







OK,前文http://blog.csdn.net/lvhao92/article/details/50775860提到了一些围绕贝叶斯的基础概念,极大似然等等。这篇就是介绍大名鼎鼎的朴素贝叶斯分类器
写文章之前百度了一下贝叶斯,发现大多数文章提到贝叶斯就是朴素贝叶斯。其实,这是有问题的。因为两者是不一样的。
如前文所述,计算后验概率P(c|x)的最大难点就是条件概率P(x|c)是所有属性上的联合概率。这是很蛋疼的。所以,朴素贝叶斯为了避开这个,做了“条件独立性假设”:对已知类别,假设所有属性相互独立。就是说每个属性都能独立的对分类结果发生影响。所以,这样,我们的P(x|c)可以写成
d就是属性的数目。Xi就是x在第i个属性上的取值。前一篇文章为了简单理解,所以就只取男生的一类属性(身高)作为例子,其实男生有很多属性:身高,体重,等等。因此,朴素贝叶斯分类器的表达式如下:

接下来我将通过一个很具体的例子--文档过滤来形象的帮助大家理解朴素贝叶斯。功能就是一篇文章,里面有单词,然后通过朴素贝叶斯判断出来这篇是不是垃圾文章,可以用在E-mail的邮件过滤上。在这里,上面的C就是好或者坏,好代表有用文章,坏代表垃圾文章。X就是文章,Xi是特征,就是一个个的单词,聪明的你会发现,其实这里并不能用朴素贝叶斯来做这个事,因为前面所说朴素贝叶斯有个假设:组合的各个属性概率要彼此独立,在这里就是说单词出现于这个分类的概率应该是相互独立的。事实上并不是如此,比如文章中有“医院”这个单词,很有可能就会有“病人”,“医生”这样的单词,他们出现的概率是有相关影响的,并不是相互独立的。但是我们只是在这里举个例子让大家能理解,不要钻牛角尖啦!
(语言是python,虽然我用的最多的工具是matlab,但是matlab对找工作并没有什么用,我也尽力所有的代码将慢慢的转python等等,python也很简单,我尽量多做注释让大家看懂)。
OK
用Notepad++新建一个bay.py文件,接着在里面添加函数
首先我们需要获得单词,下面这是一个以任何非字母类字符为分隔符将文本拆分成一个个单词的函数。
<pre name="code" class="python">import re
import math
def getwords(doc):#doc就是文章啦。
splitter=re.compile('\\W*')#python里将正则表达式编译成正则表达式对象
words=[s.lower() for s in splitter.split(doc)<span style="font-size: 12.0000009536743px; font-family: Arial, Helvetica, sans-serif;">]</span><span style="font-size: 12.0000009536743px; font-family: Arial, Helvetica, sans-serif;"># split是划分,就是对文章进行划分,lower是小写,并且将单词小写</span>
return dict([(w,1) for w in words])#返回一组单词首先,新建一个名为classifier的类:
class classifier:
def __init__(self,getfeatures,filename=None):
self.fc={}#统计特征在各个分类中的数量
self.cc={}#统计每个分类中的文档数量
self.getfeatures=getfeatures#获取特征的方式,我们的例子中就是getwords下面添加的函数就是用以实现计数值的增加和获取:
<pre name="code" class="python"> def incf(self,f,cat):#f为特征,即为单词,cat为类型
self.fc.setdefault(f,{})
self.fc[f].setdefault(cat,0)
self.fc[f][cat]+=1
def incc(self,cat):#增加某一分类的计数值
self.cc.setdefault(cat,0)
self.cc[cat]+=1
def fcount(self,f,cat):#某一个特征出现在某种分类中的次数
if f in self.fc and cat in self.fc[f]:
return float(self.fc[f][cat])
return 0.0
def catcount(self,cat):#返回某个分类中的内容数量
if cat in self.cc:
return float(self.cc[cat])
return 0
def categories(self):#所有分类的列表
return self.cc.keys()
def totalcount(self):#返回所有的值
return sum(self.cc.values()) def train(self,item,cat):
features=self.getfeatures(item)
for f in features:
self.incf(f,cat)#针对这个分类下的每个特征进行计数
self.incc(cat)#增加该分类的计数值
我们来试试看
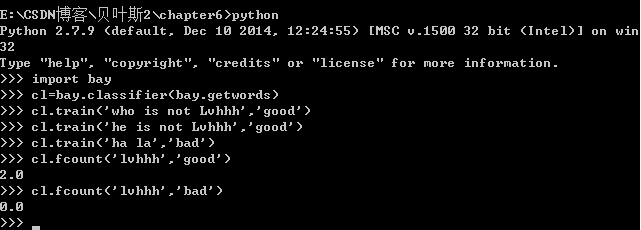
现在,这个计数模块算是完成了。好的,继续。
下面,将上述的计数转化成概率,具体来说,这个概率就是单词在这个分类中出现的概率,也就是用这个单词在属于某个分类的文档中出现的次数除以该分类文档的总述。(我的例子一条语句就是一个文档,简单呀)代码也是非常的简单。
def fprob(self,f,cat):
if self.catcount(cat)==0: return 0 #如果并不存在这个分类,那么返回0
return self.fcount(f,cat)/self.catcount(cat) #该单词属于特定分类除以该分类文档总数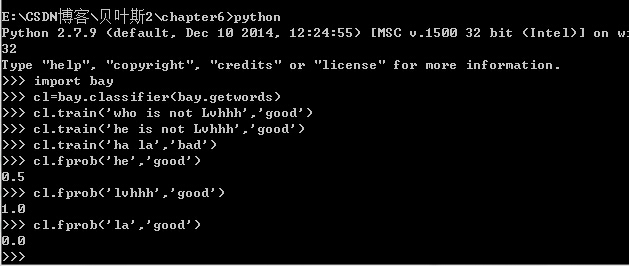
这样就能反馈出概率大小了。这就是我们希望的P(Xi|C)
接下来,我们就可以写朴素贝叶斯的代码了
class naivebayes(classifier):
def docprob(self,item,cat):
features=self.getfeatures(item)
p=1
for f in features: p*=self.fprob(f,cat)#根据朴素贝叶斯的各特征独立P(x|c)为所有特征p(xi|c)的连乘。这个求出来的就是改类别C下,这条句子的概率P(文章|类别)
return p
def prob(self,item,cat):
catprob=self.catcount(cat)/self.totalcount()#求的是P(类别),即这种类别的概率。
docprob=self.docprob(item,cat)
return docprob*catprob #就是P(类别|文章)=P(文章|类别)×P(类别)
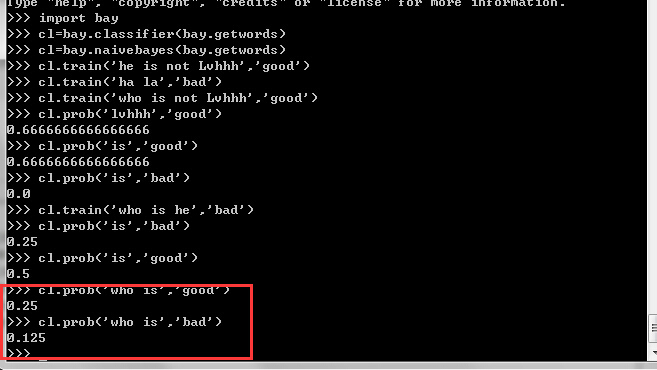
这样,我们比如突然遇到一个句子“who is”,我们并不知道它到底是有用的句子还是垃圾句子,用仅由几条语句训练而成的朴素贝叶斯网络来判断一下,发现更应该偏有用的句子的可能性大点。
总结一下,朴素贝叶斯与其他方法相比比较大的优势在于它在接收大数据量训练和查询时所具备的高速度。比如,朴素贝叶斯允许我们每次仅使用一次训练项,而其他算法,比如SVM,一下子要把所有的训练集都传给它们训练。这样我们的朴素贝叶斯是可以不断的更新的。
朴素贝叶斯还有一个优势是,对于学习状况的解释也是相对比较简单的。每个特征的概率值都会被保存起来,因此我们可以随时查看找到最合适的特征来区分邮件垃圾与否。
不过,朴素贝叶斯也是有缺陷的,就比如它无法处理特征组合带来的变化。就是我前面提到的,有的词单个出现的时候是有用的,而组合出现的时候往往暗示着这是垃圾邮件,这个时候朴素贝叶斯就很难办。
好了。这就是朴素贝叶斯网络的简单的介绍,你们,看明白了吗?















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









