








文章地址:LAVT
Github:https://github.com/yz93/LAVT-RIS
motivation:
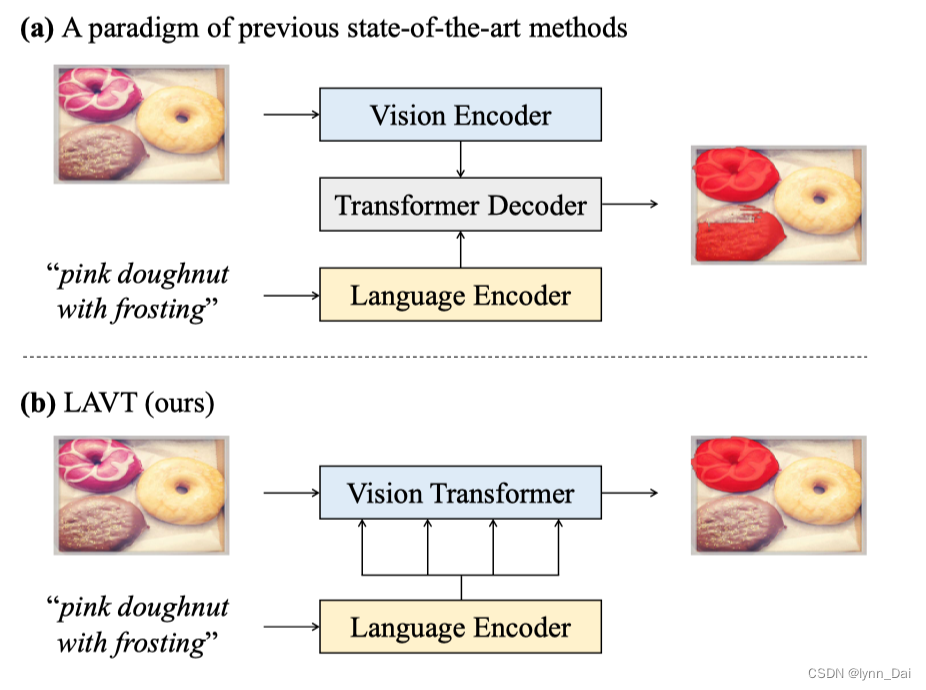
在传统的范式中,Transformer在提高RIS方面的潜力还远远没有得到充分的探索。具体来说,跨模态交互只发生在特征编码之后。而跨模态解码器只负责对齐视觉和语言特征。以前的方法不能有效地利用编码器中的Transformer层来挖掘有用的多模态上下文。
idea:
为了解决这些问题,提出利用视觉编码器网络在视觉编码期间联合嵌入语言和视觉特征。
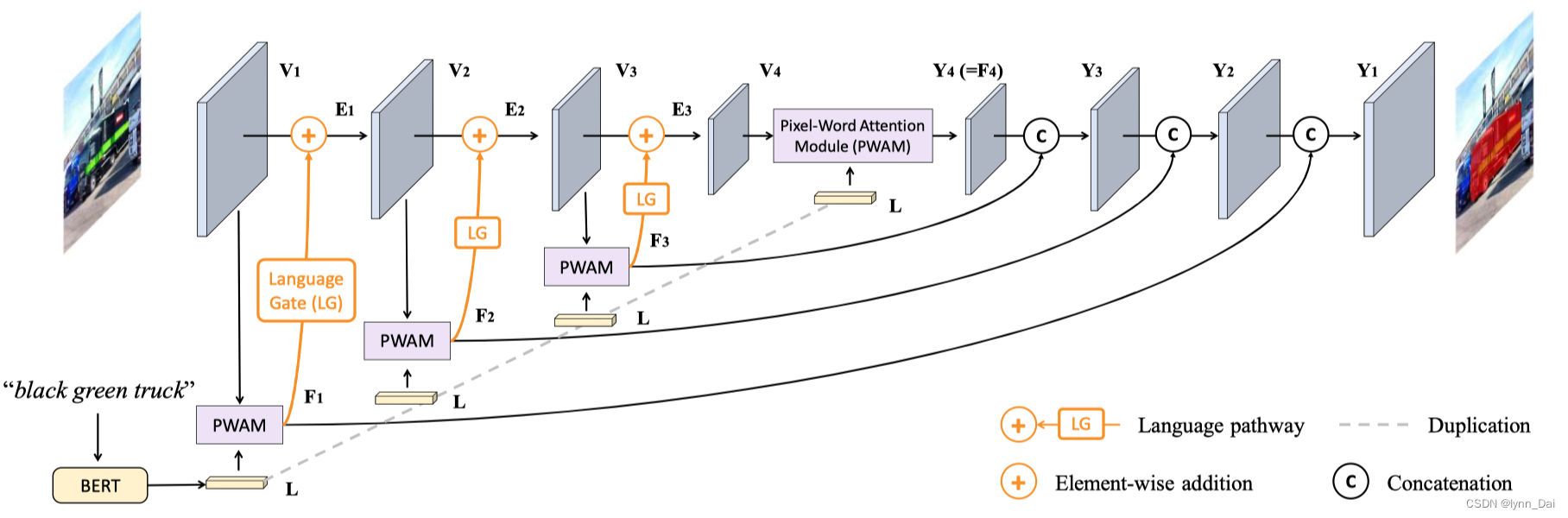
提出了一种语言感知视觉转换器(LAVT)网络,在该网络中,视觉特征与语言特征一起编码,能够“感知”每个空间位置的相关语言上下文。LAVT充分利用了vision Transformer骨干网络中的多阶段设计,形成了一种分层语言感知的视觉编码方案。
- 通过像素-单词注意机制将语言特征密集地整合到视觉特征中,这种机制发生在网络的每个阶段。
- Transformer块,在下一个编码器阶段利用这些有益的视觉语言线索。
- 这种方法能够放弃复杂的跨模态解码器,因为提取的语言感知视觉特征可以很容易地通过一个轻量级的掩码预测器来获取准确的分割掩码。
contribution:
提出了LAVT,这是一个基于Transformer 的RIS框架,它在后特征提取步骤中执行语言感知视觉编码来代替跨模态融合。















 5003
5003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









