







【动手学Paddle2.0系列】模型参数EMA理论详解与实战
什么是EMA?
滑动平均(exponential moving average),或者叫做指数加权平均(exponentially weighted moving average),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大,如下图公式所示。在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。
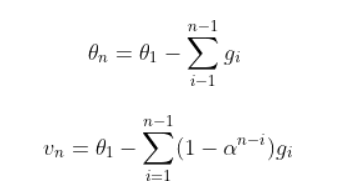
为什么EMA在测试过程中使用通常能提升模型表现?
滑动平均可以使模型在测试数据上更健壮(robust)。“采用随机梯度下降算法训练神经网络时,使用滑动平均在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。”
对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,以得到 weights 下一步更新的值,进而求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。
一个基本的假设是,对于模型最后的收敛阶段,模型的权重会在全局最优点抖动。所以,取最后收敛过程中模型权重的平均值更能代表模型的最终训练结果,并且能为模型带来更高的鲁棒性。
代码实战
代码实现主要参考了PaddleDetection中的实现,具体如下所示。
#! /usr/bin/env python
# coding=utf-8
# ================================================================
#
# Author : PaddleDetection
# Created date:
# Description :
#
# ================================================================
import paddle
import numpy as np
class ExponentialMovingAverage():
def __init__(self, model, decay, thres_steps=True):
self._model = model
self._decay = decay
self._thres_steps = thres_steps
self._shadow = {}
self._backup = {}
def register(self):
self._update_step = 0
for name, param in self._model.named_parameters():
if param.stop_gradient is False: # 只记录可训练参数。bn层的均值、方差的stop_gradient默认是True,所以不会记录bn层的均值、方差。
self._shadow[name] = param.numpy().copy()
def update(self):
for name, param in self._model.named_parameters():
if param.stop_gradient is False:
assert name in self._shadow
new_val = np.array(param.numpy().copy())
old_val = np.array(self._shadow[name])
decay = min(self._decay, (1 + self._update_step) / (10 + self._update_step)) if self._thres_steps else self._decay
new_average = decay * old_val + (1 - decay) * new_val
self._shadow[name] = new_average
self._update_step += 1
return decay
def apply(self):
for name, param in self._model.named_parameters():
if param.stop_gradient is False:
assert name in self._shadow
self._backup[name] = np.array(param.numpy().copy())
param.set_value(np.array(self._shadow[name]))
def restore(self):
for name, param in self._model.named_parameters():
if param.stop_gradient is False:
assert name in self._backup
param.set_value(self._backup[name])
self._backup = {}
from paddle.vision.transforms import Compose, Normalize
from paddle.vision.datasets import MNIST
import paddle
# 数据预处理,这里用到了随机调整亮度、对比度和饱和度
transform = Compose([Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')])
# 数据加载,在训练集上应用数据预处理的操作
train_dataset = MNIST(mode='train', transform=transform)
test_dataset = MNIST(mode='test', transform=transform)
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=True)
import paddle
from paddle.vision.models import LeNet
import paddle.nn as nn
mnist = LeNet()
# train
import paddle.nn.functional as F
# 初始化
ema = ExponentialMovingAverage(mnist, 0.9998)
ema.register()
mnist.train()
epochs = 2
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=mnist.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
# print(y_data)
predicts = mnist(x_data)
loss = F.cross_entropy(predicts, y_data)
# 计算损失
acc = paddle.metric.accuracy(predicts, y_data, k=2)
loss.backward()
if batch_id % 5 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
optim.step()
optim.clear_grad()
# 训练过程中,更新完参数后,同步update shadow weights
ema.update()
# eval前,apply shadow weights;eval之后,恢复原来模型的参数
ema.apply()
save_path = 'test.pdparams'
paddle.save(mnist.state_dict(), save_path)
# eval
# ema.apply()
模型参数加载&验证
import paddle
from paddle.vision.models import LeNet
import paddle.nn as nn
mnist = LeNet()
load_layer_state_dict = paddle.load("test.pdparams")
mnist.set_state_dict(load_layer_state_dict)
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = data[1]
predicts = mnist(x_data)
# loss = F.cross_entropy(predicts, y_data)
# # 计算损失
# acc = paddle.metric.accuracy(predicts, y_data, k=2)
# if batch_id % 5 == 0:
oss_entropy(predicts, y_data)
# # 计算损失
# acc = paddle.metric.accuracy(predicts, y_data, k=2)
# if batch_id % 5 == 0:
# print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
predicts
Tensor(shape=[16, 10], dtype=float32, place=CPUPlace, stop_gradient=False,
[[ 1.31200826 , -0.36774674 , 4.37932062 , 0.00965829 , -1.46909487 , -5.13704014 , -9.87518501 , 16.42917633, -2.59316278 , 1.83172619 ],
[-3.84247041 , 11.97241974, -1.83453345 , -1.73480690 , 4.06165266 , -2.41107368 , -2.00936532 , 1.58228016 , 1.67354298 , -1.67772675 ],
[-0.58078408 , 1.38440561 , -0.46936649 , -3.87814379 , 11.18445683, -4.61712074 , 1.53198421 , 1.66331410 , 1.16634071 , -2.48539686 ],
[-4.00482655 , -5.43965578 , 3.76318884 , 20.94420815, -13.01803017, 4.67226696 , -9.61773586 , -3.18090224 , 3.64317369 , 4.45366573 ],
[-2.89683557 , -8.32001781 , -3.53441167 , 6.61288548 , -5.09777689 , 11.61921501, -0.78740460 , -8.45889187 , 1.15145135 , 2.75297976 ],
[-0.08368183 , 0.52320749 , -2.74406052 , 1.03198934 , -0.08064339 , 0.64234287 , 7.65128422 , -3.68186855 , 0.57307494 , -5.71482420 ],
[-7.76337004 , -0.14408615 , 1.04461837 , 2.83495045 , 1.48663294 , 0.00297991 , -13.45738506, 17.95549774, 1.62916148 , 5.19289970 ],
[-3.11190176 , 2.69219923 , 5.25174809 , 4.14212036 , -7.23213243 , -3.79451680 , -10.12667561, 12.15778446, 1.59992754 , 3.36512566 ],
[-3.59189677 , 0.94435877 , 0.59473652 , -2.05147886 , 14.65558052, -5.37477016 , -4.38802290 , 2.57847238 , 1.14274454 , 1.98140085 ],
[ 11.68829823, -9.20073605 , 2.16024303 , -5.53739309 , -3.71042919 , -5.97104692 , 3.19806242 , -4.66739607 , 2.90434480 , 0.92396927 ],
[-0.81350207 , 11.90717220, 1.93753338 , -1.80106664 , 3.88573980 , -5.18650436 , -2.16082954 , 1.80646157 , 1.86005557 , -4.86944628 ],
[ 13.47606182, -4.06046295 , 2.73547006 , -7.02661467 , -4.27261400 , -4.14475536 , 4.02677488 , -4.15399408 , 1.41958189 , -4.03261709 ],
[ 4.57753849 , -7.90497160 , 11.30145741, 4.01428556 , -1.22134769 , -1.98790145 , -2.08669853 , 1.69436896 , -1.63476396 , -2.85063457 ],
[ 3.35857224 , -1.59903800 , 11.46317577, 1.71020269 , -0.42371336 , -6.91723776 , -2.58867574 , -0.31241670 , 2.05572820 , -2.18729663 ],
[ 0.07857184 , -10.00708199, -7.58345461 , 3.97073555 , -11.86467743, 17.72941208, 5.46220350 , -10.81384754, 3.89810276 , 2.70089579 ],
[ 3.43599534 , -5.76815844 , 3.46011448 , -1.96301985 , -4.01397657 , -0.01274985 , 10.33502197, -7.41869926 , 2.30596447 , -7.75322533 ]])
总结
本次教程为大家讲解了飞桨2.0框架下如何实现EMA。EMA是一种非常实用的涨点技巧,它不会给模型带来参数的增加,但是能够提高模型的鲁棒性。本教程中未设置对比实验,其重点在于EMA的实现,并且此方法的有效性已经在很多论文中得到了验证,故不再需要进行重复工作。

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









