialogue包含基于维基百科文本和表格的对话。这解决了当前对话系统中的一个重要挑战:在不同模态之间(特别是文本和表格)分布信息的话题对话。数据集在脚注15中。
•Table Classification:如果任务涉及使用非结构化文本和结构化表格进行事实验证,论文建议使用FEVEROUS(Aly等人,2021)进行基准测试。对于需要对Web表格布局进行分类的任务,特别是在数据提取和Web内容分析中表格结构至关重要的情况下,论文建议使用Dresden Web Tables(Eberius等人,2015)。数据集在脚注16中。
•Text2SQL:如果要创建SQL执行器,可以使用TAPEX(Liu等人,2022c)和WIKISQL(Zhong等人,2017b),其中包含表格、SQL查询和答案。如果要测试编写SQL查询的能力,可以使用Spider(Yu等人,2018b)17、Magellan(Das等人)或WIKISQL(Zhong等人,2017b)。总体而言,WIKISQL更可取,因为它的大小较大,并且已经被许多现有方法(如Chen等人,2023a; Abraham等人,2022; Zhang等人,2023f; Jiang等人,2023)进行了基准测试。数据集在脚注18中。
•Table NLG:ToTTo(Parikh等人,2020a)旨在为源表创建自然而忠实的描述。它在规模上很大,可用于基准测试表格条件文本生成任务。HiTAB(Cheng等人,2022)允许在不同NLG模型和任务之间进行更标准化和可比较的评估,从而可能在该领域获得更可靠和一致的基准测试。数据集在脚注19中。
•Table NLI:InfoTabs(Gupta等人,2020)使用维基百科信息框,旨在促进对半结构化表格文本的理解,涉及理解文本片段及其隐含关系。InfoTabs对于研究在半结构化、多领域和异构数据上进行复杂、多方面的推理非常有用。TabFact(Chen等人,2020a)由人工注释的有关维基百科表的自然语言陈述组成。它需要语言推理和符号推理以获得正确答案。数据集在脚注20中。
•领域特定:对于特定于航空业的表格问题回答,论文建议使用AIT-QA(Katsis等人,2022)。它突显了领域特定表格所带来的独特挑战,例如复杂的布局、分层标题和专业术语。对于语法描述,论文建议使用TranX(Yin&Neubig,2018)。它使用用于目标表示的抽象语法描述语言,实现高准确性和在不同类型的意义表示之间的普适性。对于与金融相关的表格问题回答,论文建议使用TAT-QA(Zhu等人,2021a)。该数据集要求进行答案推理的数字推理,涉及加法、减法和比较等操作。因此,TAT-QA可用于复杂任务的基准测试。数据集在脚注21中。
•预训练:对于在大型数据集上进行表格理解的预训练,论文建议使用TaBERT(Yin等人,2020c)和TAPAS(Herzig等人,2020)。Tapas数据集有620万个表,对语义解析非常有用。TAPAS有2600万个表及其相关的英文上下文。它可以帮助模型更好地理解文本和表格。数据集在脚注22中。
6.2 LLMs在QA中的一般能力
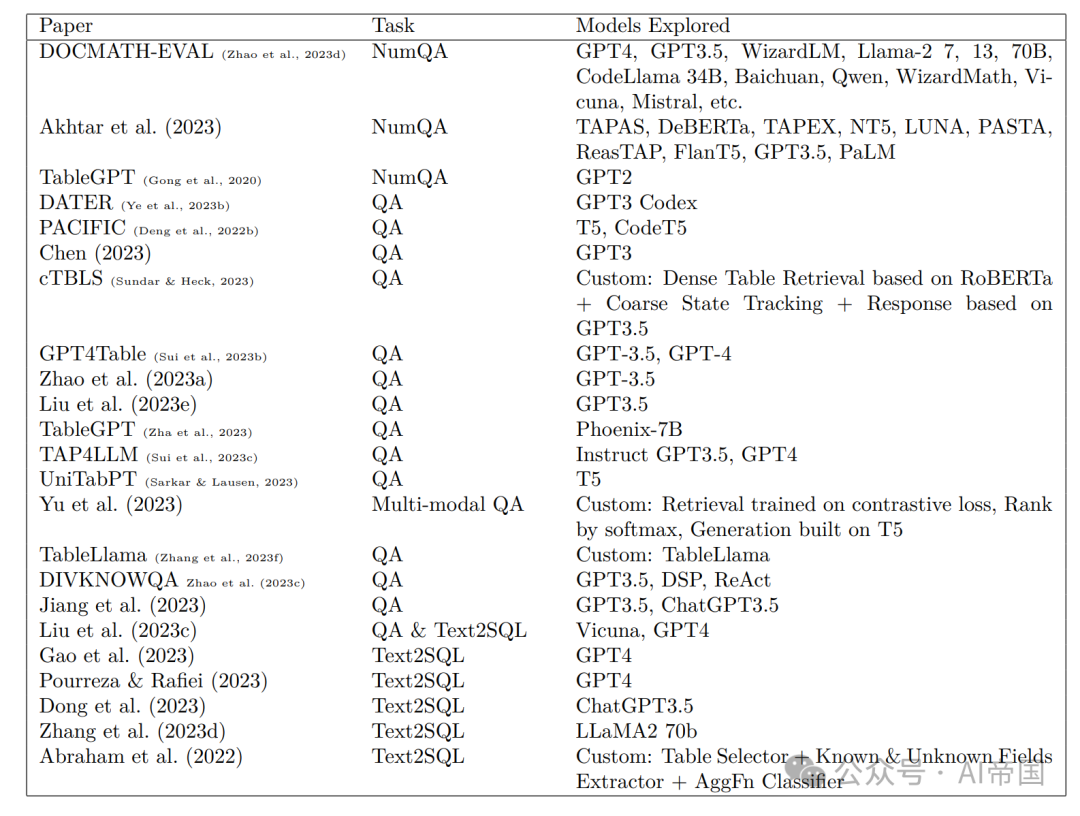
表8概述了调查LLMs在QA和推理上的有效性以及所探讨的模型的论文。当今最流行的LLM是GPT3.5和GPT4。尽管这些GPT模型并未专门针对基于表格的任务进行优化,但许多论文发现它们在执行复杂的表格推理任务时表现出色,特别是当与CoT等提示工程技巧相结合时。在本节中,论文总结了LLMs在QA任务中的一般发现,并强调已报告工作良好的模型。
数字QA:一个特定的QA任务涉及回答需要数学推理的问题。例如,一个查询可能是“美国运通每笔交易的平均支付金额是多少?”许多现实世界的QA应用(例如处理财务文件、年度报告等)涉及这类数学推理任务。到目前为止,Akhtar等人(2023)得出结论,像FlanT5和GPT3.5这样的LLMs在各种数字推理任务上表现比其他模型更好。在DOCMATH-EVAL数据集上,GPT-4与CoT显著优于其他LLMs,而开源LLMs(LLaMa-2、Vicuna、Mistral、Starcoder、MPT、Qwen、AquilaChat2等)则落后。
Text2SQL:Liu等人(2023c)设计了一个问题匹配器,识别三种关键字类型:1) 与列名相关的术语,2) 与限制相关的短语(例如“前十名”),和3) 算法或模块关键字。一旦识别出这些关键字,模块就会开始将与每个列相关的具体限制合并为一个统一的组合,然后与第三种类型的关键字指示的SQL算法或模块进行匹配。Zhang等人(2023d)选择了一种更为简单的方法,即要求LLaMa-2根据问题和表格模式生成SQL语句。Sun等人(2023b)在Text2SQL任务上对PaLM-2进行了微调,在Spider上取得了可观的性能。Spider目前的最高得分模型是Dong等人(2023);Gao等人(2023);Pourreza&Rafiei(2023),都是基于OpenAI的GPT模型构建的。SQL生成在行业中很受欢迎,有许多开源的经过微调的模型可用。
模型大小对性能的影响:Chen(2023)发现大小确实重要:在WebTableQuestions上,比较6.7B和175B的GPT-3模型时,较小的模型只达到了较大模型一半的分数。在TabFact上,他们发现较小的模型(<=6.7B)几乎获得了随机准确性。
微调还是不微调?:根据论文的调查,微调LLMs(>70B参数)的工作在表格QA领域中很少。这可能是因为LLMs(GPT3.5、GPT4)在许多QA任务上都能够在没有微调的情况下执行。对于Spider上的SQL生成,DIN-SQL Pourreza&Rafiei(2023)和DAIL-SQL是使用GPT4的基于推理的技术,并超过了先前微调的较小模型。在使用较小的LLMs进行QA微调的论文不是本文关注的焦点,之前在2.1节的基于嵌入的序列化下提到过。相反,大多数基于LLMs的表格QA论文关注提示工程、搜索和检索以及端到端流程(用户界面)等方面,论文将在下一节中进一步描述。
6.3 关键组成部分在问答中
在最简单的问答架构中,一个LLM接受一个输入提示(查询和序列化表格)24,并返回一个答案。在更复杂的架构中,系统可能连接到外部数据库或程序。大多数时候,知识库可能无法适应LLM的上下文长度或内存。因此,LLM在表格问答中面临的独特挑战包括:查询意图消歧、搜索和检索、输出类型和格式,以及需要在程序之间进行迭代调用的多轮设置。论文在本节中进一步描述这些组件。
6.3.1 查询意图消歧
Zha等人(2023)引入了“指挥链”(Chain-of-command,CoC)的概念,将用户输入转化为一系列中间命令操作。例如,LLM首先需要检查任务是否需要检索、数学推理、表格操作,以及如果指令过于模糊则无法回答问题。他们构建了一个指令链数据集,用于微调LLM以生成这些命令。Deng等人(2022b)提出将QA任务分为三个子任务:澄清需求预测(CNP)确定是否需要提出澄清不确定性的问题;澄清问题生成(CQG)在CNP检测到需要澄清时生成澄清问题作为回应;对话问答(CQA)直接生成答案作为回应,如果不需要澄清。他们训练了一个UniPCQA模型,通过多任务学习统一了QA中的所有子任务。
6.3.2 搜索与检索
准确地从结构化数据的特定位置检索信息是LLM至关重要的能力。有两种类型的搜索和检索用例:(1)查找与问题相关的信息(表格、列、行、单元格),(2)获取额外的信息和示例。
对于主表格,Zhao等人(2023d)观察到检索模块(返回前n个最相关文档)的性能更好,能够始终提高LLM在数字QA中的最终准确性。Sui等人(2023c)探索了多种表格抽样方法(行和列)和表格打包方法(基于标记限制参数)。最佳技术是基于查询的抽样,它检索与问题具有最高语义相似性的行,超越了不抽样、聚类、随机、均匀抽样或内容快照的方法。Dong等人(2023)使用ChatGPT对表格进行排名,根据其与问题的相关性使用SC:他们生成十组检索结果,每组包含前四个表格,然后选择在这十组中出现最频繁的一组。为了进一步过滤列,通过指定ChatGPT将列名与问题词匹配或外键应放在前面来对所有列进行排名。
类似地,使用了SC方法。cTBLS Sundar和Heck(2023)设计了一个三步架构,用于检索并生成基于检索到的表格信息的对话响应。在第一步中,使用RoBERTa初始化的基于双编码器的密集表格检索(DTR)模型识别与查询最相关的表格。在第二步中,使用三元组损失训练的粗略系统状态跟踪系统用于对单元格进行排名。最后,使用GPT-3.5提示生成一个自然语言响应,以回应根据粗略状态跟踪器从表格中排名的单元格提出的后续查询。提示包括对话历史、排名的知识源和要回答的查询。他们的方法产生了比以前的方法更连贯的响应,表明表格检索、知识检索和响应生成的改进导致更好的下游性能。Zhao等人(2023d)使用OpenAI的Ada Embedding4和Contriever(Izacard等人,2022)作为密集检索器,BM25(Robertson等人,1995)作为稀疏检索器。这些检索器有助于从源文档中提取与问题最相关的文本和表格证据的前n个最相关文本和表格证据,然后将其作为输入上下文提供给回答问题。
对于额外信息,一些论文探讨了用于上下文学习样本的技术。Gao等人(2023)探索了一些方法:
(1)随机选择:随机选择k个示例;
(2)问题相似度选择:基于与问题Q的语义相似性选择k个示例,基于问题和示例嵌入的预定义距离度量(例如欧氏或负余弦相似性)和kNN算法选择k个与Q最相似的示例;
(3)掩码问题相似度选择:类似于(2),但在问题中事先掩码领域特定信息(表格名称、列名称和值);
(4)查询相似度选择:选择与目标SQL查询s相似的k个示例,这依赖于另一个模型生成基于目标问题和数据库的目标SQL查询s’,因此s’是对s的一个近似。输出查询被编码为二进制离散语法向量。Narayan等人(2022)探讨了手动筛选和随机示例选择。
6.3.3 多轮任务
一些论文设计了调用LLM的迭代流程。论文将进行这样做的用例分类为三个桶:(1)将具有挑战性的任务分解为可管理的子任务,(2)根据新的用户输入更新模型输出,以及(3)绕过特定约束或解决错误。
中间子任务:这一部分与前文第2.3节中讨论的CoT和SC的概念有重叠。简而言之,由于推理任务可能很复杂,LLM可能需要指导来将任务分解为可管理的子任务。例如,为了改进下游表格推理,Sui等人(2023b)提出了一种两步自我增强提示方法:首先使用提示要求LLM生成有关表格的附加知识(中间输出),然后将响应合并到第二个提示中,以请求下游任务的最终答案。Ye等人(2023b)还引导LLM将庞大的表格分解为小表格,并将复杂问题转化为更简单的子问题以进行文本推理。他们的策略在表格推理方面取得了显著更好的结果,在TabFact数据集上首次超过了人类表现。对于Liu等人(2023e),在鼓励符号CoT推理路径方面,他们允许模型与可以执行命令、处理数据并审查结果的Python shell进行交互,特别是在pandas dataframe中,最多进行五个迭代步骤。
基于对话的应用:在用户与LLM进行交互的各种应用中,例如在聊天机器人中,流水线必须允许迭代调用LLM。一些基于对话的Text2SQL数据集可供考虑,例如SParC(Yu等人,2019b)和CoSQL(Yu等人,2019a)数据集。对于SParC,作者基于Spider(Yu等人,2018b)设计了后续的追问问题。
绕过约束或错误调试:Zhao等人(2023a)使用多轮提示来解决表格超过API输入限制的情况。在其他情况下,特别是如果生成的LLM输出是代码,通过将错误反馈给LLM的迭代过程可以帮助LLM生成正确的代码。Zhang等人(2023d)通过这种方式改进了SQL查询生成。
6.3.4 输出评估和格式
如果QA输出是数字或类别,则常用F1或准确性评估指标。如果评估开放式回答,除了使用ROUGE和BLEU等典型措施外,一些论文还聘请评估员评估LLM响应的信息性、连贯性和流畅性,如Zhang等人(2023g)所述。当连接到诸如Python、Power BI等程序时,LLM的输出不仅限于文本和代码。例如,从文本和表格输入创建可视化任务也很流行,如Zhang等人(2023g)和Zha等人(2023)所述。
7 限制和未来方向
LLMs已经在许多表格数据应用中使用,例如预测、数据合成、问题回答和表格理解。在这里,论文概述一些实际限制,并考虑未来研究的方向。
偏见和公正性:LLMs倾向于从其训练数据中继承社会偏见,这显著影响它们在表格预测和问题回答任务中的公正性。Liu等人(2023f)使用GPT3.5进行少样本学习,以评估在上下文学习中表格预测的公正性。研究得出结论,LLMs倾向于从其训练数据中继承社会偏见,这显著影响它们在表格预测任务中的公正性。不同子组的公正性指标差距仍然大于传统机器学习模型中的差距。此外,研究进一步揭示,颠倒上下文示例的标签明显缩小了不同子组之间的公正性指标差距,但以预期的降低预测性能为代价。通过提示缓解LLM的固有偏见是困难的(Hegselmann等人,2023)。因此,一个有前途的方法是通过预处理(Shah等人,2020)或优化(Bassi等人,2024)来缓解偏见。
幻觉:LLMs有产生与真实世界事实或用户输入不一致的内容的风险(Huang等人,2023)。幻觉引发了人们对LLMs在实际应用中可靠性和实用性的担忧。例如,在处理患者记录和医疗数据时,幻觉会带来严重后果。Akhtar等人(2023)发现,幻觉导致LLMs在推理方面的性能下降。为了解决这些问题,Wang等人(2023c)加入了一个审计模块,利用LLMs执行自检和自校正。他们生成了伪标签,然后使用数据审计模块,该模块根据数据Shapley分数对数据进行过滤,从而得到一个更小但更干净的数据集。其次,他们还删除了任何具有False值的单元格,从而消除了LLMs对这些无效值进行错误推断的可能性。最后,他们通过LLM的反思进行了一次理智检查:他们使用输入模板“What is the {column}? {x}”查询LLM,以检查答案是否与原始值匹配。如果答案不匹配,通过重新提示LLM来纠正描述。然而,这种方法远非高效。更好的处理幻觉的方法可以使LLMs在表格数据建模中更加实用。
数值表示:揭示LLM在内部嵌入中的数值特征的固有关系不适用(Gruver等人,2023),因此需要特定的嵌入。记号化在语言模型中影响模式形成和操作。传统方法,如GPT-3中使用的Byte Pair Encoding(BPE),通常将数字拆分为不对齐的记号(例如,将42235630拆分为[422, 35, 630]),使算术变得复杂。新型模型如LLaMA将每个数字单独记号化。这两种方法使得LLM难以理解整个数字。此外,根据Spathis&Kawsar(2023),整数的记号化缺乏连贯的小数表示,导致一种片段化的方法,其中甚至基本的数学运算也需要记忆而不是算法处理。开发新的标记器(如LLaMA中使用的标记器)的方法,该标记器在算术任务中优于GPT-4,涉及重新思考标记器设计,以更有效地处理混合文本和数值数据,例如通过将每个数字拆分为单独的标记以进行一致的数字标记化(Gruver等人,2023),显示了在提高对符号和数值数据的理解方面的潜力。然而,这极大地增加了输入的维数,使该方法对于大型数据集和许多特征来说并不实际。
分类表示:表格数据集往往包含过多的列,可能导致序列化输入字符串超过语言模型的上下文限制,从而增加成本。这是有问题的,因为它导致数据的部分被修剪,从而负面影响了模型的性能。此外,存在与分类特征的糟糕表示相关的问题,例如无意义的字符,模型难以有效处理和理解。另一个问题是不充分或模糊的元数据,特征的列名和元数据不清楚或无意义,导致模型对输入的解释混乱。需要更好的分类特征编码来解决这些问题。
标准基准:对于表格数据的LLMs可以通过标准化的基准数据集获得巨大好处,以实现模型之间的公正和透明的比较。在这项调查中,论文努力总结常用的数据集/度量标准,并为研究人员和从业者选择数据集提供建议。然而,任务和数据集的多样性仍然是一个显著的挑战,阻碍了对模型性能的公平比较。因此,迫切需要更多标准化和统一的数据集,以有效弥合这一差距。
模型可解释性:与许多深度学习算法一样,LLM的输出缺乏可解释性。只有少数系统能够公开说明其模型输出,例如TabLLM Hegselmann等人(2023)。一种方法是使用Shapley来推导解释。Shapley已被用于评估LLM的提示(Liu等人,2023a)。它还可以用于理解每个特征如何影响结果。例如,在预测疾病时,提供解释是至关重要的。在这种情况下,基本的Shapley解释将能够显示导致最终决策的所有特征。未来的研究需要探索LLM在表格数据理解方面新兴能力的机制。
易于使用:目前,大多数相关模型都需要进行微调或数据序列化,这可能使这些模型难以访问。一些预训练模型,例如Wang等人(2023c),可以使人们更容易使用。如果论文能够将这些模型与自动数据预处理和序列化集成到现有平台,如Hugging Face,那将更容易访问。
微调策略设计:为LLMs设计适当的任务和学习策略至关重要。虽然LLMs展示了新兴的能力,如上下文学习、指令遵循和逐步推理,但这些能力在某些任务中可能并不完全明显,具体取决于所使用的模型。此外,LLMs对于各种序列化和提示工程方法都很敏感,这是将LLM适应未见任务的主要方式。因此,研究人员和从业者需要仔细设计任务和学习策略,以适应特定模型以实现最佳性能。
模型嫁接:通过模型嫁接,可以改善LLM用于表格数据建模的性能。模型嫁接涉及将非文本数据映射到与文本相同的令牌嵌入空间,使用专门的编码器,例如HeLM模型(Belyaeva等人,2023),该模型将螺纹图谱序列和人口统计数据与文本令牌集成。这种方法是高效的,允许与各个领域的高性能模型集成,但由于其非端到端的训练性质,增加了复杂性,并导致组件之间的通信不可读。这种方法可以用于LLM以改善对非文本数据的编码。
论文标题:Large Language Models on Tabular Data - A Survey
论文链接:https://arxiv.org/pdf/2402.17944.pdf
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









