







依据《动手学深度学习》课程理解并复现多层感知机的代码
一、多层感知机简介
多层感知机(Multilayer Perceptron, MLP)是一种前馈人工神经网络模型,它由多个层级组成,每个层级包含多个神经元。MLP 最基本的形式包括一个输入层、一个或多个隐藏层以及一个输出层。每层中的神经元与下一层的所有神经元完全连接,形成一种“全连接”的网络结构。这种结构使得MLP能够学习输入数据与输出之间的复杂非线性关系。
主要组成部分
(1)输入层:接收原始输入数据。每个神经元代表输入数据的一个特征。
(2)隐藏层:位于输入层和输出层之间的一层或多层。这些层不直接与外部世界交互,因此称为“隐藏”层。每个隐藏层可以有任意数量的神经元,这些神经元负责提取输入数据的特征,并进行非线性变换。
(3)输出层:产生网络的最终输出。输出层的神经元数量取决于具体的应用场景,例如,在分类任务中,输出层的神经元数量通常等于类别数;在回归任务中,输出层可能只有一个神经元。
- 用沐神的两页ppt来简述多层感知机的概念
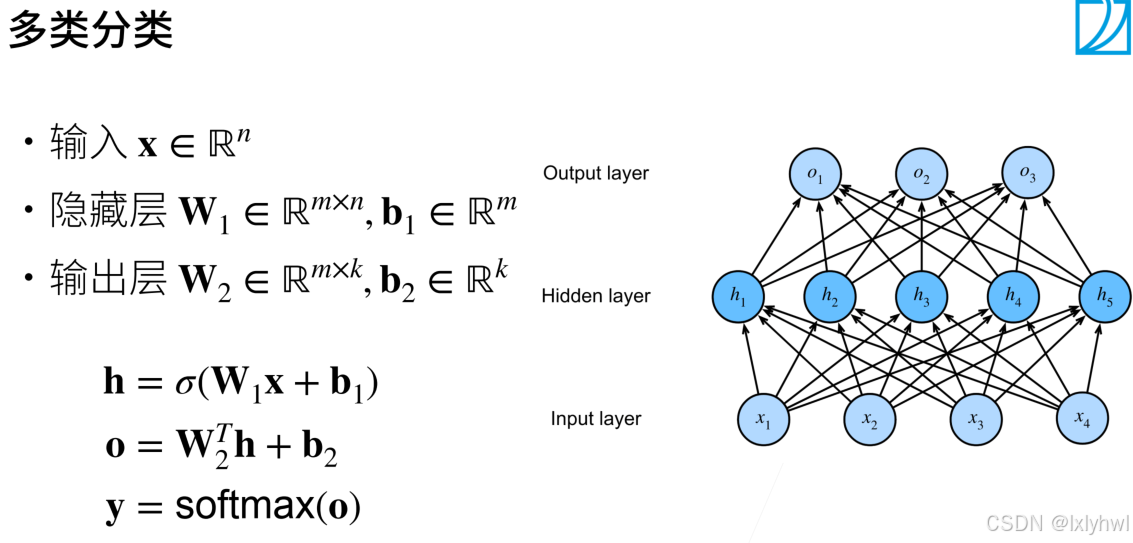
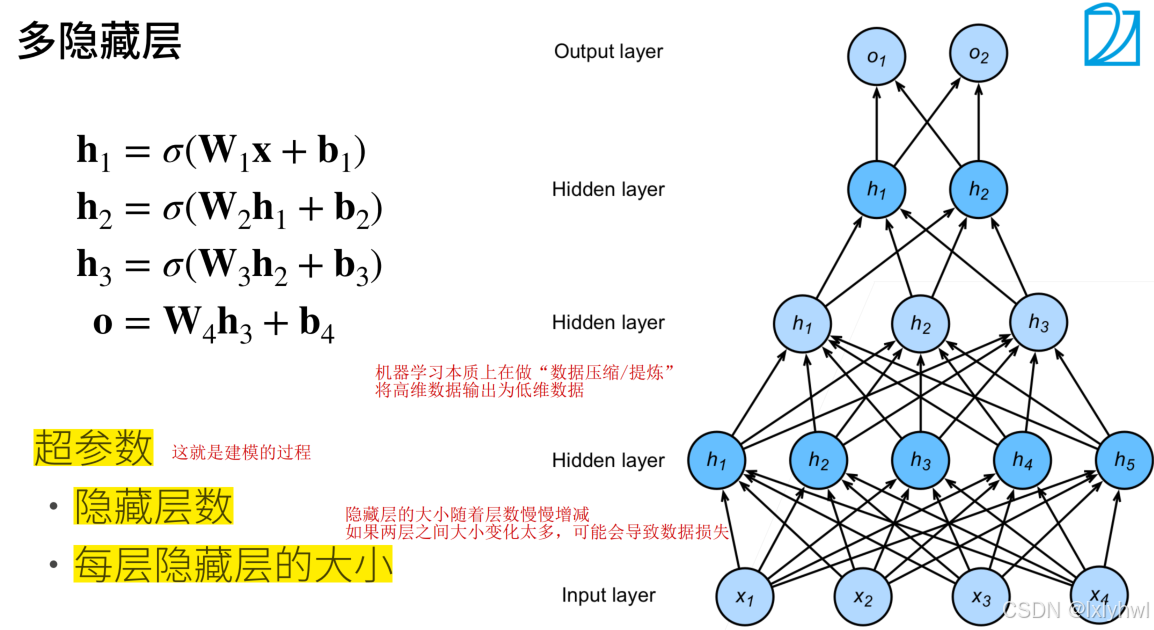
二、多类分类问题MLP实例
- 直接上代码
从part8-线性规划学习到的大体框架而言:
(0)数据筛选:直接采用“torchvision.datasets.FashionMNIST”数据集
(1)构建模型:nn.Sequential模型由Flatten层输入,经由两个全连接层输出,输入层(向量长度=784),隐藏层(向量长度=256),输出层(向量长度=10)【784是图像(28x28)的像素展平成1维,10为图像分类数】
(2)构建损失函数:nn.CrossEntropyLoss(reduction=‘none’),采用交叉熵作为损失函数
(3)设置超参数:batch_size、lr、num_epochs
(4) 迭代优化:SGD
import torch
from torch import nn
from d2l import torch as d2l
num_works = 0
'''
nn.Flatten() - 这个层的作用是将输入数据展平成一维向量。通常用于图像数据从多维(如28x28像素的图像)转换为一维(如784个元素的向量)。
整个模型通过nn.Sequential容器串联起来,按照定义的顺序执行每一层的操作。
当输入数据流经这个模型时,首先会被展平,然后传递给第一个全连接层,接着经过ReLU激活函数,最后再通过第二个全连接层产生最终的输出。
'''
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.1, 10
# 交叉熵作为损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# SGD作为优化求解算法
trainer = torch.optim.SGD(net.parameters(), lr=lr)
# 这里设置训练集和测试集的迭代器,用于取数据
train_iter, test_iter = d2l.load_data_fashion_mnist(num_works, batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.predict_ch3(net, test_iter)
# 模型更大了,模型精度更高,损失相比softmax下降了
- 准确率和损失函数值的统计结果
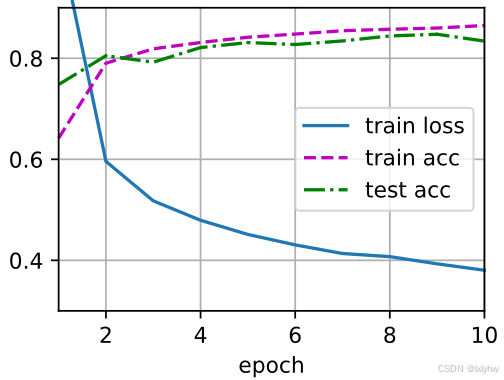
【🌟这里可以看出,对比softmax回归损失有明显下降,得益于模型更大了,模型精度更高】 - 模型预测结果

【❗ps:train_ch3函数中训练过程的学习后续细看后补充】
三、‘train_ch3’函数缺失问题解决
- 在运行part0-10多层感知机的代码时,出现如下报错
module 'd2l.torch' has no attribute 'train_ch3'
于是跳转到d2l包torch.py中,搜索发现确实不存在train_ch3函数。
- 上网搜寻后定位问题为:
沐神所用的d2l(0.17.5)的包与自身安装的d2l(1.0.3)包版本不一致。

搜索到对应函数后,将其补充在torch.py文件内。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)
Defined in :numref:`sec_softmax_scratch`"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度
Defined in :numref:`sec_softmax_scratch`"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), d2l.size(y))
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater):
"""训练模型一个迭代周期(定义见第3章)
Defined in :numref:`sec_softmax_scratch`"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
def predict_ch3(net, test_iter, n=6):
"""预测标签(定义见第3章)
Defined in :numref:`sec_softmax_scratch`"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(d2l.argmax(net(X), axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
d2l.reshape(X[0:n], (n, 28, 28)), 1, n, titles=titles[0:n])
- 主要参考:
(1) m0_65252751大神的分享
(2) github上d2l旧版本源码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









