







The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games
Abstract 摘要
Proximal Policy Optimization(PPO)是一种普遍的同策略策略强化学习算法,但在多智体环境中明显比异策略学习算法被利用得少。这往往是因为人们认为在多智体系统中,PPO的样本效率明显低于异策略方法。在本研究中,我们仔细研究了PPO在合作多智体环境中的表现。我们展示了基于PPO的多智体算法在四个流行的多智体测试平台上取得了令人惊讶的强大表现:粒子世界环境、星际争霸多智体挑战(SMAC)、Google Research Football和花火(Hanabi)挑战,而且几乎没有进行超参数调整,也没有进行任何领域特定的算法修改或架构。重要的是,与竞争性的异策略方法相比,PPO通常在最终回报和样本效率方面取得了具有竞争力 或更优异的结果。最后,通过消融研究,我们分析了对PPO经验性能至关重要的实现和超参数因素,并就这些因素提出了具体的实用建议。我们的结果表明,采用这些实践时,基于简单PPO的方法可以成为合作多智体强化学习中的强大基线。
1.Introduction 介绍
近年来,强化学习(RL)和多智体强化学习(MARL)的进展在创造人工智能智能体合作解决任务方面取得了巨大进展:DeepMind的AlphaStar在《星际争霸II》中超越了专业水平[35],OpenAI Five在Dota II中击败了世界冠军[4],OpenAI通过多智体学习展示了类似人类使用工具的智能体行为的出现[2]。这些显著成功主要受到了基于策略的RL算法(如IMPALA [10]和PPO[30,4])的推动,这些算法通常与分布式训练系统结合使用,以利用大量并行性和计算资源。在上述工作中,使用了数万个CPU核心和数百个GPU来收集和训练大量训练样本。这与最近MARL领域的学术进展和文献形成了对比,后者主要集中于开发诸如MADDPG[22]和价值分解Q学习[32,27]等异策略学习框架;这些框架中的方法在各种多智体基准测试中取得了最先进的结果[36,37]。
在本研究中,我们重新审视了Proximal Policy Optimization(PPO)——一种在单智体RL中广受欢迎但在最近MARL文献中被低估的基于策略的算法 2 ^2 2——在多智体环境中的应用。我们假设PPO在多智体环境中相对较少的使用可以归因于两个相关因素:首先,人们普遍认为PPO比离策略方法的样本效率低,因此在资源受限的情况下不太有用;其次,单智体环境使用PPO常见的实现和超参数调整做法在转移到多智体环境时,通常表现不佳。
我们进行了一项全面的实证研究,以检验PPO在四个流行的合作多智体基准测试中的表现:多智体粒子世界环境(MPE)[22],星际争霸多智体挑战(SMAC)[28],Google Research Football(GRF)[19]和Hanabi挑战[3]。我们首先展示,与离策略基线相比,PPO实现了强大的任务性能和和具有竞争力的样本效率。然后,我们确定了对PPO性能特别重要的五个实现因素和超参数,并就这些配置因素提供具体建议,并解释为什么这些建议有效。
我们在本研究中的目标不是提出一种新的MARL算法,而是通过简单修改,实证证明PPO可以在各种合作多智体环境中取得强大的性能。我们还认为我们的建议将帮助从业者在使用PPO时取得具有竞争力的结果。
我们的贡献总结如下:
- 我们展示了,PPO在四个多智体合作基准测试中,无需任何领域特定的算法更改或架构,并且经过最少调整,实现了与离策略方法竞争性的最终性能。
- 我们展示了,PPO在使用与许多离策略方法相当数量的样本时取得了这些强大的结果。
- 我们确定并分析了五个实现和超参数因素,这些因素决定了PPO在这些设置中的实际性能,并就这些因素的最佳实践提出具体建议。
2 ^2 2从技术上讲,PPO采用了用于样本重复使用的异策略校正。然而,与异策略方法不同,PPO不使用回放缓冲区来训练在整个训练过程中收集的样本。
2.Related Works 相关工作
MARL算法通常处于两种框架之间:集中式学习和分散式学习。集中式方法(Claus等,1998)直接学习单一策略以产生所有智能体的联合动作。在分散式学习(Littman,1994)中,每个智能体独立优化其奖励;这些方法可以处理一般和博弈,但即使在简单的矩阵游戏中也可能遇到不稳定性(Foerster等,2017)。集中式训练和分散式执行(CTDE)算法介于这两种框架之间。过去几种CTDE方法(Lowe等,2017;Foerster等,2017)采用了actor-critic结构,并学习一个接受全局信息的集中式critic。价值分解(VD)方法是另一类CTDE算法,将联合Q函数表示为智能体的本地Q函数的函数(Sunehag等,2018;Rashid等)。
MARL算法通常处于两种框架之间:集中式学习和分散式学习。集中式方法(Claus等,1998)直接学习单一策略以产生所有智能体的联合动作。在分散式学习(Littman,1994)中,每个智能体独立优化其奖励;这些方法可以处理一般和博弈,但即使在简单的矩阵游戏中也可能遇到不稳定性(Foerster等,2017)。集中式训练和分散式执行(CTDE)算法介于这两种框架之间。过去几种CTDE方法(Lowe等,2017;Foerster等,2017)采用了actor-critic结构,并学习一个接受全局信息的集中式critic。价值分解(VD)方法是另一类CTDE算法,将联合Q函数表示为智能体的本地Q函数的函数(Sunehag等,2018;Rashid等,2018;Son,2019),并在流行的MARL基准测试中取得了最先进的结果(Wang等,2021a;Wang等,2021b)。
在单一智能体连续控制任务中(Duan等,2016),异策略方法的进展,如SAC(Haarnoja等,2018)导致一个共识,即尽管它们早期取得了成功,但策略梯度(PG)算法如PPO的样本效率低于异策略方法。类似的结论也在多智能体领域得出:Papoudakis等(2021)报告,多智能体PG方法如COMA在粒子世界环境和星际争霸多智能体挑战中明显被MADDPG和QMix(Rashid等,2018)超越。
几个同时进行方向在研究PPO在多智能体领域的应用。DeWitt等(2020)经验性地表明,分散的、独立的PPO(IPPO)可以在几个困难的SMAC地图中取得高胜率——然而,报告的IPPO结果总体上仍不如QMix,并且该研究仅限于SMAC。Papoudakis等(2021)对各种MARL算法进行了广泛的基准测试,并指出基于PPO的方法通其他方法相比通常表现得有竞争力。相比之下,我们的工作专注于PPO,并分析其在更全面的合作多智能体基准测试中的表现。我们展示PPO在绝大多数任务中取得了强大的结果,并且确定并分析了影响其在多智能体领域表现的不同实现和超参数因素;据我们所知,过去的研究尤其是在多智能体环境中,这些因素尚未被如此广泛地研究。
我们对PPO在多智能体设置中的实现和超参数因素进行的经验分析类似于单一智能体RL中策略梯度方法的研究[34,17,9,1]。我们发现其中几个建议是有用的,并将它们纳入我们的实现中。在我们的分析中,我们专注于在现有文献中要么很少研究的因素,要么完全独特于多智能体环境的因素。
3.PPO in Multi-Agent Settings 多智能体环境下的PPO
3.1.Preliminarie前言
我们研究具有共享奖励的分散式部分可观察马尔可夫决策过程(DEC-POMDP)(Oliehoek等, 2016)。DEC-POMDP由 ⟨ S , A , O , R , P , n , γ ⟩ ⟨S,A,O,R, P, n, γ⟩ ⟨S,A,O,R,P,n,γ⟩ 定义。 S S S是状态空间。 A A A是每个智能体 i i i的共享动作空间。 o i = O ( s ; i ) o_i =O(s;i) oi=O(s;i)是智能体 i i i在全局状态 s s s下的局部观察。 P ( s ′ ∣ s , A ) P(s′|s,A) P(s′∣s,A)表示给定所有 n n n个智能体的联合动作 A = ( a 1 , . . . , a n ) A =(a1, . . . , an) A=(a1,...,an)时,从 S S S转移到 S ′ S^′ S′的转移概率。 R ( s , A ) R(s,A) R(s,A)表示共享奖励函数。 γ γ γ是折扣因子。我们采用参数共享的集中式训练-分布式执行框架,智能体策略 π θ ( a i ∣ o i ) π_θ(a_i|o_i) πθ(ai∣oi)以 θ θ θ为参数,从局部观察 o i o_i oi产生动作 a i a_i ai,并共同优化折扣累积奖励 J ( θ ) = E a t , s t [ ∑ t γ t R ( s t , a t ) ] J(θ) =\mathbb{E}_{a^t,s^t}[\sum_tγ^tR(s^t,a^t)] J(θ)=Eat,st[∑tγtR(st,at)],其中 A t = ( a 1 t , . . , a n t ) A^t = (a^t_1,.., a^t_n) At=(a1t,..,ant)是 t t t时刻的联合动作。
3.2.MAPPO and IPPO MAPPO和IPPO
我们在多智能体环境中实现的PPO与单智能体环境中的PPO结构密切相似,通过学习一个策略 π θ π_θ πθ和一个价值函数 V ϕ ( s ) V_ϕ(s) Vϕ(s);这些函数被表示为两个独立的神经网络。 V ϕ ( s ) V_ϕ(s) Vϕ(s)用于减少方差,仅在训练过程中使用;因此,它可以接受额外的全局信息作为输入,这些信息在智能体的局部观察中不存在,从而使得多智能体领域中的PPO遵循CTDE结构。为了明确起见,我们将具有集中式价值函数输入的PPO称为MAPPO(多智能体PPO),将策略和价值函数均使用局部输入的PPO称为IPPO(独立PPO)。我们仅关注合作环境,MAPPO和IPPO都在智能体共享共同奖励的环境中运行。
3.3.Implementation Details执行细节
- 参数共享:在具有同质智能体的基准环境中(即智能体具有相同的观测和动作空间),我们利用参数共享;过去的研究表明这提高了学习的效率[5,33],这也与我们的实证发现一致。在这些设置中,智能体共享策略和值函数参数。关于使用参数共享设置和为每个智能体学习单独参数的比较可见于附录C.2。我们指出,在所有基准中智能体都是同质的,除了MPEs中的Comm设置。
- 常见实施做法:我们还采用了在实施PPO中常见的做法,包括广义优势估计(GAE,Generalized Advantage Estimation)[29],带有优势归一化和值剪切。有关超参数搜索设置、训练细节和实施细节的完整描述可见于附录C。
4.Main Results主要结果
4.1.Testbeds, Baselines, and Common Experimental Setup 测试平台、基线和通用实验设置
测试环境: 我们在四个合作基准测试环境上评估了MAPPO和IPPO的性能——多智能体粒子世界环境(MPE)、星际争霸多智能体挑战(SMAC)、花火挑战和谷歌研究足球(GRF),并将这些方法的性能与在每个基准测试中取得最先进结果的流行异策略算法进行比较。每个测试环境的详细描述可以在附录B中找到。
基线: 在每个测试环境中,将MAPPO和IPPO与一组异策略基线进行比较,具体包括:
- MPEs:QMix[27]和MADDPG[22]。
- SMAC:QMix和包括QPlex[36]、CWQMix[26]、AIQMix[18]和RODE[37]在内的SOTA方法。
- GRF:QMix[27]和包括CDS[20]和TiKick[16]在内的SOTA方法。
- Hanabi:SAD[15]和VDN[32]。
通用实验设置:这里我们简要描述了所有测试平台共同的实验设置。每个测试平台的具体设置将在第4.2-4.5节中描述。
- 超参数搜索:为了进行公平比较,我们重新实现了MADDPG和QMix,并使用网格搜索调整每种方法的超参数,例如学习率、目标网络更新率和网络架构。我们确保这个网格搜索的大小与用于调整MAPPO和IPPO的大小相当。我们还测试了各种相关的实现技巧,包括值/奖励归一化、Q-learning的硬目标和软目标网络更新,以及用于评论者/混合器网络的输入表示。
- 训练计算:实验在一台桌面计算机上进行,配备256GB RAM、一个64核CPU和一个GeForce RTX 3090 GPU,用于前向动作计算和训练更新。
实验发现:在大多数环境中,PPO达到了与离策略方法相当或更好的结果,且具有可比较的样本效率。
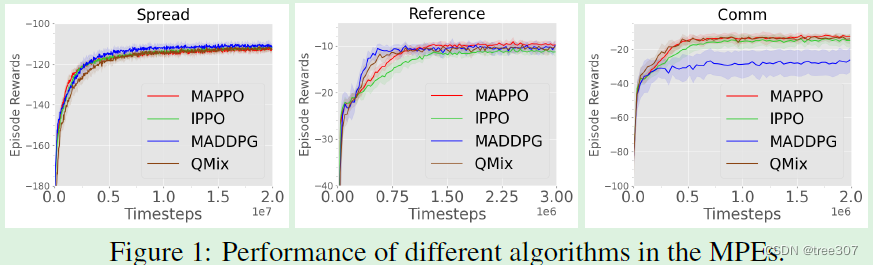
Figure 1: Performance of different algorithms in the MPEs.
4.2.MPE Testbed MPE测试平台
实验设置: 我们考虑[22]中提出的三个合作任务:物理欺骗任务(Spread),简单参考任务(Reference),以及合作通信任务(Comm)。由于MPE环境不提供全局输入,我们遵循[22]的做法,将所有智能体的局部观察连接起来形成一个全局状态,该状态被MAPPO和离策略方法使用。此外,Comm是唯一一个没有同质智能体的任务;因此,我们不为该任务使用参数共享。所有结果均取十个种子的平均值。
实验结果: 每个算法在收敛时的性能如Fig.1所示。MAPPO的性能达到了与异策略基线相媲美甚至更好的水平;我们特别发现MAPPO在所有任务上的表现与QMix非常相似,并且在Comm任务中超过了MADDPG的表现,同时使用了相近数量的环境步骤。尽管没有利用全局信息,IPPO也实现了与集中式异策略方法相似甚至更好的性能。与MAPPO相比,IPPO在几个环境中(Comm和Reference)收敛到略低的最终回报。
4.3.SMAC Testbed SMAC测试平台
实验设置:实验设置:我们评估MAPPO使用两种不同的集中式价值函数输入,标记为 A S AS AS和 F P FP FP,结合了与特定智能体无关的全局信息和特定智能体的局部信息。这些输入在第5节中有详细描述。所有异策略基线都利用不依赖智能体的全局状态和特定智能体的局部观察作为输入。具体来说,对于智能体 i i i,局部Q网络(在执行时计算动作)仅接收局部特定智能体观察 o i o_i oi作为输入,而全局混合网络接收特定智能体无关的全局状态s作为输入。对于每个随机种子,我们遵循[37]提出的评估指标:在每次训练迭代后,我们计算32个评估游戏中的胜率,并取最后十个评估胜率的中位数作为每个种子的性能。
实验结果:我们在Table 1中报告了六个种子的中位胜率,将基于PPO的方法与QMix和RODE进行了比较。完整结果推迟到附录的Table 2和Table 3中。MAPPO、IPPO和QMix在收敛或达到10M环境步骤时停止训练。RODE的结果使用[37]中的统计数据获得。我们观察到,使用 A S AS AS和 F P FP FP输入的IPPO和MAPPO在绝大多数SMAC地图中表现出色。特别是,尽管使用相同数量的样本,MAPPO和IPPO在大多数地图中的表现至少与QMix相当。比较不同的价值函数输入,我们观察到IPPO和MAPPO的表现非常相似,这些方法在除一个地图外的所有地图中表现出色。我们还观察到,同时使用相同数量的训练样本,MAPPO在14个地图中,有10个地图的表现与RODE相媲美或更好。随着样本数量的增加,MAPPO和IPPO的表现持续改善,最终在几乎每个地图中达到或超过RODE的表现。如附录D.1所示,MAPPO和IPPO在最终性能和样本效率方面与其他异策略方法(如QPlex、CWQMix和AIQMix)相媲美或更胜一筹。
总的来说,MAPPO在几乎每个SMAC地图中的有效性表明,简单的基于PPO的算法可以成为具有挑战性的多智能体强化学习问题中的强大基准。
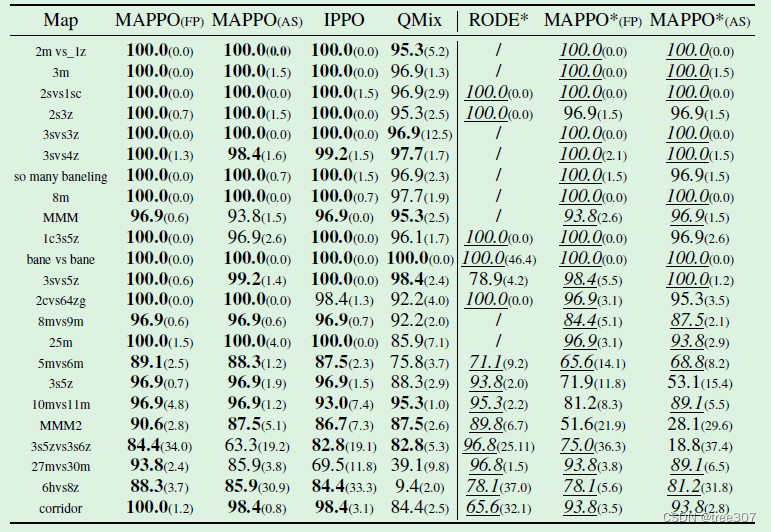
Table 1:不同方法在所有 SMAC 地图上的评估胜率中值和标准偏差,带 ""的列显示的是使用与 RODE 相同的时间步数得出的结果。MAPPO 旁边的 AS 表示智能体们对价值函数的集中输入;FP 表示类似的智能体集中输入,但去除了冗余信息。*
4.4.Google Football Testbed 谷歌足球测试平台
实验设置:我们在几个GRF学院场景中评估MAPPO,即3v.1,反击(CA)简单和困难,角球,传射(PS)和跑传射(RPS)。在这些场景中,一组智能体试图在对抗脚本对手球员的情况下进球。由于智能体的局部观察包含对环境状态的完整描述,MAPPO和IPPO之间没有区别;为了保持一致性,我们在Table 2中标记结果为“MAPPO”。我们利用GRF的密集奖励设置,其中所有智能体共享一个奖励,该奖励是个体智能体的密集奖励之和。我们计算游戏的100次模拟中的成功率,并报告过去10次评估的平均成功率,平均值基于6个种子。
实验结果:我们将MAPPO与QMix和几种SOTA方法进行比较,包括CDS,一种将环境奖励与内在奖励相结合的方法,以及TiKick,一种结合在线RL微调和大规模异预训练的算法。除TiKick外,所有方法在所有场景中进行了25M个环境步骤的训练,CA(困难)和角球场景中的方法进行了50M个环境步骤的训练。
我们通常观察到在Table 2中,尽管没有像CDS那样使用内在奖励, 但MAPPO在所有设置中实现了与其他异策略方法相媲美或更优越的性能。将MAPPO与QMix进行比较, 我们观察到MAPPO在每个场景中明显优于QMix,而且使用相同数量的训练样本。此外,尽管TiKick在一组人类专家数据上进行了预训练,但MAPPO在4/5个场景中也表现优于TiKick。
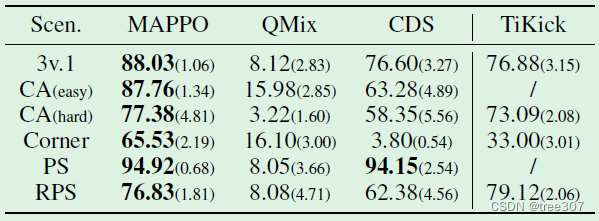
Table 2:不同方法在 GRF 情景下的平均评估成功率和标准偏差(超过六个种子)。所有与最大成功率相差 1 个标准差以内的值均以粗体标出。我们将 TiKick 与其他方法分开,因为它使用了预训练模型,因此不构成直接比较。
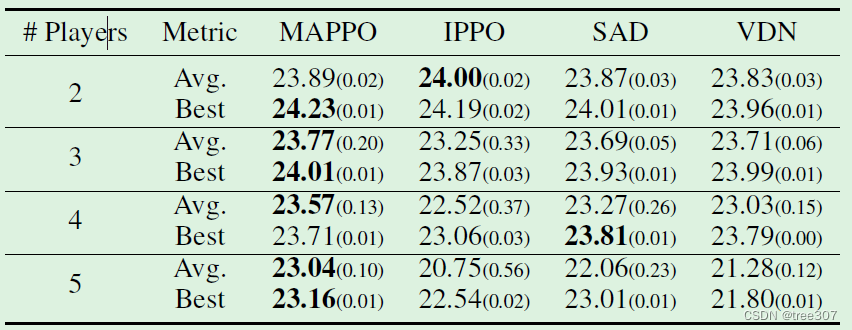
Table 3:MAPPO、IPPO、SAD 和 VDN 在Hanabi-Full上的最佳和平均评估分数。报告的是至少 3种种子的结果。
4.5.Hanabi Testbed 花火测试平台
实验设置:我们在完整规模的Hanabi游戏中评估MAPPO和IPPO在不同数量玩家(2-5名玩家)下的表现。我们将MAPPO和IPPO与强有力的异策略方法进行比较,即价值分解网络(VDN)和简化动作解码器(SAD),后者是在Hanabi中取得成功的Q学习变体。所有方法均不使用辅助任务。由于每个智能体的局部观察不包含有关该智能体自己卡牌的信息
3
^3
3,MAPPO利用一个全局状态,将智能体自己的卡牌添加到局部观察作为其值函数的输入。VDN智能体仅将局部观察作为输入。SAD智能体的输入不仅包括环境提供的局部观察,还包括过去时间步其他玩家的贪婪动作(这一点MAPPO和IPPO不使用)。由于算法限制,SAD和VDN在集中式训练期间不使用额外的全局信息。我们遵循[15],报告至少3个随机种子的平均回报以及任何种子取得的最佳分数。回报值由10k场游戏中平均计算得到。
实验结果:报告的SAD和VDN的结果来自于[15]。所有方法最多训练10B个环境步。如Table 3所示,MAPPO的最佳和平均回报能够在几乎每种情况下,产生与SAD和VDN取得的可比或更好的结果,同时利用相同数量的环境步。这表明,即使在需要根据其他玩家的行动推断其意图的环境中,如Hanabi,MAPPO也能取得强大的表现,尽管没有明确建模这种意图。
在2个智能体设置中,IPPO的表现与MAPPO相当。然而,随着智能体数量的增加,MAPPO显示出明显的改进幅度,超过了IPPO和异策略方法,这表明中心化critic输入可能至关重要。
3 ^3 3Hanabi中的局部观察包含其他智能体的卡牌和游戏状态的信息。
5.Factors Influential to PPO’s Performance PPO表现的影响因素
在本节中,我们分析了五个我们发现对MAPPO的性能特别有影响的因素:值归一化(value normalization)、值函数输入、训练数据使用、策略/值裁剪(policy/value clipping)和批量大小(batch size)。我们发现这些因素在性能方面呈现出明显的趋势;利用这些趋势,我们为每个因素提供了最佳实践建议。我们在一组适当的代表性环境中研究了每个因素。为了保持一致性,所有实验均使用MAPPO(即具有集中值函数的PPO)进行。其他结果可以在附录E中找到。
5.1.Value Normalization 值归一化

Figure 2:数值规范化对 MAPPO 在 SMAC 和 MPE 中性能的影响
通过MAPPO的训练过程,由于实现回报的差异,价值目标可以发生大幅变化,导致价值学习的不稳定性。为了缓解这一问题,我们通过使用价值目标的平均估计值和标准差来标准化价值函数的目标。具体而言,在价值学习过程中,价值网络回归到标准化的目标值。在计算 GAE 时,我们使用运行平均值对数值网络的输出进行去规范化处理,以便对数值输出进行适当缩放。我们发现,使用价值标准化不会影响训练,并且通常显著提高MAPPO的最终性能。
实验分析: 我们研究了在MPE spread环境和几个SMAC环境中价值标准化的影响,结果显示在Fig.2 中。在Spread环境中,其中的episode回报从低于-200到0,价值标准化对于强大的性能至关重要。价值标准化还对几个SMAC地图产生积极影响,无论是通过提高最终性能还是通过减少训练方差。
建议1: 利用价值标准化来稳定价值学习。
5.2.Input Representation to Value Function 价值函数的输入表示

Figure 3:不同价值函数输入表示法的效果(如Figure 4 所示)
许多智能体CTDE PG算法与完全分散的PG方法之间的根本区别在于价值网络的输入。因此,值输入的表示成为整体算法的重要方面。使用集中价值函数的假设是,观察完整的全局状态可以使值学习更容易。准确的值函数通过方差减少进一步改善策略学习。
过去的研究通常使用两种形式的全局状态。[22]将所有本地智能体观察串联,形成本地观察串联(concatenation of local observations,CL)全局状态。虽然它可以在大多数环境中使用,但CL状态的维度随着智能体数量的增加而增长,并且可能会忽略所有智能体未观察到的重要全局信息;这些因素可能使值学习变得困难。其他研究,特别是研究SMAC的作品,利用一个环境提供的全局状态(Environment-Provided global state,EP),其中包含有关环境状态的一般全局信息[11]。然而,EP状态通常包含所有智能体共同的信息,可能会忽略重要的本地智能体特定信息。这在SMAC中是真实的,如Fig.4所示。
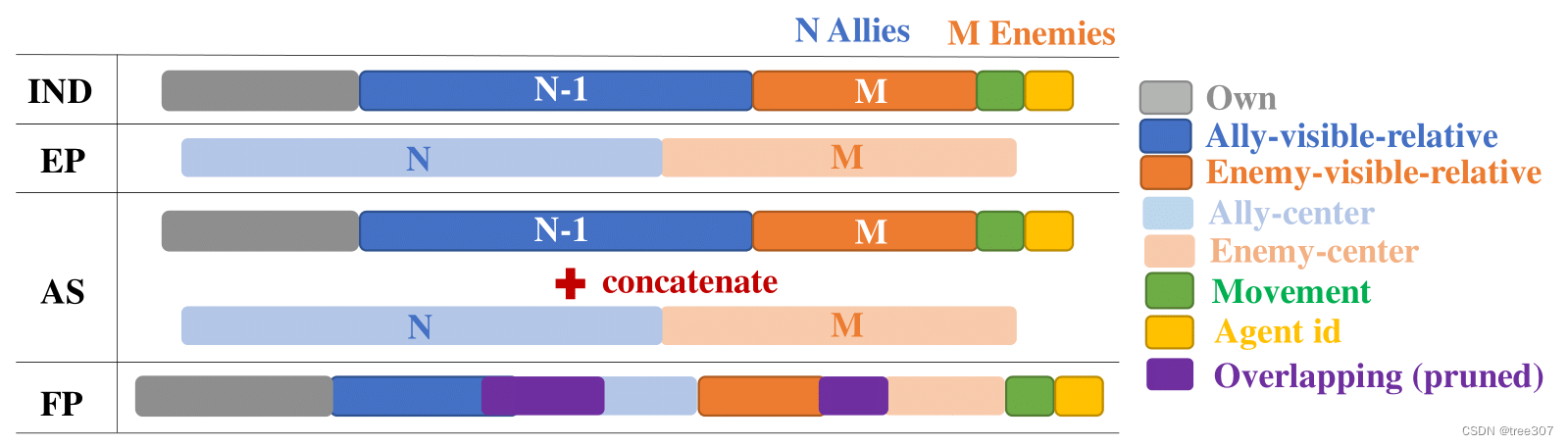
Fig.4:不同的价值函数输入与每个状态所包含的示例特征(SMAC特定)。IND指的是使用分散输入(智能体们的本地观察结果),EP 指的是环境提供的全局状态,AS是连接EP和IND的智能体全局状态,FP是从AS中剪除重叠特征的智能体全局状态。EP省略了智能体们的ID和可用行动等重要本地数据。
为了解决CL和EP状态的弱点,我们允许值函数利用全局和本地信息,通过形成一个智能体特定全局状态(Agent-Specific Global State, AS),为智能体 i i i创建一个全局状态,通过串联EP状态和智能体 i i i的本地观察 o i o_i oi。这为值函数提供了对环境状态更全面的描述。然而,如果 o i o_i oi和EP全局状态之间存在信息重叠,则AS状态将具有冗余信息,这会不必要地增加值函数的输入维度。如Fig.4所示,在SMAC中就是这种情况。为了检验这种增加维度的影响,我们创建了一个特征修剪的智能体特定全局状态(Featured-Pruned Agent-Specific Global State,FP),通过删除AS状态中的重复特征。
实验分析: 我们研究了这些不同值函数输入在SMAC中的影响,这是唯一考虑提供不同选项的集中值函数输入的基准。Fig.3中的结果表明,使用CL状态,在具有许多智能体的地图中,比其他全局状态高得多的维度是无效的。相比之下,使用EP全局状态可以实现更强的性能,但在更困难的地图中表现明显不佳,可能是由于缺乏重要的本地信息。AS和FP全局状态都取得了良好的性能,其中FP状态在几个地图上优于AS状态。这表明状态维度、智能体特定特征和全局信息在形成有效全局状态时都很重要。我们注意到,使用FP状态需要了解EP状态和智能体本地观察之间的哪些特征重叠,并评估使用此状态的MAPPO以证明限制值函数输入维度可以进一步提高性能。
建议2: 在可用时,将本地、智能体特定特征和全局特征都包含在值函数输入中。还要检查这些特征是否不必要地增加了输入维度。
5.3.Training Data Usage 训练数据使用情况
PPO的一个重要特点是利用重要性采样进行异策略修正,从而实现样本重用。[14]建议将收集的大批样本分成mini-batche进行训练多个epoch。在单智能体连续控制领域,常见做法是将大批次样本分成大约32或64个mini-batche,并进行数十个epoch的训练。然而,我们发现在多智能体领域,当样本被过度重复使用时,MAPPO的性能会下降。因此,我们在简单任务中使用15个epoch、在困难任务中使用10或5个epoch。我们假设这种模式可能是多智能体强化学习中非稳态性的结果:每次更新使用更少的epoch限制了智能体策略的变化,这可能提高了策略和价值学习的稳定性。此外,与[17]的建议类似,我们发现使用更多数据来估计梯度通常会导致实际性能的提升。因此,我们将训练数据分成最多两个mini-batche,并在大多数情况下避免mini-batche处理。
实验分析: 我们研究了在SMAC地图中训练epoch对结果的影响,如Fig.5(a)所示。我们观察到当使用大量epoch进行训练时会产生不利影响:当使用15个epoch进行训练时,MAPPO始终学习到次优策略,在非常困难的MMM2和走廊地图中表现尤为糟糕。相比之下,使用5或10个epoch时,MAPPO表现良好。MAPPO的性能还对每个训练epoch的mini-batche数量非常敏感。我们考虑了三个mini-batche值:1、2、4。mini-batches为4,表示我们将训练数据分成4个mini-batche进行梯度下降。Fig.5(b)显示,使用更多mini-batche会对MAPPO的性能产生负面影响:当使用4个mini-batche时,MAPPO无法解决任何选定的地图,而使用1个mini-batche在22/23个地图上表现最佳。如Fig.6所示,在MPE任务中也可以得出类似的结论。在Reference和Comm这两个最简单的MPE任务中,所有选择的epoch和mini-batche值都导致相同的最终性能,甚至使用15个训练epoch会导致更快的收敛。然而,在更困难的Spread任务中,我们观察到与SMAC类似的趋势:更少的epoch和不分割mini-batche会产生最佳结果。
建议3: 在困难环境中最多使用10个训练epoch,在简单环境中使用15个训练epoch。此外,避免将数据分割成mini-batch。

(a)不同训练epoch的效果

(b)不同mini-batch的效果
Figure 5: Epoch和mini-batch number对MAPPO在SMAC中表现的影响
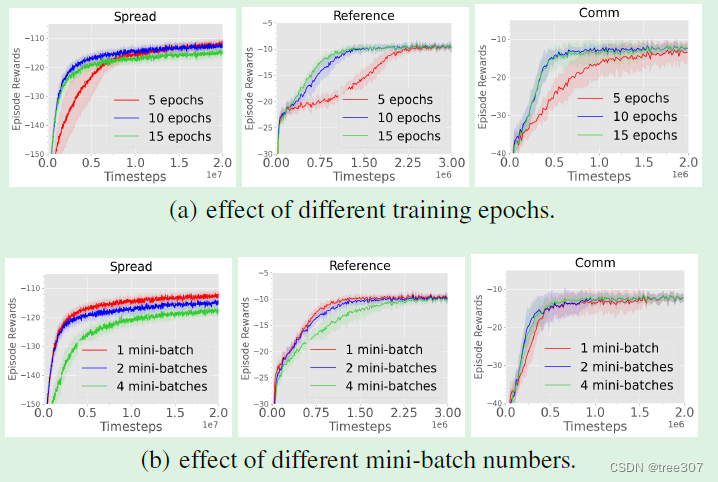
Figure 6:在 MPE 中,epoch 和 mini-batch number 对 MAPPO 性能的影响
5.4.PPO Clipping PPO裁剪

Fig.7: 不同剪切强度对SMAC中MAPPO性能的影响
PPO的另一个核心特征是使用修剪的重要性比率和价值损失,以防止策略和价值函数在迭代之间发生剧烈变化。修剪强度由 ϵ ϵ ϵ超参数控制:较大的 ϵ ϵ ϵ值允许对策略和价值函数进行更大的更新。与训练epoch的数量类似,我们假设策略和价值的修剪可以限制非稳态性,这是由于智能体的策略在训练过程中发生变化。对于较小 ϵ ϵ ϵ,智能体的策略在每次更新时可能变化较少,我们认为这有助于提高整体学习稳定性,但可能以学习速度为代价。在单一智能体设置中,常见的 ϵ ϵ ϵ值为0.2 [9, 1]。
实验分析: 我们研究了由超参数 ϵ ϵ ϵ控制的PPO修剪强度在SMAC中的影响(Fig.7)。注意到 ϵ ϵ ϵ对策略和价值修剪都是相同的。我们一般认为,对于小的 ϵ ϵ ϵ值,如0.05,MAPPO在几个地图上的学习速度变慢,包括像MMM2和3s5zvs.3s6z这样的困难地图。然而,当使用 ϵ = 0.05 ϵ=0.05 ϵ=0.05时,最终表现始终很高,并且表现更加稳定,如训练曲线中较小的标准偏差所示。我们还观察到,较大的 ϵ ϵ ϵ值,如0.2、0.3和0.5,允许在每个梯度步骤中对策略和价值函数进行更大的更新,通常会导致次优性能。
建议4: 为了获得最佳的PPO性能,请保持修剪比率 ϵ ϵ ϵ在0.2以下;在这个范围内,调整 ϵ ϵ ϵ作为训练稳定性和快速收敛之间的权衡。
5.5.PPO Batch Size
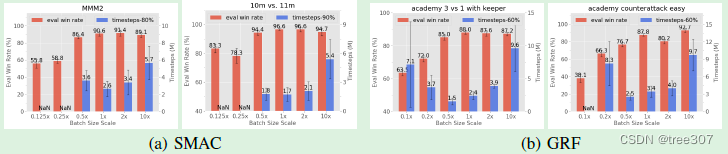
Fig.8: Batch size对MAPPO在SMAC和GRF中的性能影响。红色柱状图显示最终胜率。蓝色柱状图显示达到强胜率所需的环境步数(在SMAC中为80%或90%,在GRF中为60%),作为样本效率的衡量标准。"NaN"表示从未达到这样的胜率。x轴指定batch-size大小,作为我们主要结果中使用的batch size的倍数。需要足够大的batch size才能实现最佳的最终性能/样本效率;进一步增加batch size可能会损害样本效率
在训练更新过程中,PPO抽样一批同策略轨迹,用于估计策略和值函数目标的梯度。由于在我们的训练中固定了mini-batch的数量(参见第5.3节),更大的batch通常会导致更准确的梯度估计,从而产生更好的值函数和策略更新。然而,batch的累积受到可用计算资源和内存量的限制:收集大量轨迹需要高效的并行性,并且batch需要存储在GPU内存中。因此,使用不必要的大batch-size可能会在所需计算资源和样本效率方面造成浪费。
实验分析: Fig.8展示了不同batch size对最终任务性能和样本效率的影响。我们观察到,在几乎所有情况下,存在一个关键的batch-size设置——当batch-size低于这个临界点时,MAPPO的最终性能较差,进一步调整batch size可以产生最佳的最终性能和样本效率。然而,继续增加batch size可能不会导致改善最终性能,实际上可能会降低样本效率。
建议5: 利用大batch size来实现MAPPO的最佳任务性能,然后调整batch size以优化样本效率。
Conclusion 结论
这项工作表明,PPO(Proximal Policy Optimization,一种基于策略梯度的同策略RL算法)在各种合作多智体挑战中取得了强大的最终回报和样本效率,与最先进方法可媲美,这表明适当配置的PPO可以作为合作多智体强化学习任务的比较基准。我们还确定并分析了五个关键的实现和超参数因素,这些因素对PPO在这些设置中的性能具有影响。基于我们的实证研究,我们就这些因素提出了具体建议的最佳实践。这项工作存在一些限制,指向未来研究的方向。首先,我们的基准环境都使用离散动作空间,都是合作的,在绝大多数情况下包含同质智体。在未来的工作中,我们的目标是在更广泛的领域上测试PPO,如竞争性游戏和具有连续动作空间和异质智体的多智体强化学习问题。此外,我们的工作主要是经验性质的,没有直接分析PPO的理论基础。我们相信我们建议的经验分析可以作为进一步分析PPO在多智体强化学习中性质的起点。
附录A:MAPPO细节

Algorithm 1 Recurrent-MAPPO
MAPPO训练两个独立的神经网络:一个带有参数 θ θ θ的actor网络,以及一个带有参数 ϕ ϕ ϕ的值函数网络(称为critic)。如果智能体是同质的,这些网络可以在所有智能体之间共享,但每个智能体也可以拥有自己的actor和critic网络。为了符号方便起见,我们在这里假设所有智能体共享critic和actor网络。具体来说,critic网络 V ϕ V_ϕ Vϕ,执行以下映射: S → R S→\mathbb{R} S→R。全局状态可以是特定于智能体的,也可以是与智能体无关的。
actor网络 π θ π_θ πθ,将智能体观测o t ( a ) ^{(a)}_t t(a)映射到离散动作空间中动作的分类分布,或者映射到多元高斯分布的均值和标准差向量,在连续动作空间中从中采样一个动作。
actor网络被训练以最大化目标
L
(
θ
)
=
[
1
B
n
∑
i
=
1
B
∑
k
=
1
n
min
(
r
θ
,
i
(
k
)
A
i
(
k
)
,
c
l
i
p
(
r
θ
,
i
(
k
)
,
1
−
ϵ
,
1
+
ϵ
)
A
i
(
k
)
)
]
+
σ
1
B
n
∑
i
=
1
B
∑
k
=
1
n
S
[
π
θ
(
o
i
(
k
)
)
)
]
L(θ)=[\frac{1}{Bn}\sum^B_{i=1}\sum^n_{k=1}\min(r^{(k)}_{θ,i}A^{(k)}_i,clip(r^{(k)}_{θ,i} ,1−ϵ,1+ϵ)A^{(k)}_i)]+σ\frac{1}{B_n}\sum^{B}_{i=1}\sum^n_{k=1}S[\pi_\theta(o_i^{(k)}))]
L(θ)=[Bn1∑i=1B∑k=1nmin(rθ,i(k)Ai(k),clip(rθ,i(k),1−ϵ,1+ϵ)Ai(k))]+σBn1∑i=1B∑k=1nS[πθ(oi(k)))]
其中
r
θ
,
i
(
k
)
=
π
θ
(
a
i
(
k
)
∣
o
i
(
k
)
π
o
l
d
(
a
i
(
k
)
∣
o
i
(
k
)
r^{(k)}_{θ,i}=\frac{π_θ(a^{(k)}_i|o^{(k)}_i}{π_{old}(a^{(k)}_i|o^{(k)}_i}
rθ,i(k)=πold(ai(k)∣oi(k)πθ(ai(k)∣oi(k)。
A
i
(
k
)
A^{(k)}_i
Ai(k)使用GAE方法计算,
S
S
S是策略熵,
σ
σ
σ是熵系数超参数。
评论网络被训练以最小化损失函数
L
(
ϕ
)
=
1
B
n
∑
i
=
1
B
∑
k
=
1
n
(
max
[
(
V
ϕ
(
s
i
(
k
)
)
−
R
^
i
)
2
,
(
c
l
i
p
(
V
ϕ
(
s
i
(
k
)
)
,
V
ϕ
o
l
d
(
s
i
(
k
)
−
ε
,
V
ϕ
o
l
d
(
s
i
(
k
)
+
ε
)
−
R
^
i
)
2
]
L(ϕ)=\frac{1}{Bn}\sum^B_{i=1}\sum^n_{k=1}(\max[(V_ϕ(s^{(k)}_i)−\hat{R}_i)^2, (clip(V_ϕ(s^{(k)}_i), V_{ϕ_{old}}(s^{(k)}_i−ε,V_{ϕ_{old}}(s^{(k)}_i+ε)−\hat{R}i)^2]
L(ϕ)=Bn1∑i=1B∑k=1n(max[(Vϕ(si(k))−R^i)2,(clip(Vϕ(si(k)),Vϕold(si(k)−ε,Vϕold(si(k)+ε)−R^i)2]
其中
R
^
i
\hat{R}_i
R^i是折扣奖励。
在上述损失函数中, B B B指batch size, n n n指智能体数量。如果critic和actor网络是卷积神经网络(RNN),则损失函数还会随时间累加, 并通过时间反向传播(Backpropagation Through Time,BPTT)训练网络。循环-MAPPO的伪代码如Alg.1所示。
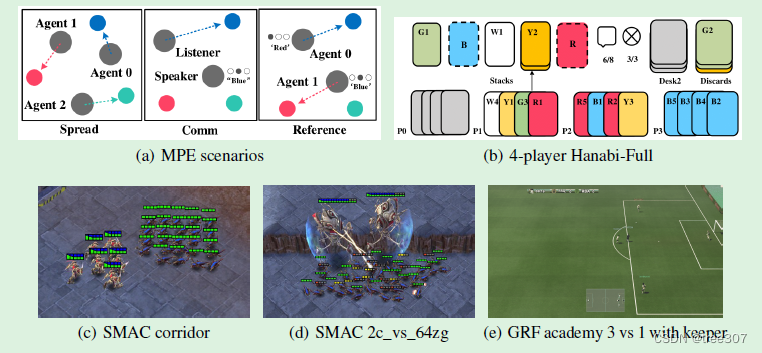
Figure 9:任务可视化。(a) MPE 领域。Spread(左):智能体们需要覆盖所有地标,并且对导航到的地标没有颜色偏好;Comm(中):聆听者需要根据说话者的指令导航到特定地标;Reference(右):两个智能体只知道对方的目标地标,需要进行交流以确保两个智能体都移动到所需目标。(b) 花牌领域: 4 人花式游戏–图片来自(Bard 等人,2020 年)。© SMAC 领域中的走廊地图。(d) SMAC 域中的 2c vs. 64zg 地图。(e) GRF 域中的学院 3 vs 1 与守门员场景
附录B:Testing domains
Multi-agent Particle-World Environment(MPE)是在(Lowe等人,2017)中引入的。MPE包括在一个二维世界中的各种多智能体游戏,其中小粒子在一个正方形盒子内导航。我们考虑原始集合中的三个完全合作任务,如Fig.9(a)所示:Spread、Comm和Reference。请注意,由于speaker-listener中的两个智能体具有不同的观察和行动空间,这是本文中唯一一个我们不共享参数而为每个智能体单独训练策略的设置。
StarCraftII Micromanagement Challenge(SMAC)任务是在(Rashid等人,2019)中引入的。在这些任务
中,分散的智能体必须合作击败各种场景中的对抗性机器人,智能体数量范围广泛(从2到27)。我们使用全局游戏状态来训练我们的集中式评论家或Q函数。Fig.9©和9(d)展示了两个星际争霸II环境示例。
如第5.2节所述,我们利用特定于智能体的全局状态作为全局状态的输入。这个特定于智能体的全局状态通过添加相关的特定于智能体的特征来扩充SMAC环境提供的原始全局状态。
具体来说,SMAC的原始全局状态包含有关所有智能体和敌人的信息————这包括每个智能体/敌人到地图中心的距离、每个智能体/敌人的生命值、每个智能体/敌人的护盾状态以及每个智能体的武器冷却状态等信息。然而,与每个智能体的局部观察相比,全局状态不包含特定于智能体的信息,包括智能体ID、智能体移动选项、智能体攻击选项、与盟友/敌人的相对距离。请注意,局部观察仅包含智能体视野内的盟友/敌人的信息。为了解决环境提供的全局状态中缺乏关键局部信息的问题,我们创建了几个其他特定于每个智能体的全局输入,并结合局部和全局特征。第一个,我们称之为特定于智能体(agent-specific,AS),使用环境提供的全局状态和智能体 i i i的观察 o i o_i oi的串联作为MAPPO的评论者在智能体i的梯度更新期间的全局输入。然而,由于全局状态和局部智能体观察具有重叠特征,我们另外创建了一个特征修剪的全局状态(FP),它去除了AS全局状态中的重叠特征。
Hanabi是一种基于回合的纸牌游戏,在(Bard等人,2020)中作为多智能体强化学习挑战引入,每个智能体观察其他玩家的牌,但不观察自己的牌。游戏的可视化如Fig.9(b)所示。游戏的目标是向其他玩家发送信息令牌,并合作采取行动以尽可能按升序堆叠尽可能多的牌以收集积分。
花火的回合制性质在计算智能体在其回合中的奖励时提出了挑战。我们将前向累积奖励作为一个回合奖励 R i R_i Ri;具体地,如果有4名玩家,玩家0、1、2、3在时间步 k , k + 1 , k + 2 , k + 3 k,k+1,k+2,k+3 k,k+1,k+2,k+3分别执行它们的行动,导致奖励 r k ( 0 ) , r k + 1 ( 1 ) , r k + 2 ( 2 ) , r k + 3 ( 3 ) r^{(0)}_k,r^{(1)}_{k+1},r^{(2)}_{k+2}, r^{(3)}_{k+3} rk(0),rk+1(1),rk+2(2),rk+3(3),那么分配给玩家 0 0 0的奖励将是 R 0 = r k ( 0 ) + r k + 1 ( 1 ) + r k + 2 ( 2 ) + r k + 3 ( 3 ) R_0=r^{(0)}_k+r^{(1)}_{k+1}+r^{(2)}_{k+2}+r^{(3)}_{k+3} R0=rk(0)+rk+1(1)+rk+2(2)+rk+3(3),类似地,分配给玩家1的奖励将是 R 1 = r k + 1 ( 1 ) + r k + 2 ( 2 ) + r k + 3 ( 3 ) + r k + 4 ( 0 ) R_1=r^{(1)}_{k+1}+r^{(2)}_{k+2}+r^{(3)}_{k+3}+r^{(0)}_{k+4} R1=rk+1(1)+rk+2(2)+rk+3(3)+rk+4(0)。这里 r t i r^i_t rti表示在时间步 t t t时智能体 i i i执行移动时收到的奖励。
Google Research Football (GRF),在[19]中进行了介绍,它包含一系列合作多智能体挑战,其中一组智能体与各种足球场景中的一组机器人对战。在我们考虑的场景中,智能体的目标是在对方团队得分。Fig.9(e)展示了示例学院场景。
智能体的局部观察包含在任何给定时间环境状态的完整描述;因此,策略和值函数都以相同的观察作为输入。在每一步,智能体分享相同的奖励 R t R_t Rt,该奖励被计算为每个智能体奖励r^{(i)}_t的总和,代表智能体 i i i取得的进展。
[1] 原论文地址:Yu C, Velu A, Vinitsky E, et al. The surprising effectiveness of ppo in cooperative multi-agent games[J]. Advances in Neural Information Processing Systems, 2022, 35: 24611-24624.
[2] gpt学术翻译:学术版GPT 网页非盈利版

















 8952
8952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









