






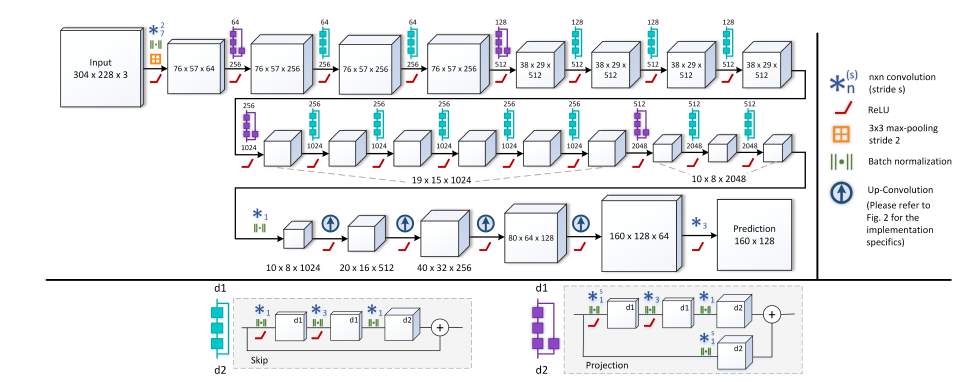
这篇就是上文采用的那个encoder-deenconder结构。介绍中说不需要任何后处理,比如CRF,实力嘲讽用了CRF还慌称端到端的渣渣。前面的网络采用residual 网络。loss是Huber loss。单目去做深度是一个非常神奇的东西,一直想不明白,可是文中的说从视觉色彩中强行读出深度信息这句话宽慰了我瑟瑟发抖的内心。MRF,CRF这些可以做吧。。
网络的收缩明明是方便计算,计算快,该文说是可以接受更大的接受域,因此可以捕捉更多的全局信息,是不是洒?
是不是所有的这类网络输出像素值都是输入的一半?我大flownet也是如此啊~~
收缩部分采用alexnet,VGG16,因为权重容易拟合,OK,很现实。
AlexNet的接受域是151×151像素,而VGG16的接受域像素则是276×276。看来对于网络的输入分辨率还是很有说法的。
ResNet和skip层配合使用将多个卷积合并,每个卷积后面还带着一个batch normalization,你告诉我ResNet有什么好的?可能好处是层数虽然很多,但是不会面临梯度消失或者网络退化(什么叫做网络退化?degradation)。另外一个好处就是更大的接受域(看来这个不错哎~)ResNet-50可以达到483×483大小的接受域(看来这个网络对于输入分辨率还是蛮敏感的~)使用residual 反卷积可以缩小权重,不然太耗内存了(深有体会!),同时也可以达到高性能。所以residual值得一试~!
网络分为两块,第一块是ResNet-50,第二块是上池化和反卷积层。总之,得到最终的结果。
Up-Projection Block
反池化是提升图片的分辨率。这部分有四块,每个2×2核的反池化跟在5×5卷积后面,作为反卷积(???唬我呢),只有四块,五块性能没提高,反而耗内存。
就是通过简单的up-convolution和up-sample组合成一些res-bocks。
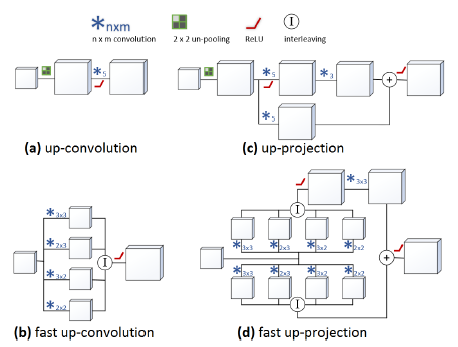
up-convolution和up-projection。图a,标准的up-convolution。图b,更快的up-convolution。c,本文up-projection块,后面接着residual logic。图d比c更快的版本。
可以发现图c的up-projection就是在up-convolution后面加上一个3×3的卷积,同时再加上一个从低质量分辨率特征映射至最终结果的projection连接。一般这种连接up-convolution都是5×5大小的。这种projection结构比up-convolution更加高级一点因为里面有一个projection连接的思想(flownet笑而不语,这种结构一定是最好的,这里的projection有一种concat中的deconv+conv的想法,只不过那个的conv是前面的,而这个可能deconv和conv比较近,这么近很可能失效~不知结果如何),这些块串起来使得特征映射尺寸越来越大。
Fast Up-convolution。本文还有一个贡献是将up-convolution更加的有效,减少训练时间。
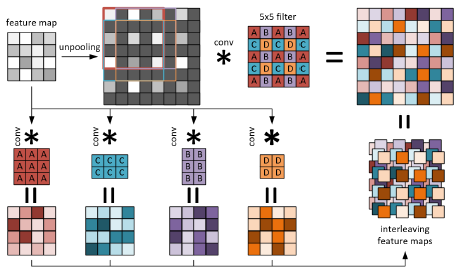
Fast Up-Convolution
就是flownet当中的反卷积为deconvolution,这个卷积相当于是转置卷积,而这篇论文中采用的是up-convolution。前文也说了,有了up-pooling,这就造成了75%的地方都是0,这样卷积跟放大的特征层进行卷积的话会有很多地方都是无效计算,跟0计算有什么意义呢~因此,将卷积分块,分成四部分,分别计算。然后再聚合,这就节省了计算时间。(私以为,还是deconvolution好一点~up-convolution不太好)这也就解释了图2中的c和d。为什么有四个形状奇特的卷积核出现。
Loss Function
一般都是L2loss,而本文采用berHu作为损失函数,就是在值在C范围内为|X|,L1范数,超过C时就是L2损失。在C处有一个一阶差分的跳变。BerHu对两种损失都有了一种平衡。大残差的时候使用L2项,同时,对于小残差梯度,L1效果比L2要好。
实验
首先,github上面作者没有提供训练代码。其次,测试代码有两种,一种matlab的,还有一种tensorflow的。我跑的是tensorflow的。
结果呢,不光速度奇慢无比,而且效果很渣。话不多说,上图,测试图片是电脑win7里面自带的图片

















 2888
2888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









