






Title
题目
LViT: Language Meets Vision Transformer in Medical Image Segmentatio
LViT: 语言与视觉Transformer在医学图像分割中的应用
01
文献速递介绍
医学图像分割是医学图像分析中最关键的任务之一。在临床实践中,准确的分割可以帮助医生诊断疾病,指导治疗方案的制定。然而,现有的医学图像分割模型在使用高质量标记数据方面存在挑战,这主要是由于标记数据的获取成本高昂。为了解决这一挑战,我们提出了一种新的文本增强医学图像分割模型LViT。在LViT模型中,我们采用了混合的CNN-Transformer结构,并设计了像素级注意力模块(PLAM),这样可以更好地整合文本信息,同时保留CNN从图像中提取局部特征的能力。为了解决第二个挑战,我们设计了一种指数伪标签迭代机制(EPI),旨在逐步改进伪标签,并间接地利用文本信息来优化伪标签。此外,我们设计了LV(语言-视觉)损失,以直接利用文本信息来监督未标记医学图像的训练。为了验证LViT的性能,我们构建了三个多模态医学图像分割数据集,包含CT图像和X射线图像。实验结果表明,LViT在不同数据集上均取得了优异的分割性能,即使仅使用了部分训练集标签,也能获得与全监督方法相当的性能。
Abstract
摘要
Deep learning has been widely used in med**ical image segmentation and other aspects. However,the performance of existing medical image segmentationmodels has been limited by the challenge of obtainingsufficient high-quality labeled data due to the prohibitivedata annotation cost. To alleviate this limitation, we propose a new text-augmented medical image segmentationmodel LViT (Language meets Vision Transformer). In ourLViT model, medical text annotation is incorporated tocompensate for the quality deficiency in image data. In addition, the text information can guide to generate pseudolabels of improved quality in the semi-supervised learning.We also propose an Exponential Pseudo label Iterationmechanism (EPI) to help the Pixel-Level Attention Module(PLAM) preserve local image features in semi-supervisedLViT setting. In our model, LV (Language-Vision) loss isdesigned to supervise the training of unlabeled imagesusing text information directly. For evaluation, we construct three multimodal medical segmentation datasets(image + text) containing X-rays and CT images. Experimental results show that our proposed LViT has superiorsegmentation performance in both fully-supervised andsemi-supervised setting.
深度学习已被广泛应用于医学图像分割等方面。然而,现有的医学图像分割模型的性能受到获取充足高质量标记数据的挑战的限制,因为数据注释成本过高。为了缓解这一限制,我们提出了一种新的文本增强医学图像分割模型LViT(Language meets Vision Transformer)。在我们的LViT模型中,将医学文本注释纳入,以弥补图像数据质量不足的缺陷。此外,文本信息可以指导生成半监督学习中改进质量的伪标签。我们还提出了指数伪标签迭代机制(EPI),以帮助像素级注意力模块(PLAM)在半监督LViT设置中保留局部图像特征。在我们的模型中,LV(Language-Vision)损失被设计用来直接使用文本信息监督未标记图像的训练。为了评估,我们构建了三个多模态医学分割数据集(图像+文本),其中包含X射线和CT图像。实验结果表明,我们提出的LViT在全监督和半监督设置下具有优越的分割性能。
Method
方法
As shown in Figure 2, the proposed LViT model is aDouble-U structure consisting of a U-shaped CNN branchand a U-shaped Transformer branch. The CNN branch actsas the source of information input and the segmentation headof prediction output, and the ViT branch is used to mergeimage and text information, where we exploit the ability ofTransformer to process cross-modality information. After asimple vectorization of the text, the text vector is merged withthe image vector and send to the U-shaped ViT branch forprocessing. In the model inference stage, we also need to perform similar processing on text input. And we pass the fusioninformation of corresponding size back to the U-shape CNNbranch at each layer for the final segmentation prediction.In addition, a Pixel-Level Attention Module (PLAM) is setat the skip connection position of the U-shape CNN branch.With PLAM, LViT is able to retain as much local featureinformation of images as possible. We also conduct ablationexperiments to demonstrate the effectiveness of each module.
如图2所示,提出的LViT模型是一个双U结构,由一个U形CNN分支和一个U形Transformer分支组成。CNN分支作为信息输入的源头和预测输出的分割头,而ViT分支用于合并图像和文本信息,我们利用Transformer处理跨模态信息的能力。在对文本进行简单的向量化后,文本向量与图像向量合并,并发送到U形ViT分支进行处理。在模型推断阶段,我们还需要对文本输入进行类似的处理。然后,我们将相应尺寸的融合信息返回到每个层级的U形CNN分支,用于最终的分割预测。此外,在U形CNN分支的跳跃连接位置设置了像素级注意力模块(PLAM)。通过PLAM,LViT能够尽可能保留图像的局部特征信息。我们还进行了消融实验,以证明每个模块的有效性。
Conclusion
结论
In this paper, we propose a new vision-language medicalimage segmentation model LViT, which leverages medicaltext annotation to compensate for the quality deficiency inimage data and guide to generate pseudo labels of improvedquality in the semi-supervised learning. Multimodal medical segmentation datasets (image + text) are constructed toevaluate the performance of LViT, and experimental resultsshow that our model has superior segmentation performancein both fully-supervised and semi-supervised settings. In addition, we present an example application on the diagnosis andtreatment of early-stage esophageal cancer to demonstrate how
在本文中,我们提出了一种新的视觉-语言医学图像分割模型 LViT,利用医学文本注释来补偿图像数据质量不足,并指导生成改进质量的伪标签以用于半监督学习。构建了多模态医学分割数据集(图像 + 文本)来评估 LViT 的性能,实验结果表明我们的模型在完全监督和半监督设置下均具有优越的分割性能。此外,我们提出了一个早期食管癌诊断和治疗的示例应用,以展示我们的方法可以如何进行。
Figure
图
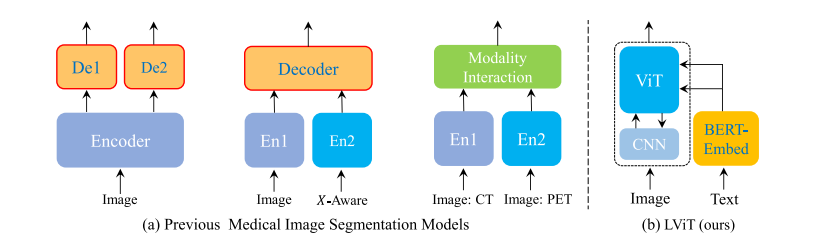
Fig. 1. Comparison of current medical image segmentation models and our proposed LViT model.
图1. 当前医学图像分割模型与我们提出的LViT模型的比较。

Fig. 2. Illustration of (a) the proposed LViT model, and (b) the Pixel-Level Attention Module (PLAM). The proposed LViT model is a Double-U structure formed by combining a U-shape CNN branch with a U-shaped ViT branch.
图2. (a) 提出的LViT模型的示意图,以及 (b) 像素级注意力模块(PLAM)。提出的LViT模型是通过将一个U形CNN分支与一个U形ViT分支相结合形成的双U结构。

Fig. 3. Illustration of (a) Exponential Pseudo-label Iteration mechanism(EPI), and (b) LV (Language-Vision) Loss.
图3. (a) 指数伪标签迭代机制(EPI)的示意图,以及 (b) LV(语言-视觉)损失的示意图。

Fig. 4. Qualitative results on the QaTa-COV19 and the MosMedData+ datasets.
图4. QaTa-COV19 和 MosMedData+ 数据集上的定性结果。

Fig. 5. Saliency map for interpretability study of different approaches on the QaTa-COV19 dataset. The language input of the first row is “Bilateral pulmonary infection, two infected areas, lower left lung and lower right lung”. The language input of the second row is “Unilateral pulmonary infection, one infected area, middle left lung”.
图5. 对QaTa-COV19数据集上不同方法进行可解释性研究的显著性图。第一行的语言输入是“双侧肺感染,两个感染区域,左下肺和右下肺”。第二行的语言输入是“单侧肺感染,一个感染区域,左中肺”。

Fig. 6. Saliency map for interpretability study of different layers of LViT on the QaTa-COV19 dataset. The language input of the first row is “Bilateral pulmonary infection, three infected areas, all left lung and upper lower right lung”. The language input of the second row is “Bilateral pulmonary infection, two infected areas, all left lung and lower right lung”.
图6. 在QaTa-COV19数据集上对LViT不同层级进行可解释性研究的显著性图。第一行的语言输入是“双侧肺感染,三个感染区域,全部左肺和上下右肺”。第二行的语言输入是“双侧肺感染,两个感染区域,全部左肺和下右肺”。
Table
表

TABLE I the specific division of different datasets
表格 I 不同数据集的具体划分
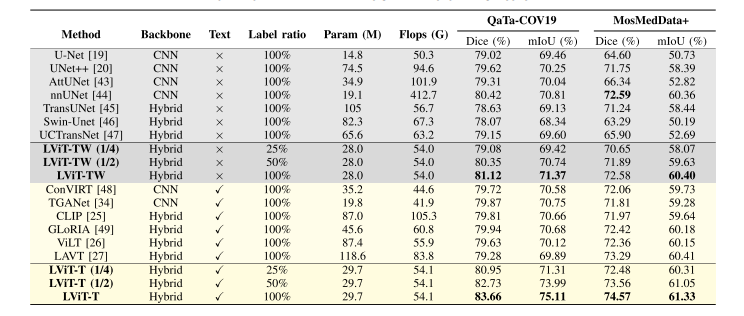
TABLE II performance comparison between our method (lvit) and other state-of-the-art methods on the qata-cov19 and mosmeddata+ datasets. the “w” in lvit-tw refers to without the text information. the “hybrid” means cnn-transformer structure
表格 II 在 QaTa-COV19 和 MosMedData+ 数据集上,我们方法(LViT)与其他最新方法的性能比较。LViT-TW 中的 “W” 表示没有文本信息。“混合” 表示CNN-Transformer结构。

TABLE III ablation study on the effectiveness of supervised components: downvit, upvit, plam, text & semi-supervised components: epi, text, loss lv on the qata-cov19 dataset
表格 III 在 QaTa-COV19 数据集上对监督组件(DownViT、UpViT、PLAM、TEXT和LOSS LV)和半监督组件(EPI、TEXT、LOSS LV)的有效性进行消融研究。

TABLE IV ablation study on different model sizes: lvit-t, lvit-s, lvit-b. the dice and iou are in 'mean±std' format. the std stands for standard deviation in three times runs
表格 IV 不同模型尺寸的消融研究:LViT-T、LViT-S、LViT-B。Dice和IoU以 '均值±标准差' 格式表示。标准差代表三次运行的标准偏差。

TABLE Vablation study on text encoder and text embedding layer
表格 V 文本编码器和文本嵌入层的消融研究

TABLE VI ablation study with lvit-t on different hyper-parameters: batch size and learning rate
表格 VI 在不同超参数(批量大小和学习率)下使用 LViT-T 的消融研究

TABLE VII ablation study on semi-supervision with lvit-t and other methods on the qata-cov19 dataset
表格 VII 在 QaTa-COV19 数据集上,使用 LViT-T 和其他方法进行半监督消融研究

TABLE VIII table viii performance comparison between our method (lvit)and other methods on the eso-ct dataset
表格 VIII在 ESO-CT 数据集上,我们方法(LViT)与其他方法的性能比较















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









