







完整项目代码:https://github.com/SPECTRELWF/pytorch-cnn-study
ResNet网络结构
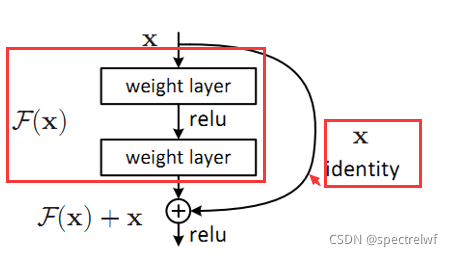
ResNet是何恺明大神在CVPR2016的工作,也拿到了当年的最佳论文。是为了解决深层网络的梯度消失的问题,引入了残差块连接。
论文地址:https://arxiv.org/pdf/1512.03385.pdf
其实我自己刚开始看这篇文章的时候不是很明白,有很多细节并不能很清楚,比如怎么去实现shortcut,每个阶段的输出到下一阶段时候的特征通道并不一致,在这里推荐大神李沐在哔哩哔哩的讲解,讲解得非常牛逼。
ResNet34的网络结构图:
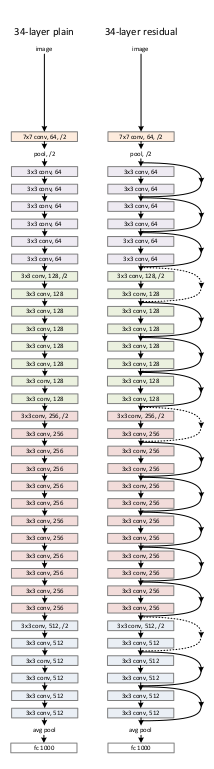
图是来自论文中的,Pytorch中可以很方便的使用自带的model模块实现ResNet,但是有些细节是看不明白的,还是得自己去实现才能了解。
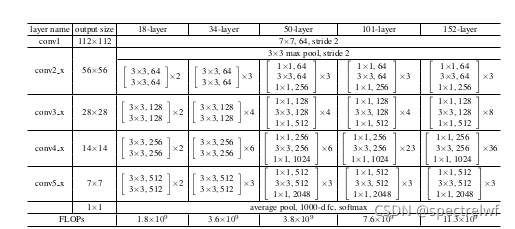
这是不同的ResNet的具体细节,本代码完全按照上面的细节来搭建的。
可以使用Pytorch中的torchvision模块的方法去初始化一个网络,查看一下网络结构,照着实现。代码如下:
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/11/5 下午3:55
import torch
import torchvision
net = torchvision.models.resnet34()
print(net)
会输出一个标准的网络信息,我在复现这些基本的backbone的时候喜欢这么做,直接看着代码敲可能会少一些思考和对细节的理解,得到的结果如下:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
Process finished with exit code 0
其实只能得到具体每个块和每层的具体参数,怎么去实现还是的自己去思考,可能我太菜了,搞了一早上。
数据集描述
数据集使用的网上一个公开的汽车数据集,包含十个类别的汽车。


包含大巴,面包车等一些类别。需要数据集的私聊我发你百度链接。
网络结构
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/11/16 上午10:40
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, in_channels,out_channels,stride=(1,1),downsample=None):
super(BasicBlock, self).__init__()
self.Block = nn.Sequential(
nn.Conv2d(in_channels, out_channels,kernel_size=3,stride=stride,padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_channels),
)
self.downsample = downsample
def forward(self,x):
out = self.Block(x)
if self.downsample is not None:
residual = self.downsample(x)
else:
residual = x
out += residual
return out
class ResNet34(nn.Module):
def __init__(self,num_classes=1000):
super(ResNet34, self).__init__()
self.head = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
self.layer1 = self.make_layer(64,64,3)
self.layer2 = self.make_layer(64,128,4,strides=2)
self.layer3 = self.make_layer(128,256,6,strides=2)
self.layer4 = self.make_layer(256,512,3,strides=2)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(512,256)
self.fc2 = nn.Linear(256,num_classes)
def make_layer(self,in_channels,out_channels,block_num,strides=1):
downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1,stride=strides,bias=False),
nn.BatchNorm2d(out_channels),
)
layer = []
layer.append(BasicBlock(in_channels,out_channels,strides,downsample))
for i in range(1,block_num):
layer.append(BasicBlock(out_channels,out_channels))
return nn.Sequential(* layer)
def forward(self,x):
x = self.head(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = x.view(x.size(0),-1)
x = self.fc1(x)
x = self.fc2(x)
return x
train
使用Adam优化器来训练的网络
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/11/5 下午4:37
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import transforms as transforms
import torch.optim as optim
from dataload.car_dataload import CAR_DATASET
from resnet34 import ResNet34
import torch.nn as nn
from utils import plot_curve
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
epochs = 200
batch_size = 32
lr = 0.001
transform = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
])
train_dataset = CAR_DATASET(r'dataset/train', transform=transform)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
)
model = ResNet34(10).to(device)
opt = optim.Adam(model.parameters(),lr=lr,betas=(0.9,0.999))
cri = nn.CrossEntropyLoss()
train_loss = []
for epoch in range(epochs):
sum_loss = 0
for batch_idx, (x, y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
pred = model(x)
opt.zero_grad()
loss = cri(pred, y)
loss.backward()
opt.step()
train_loss.append(loss.item())
print('[epoch : %d ,batch : %d ,loss : %.3f]' %(epoch,batch_idx,loss.item()))
torch.save(model.state_dict(), 'model/model.pth')
plot_curve(train_loss)
但是在测试集上也没有特别好,也就是0.8这个样子的正确率。














 2170
2170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









