






**进程调度概念**
内存中保存了对进程的唯一描述,并通过若干结构与其他进程链接起来。调度器面对的情形就是这样的,不同任务(进程)之间共享CPU,创造出并行的错觉,由此延申出进程调度策略和上下文切换。
**前提**
内核必须提供一种方法,在各个进程之间尽可能的共享CPU时间,而同时又必须考虑不同任务的优先级。由此延申出来各种不同的进程调度策略。
**调度原理**
调度器的一般原理是,按所能分配的计算能力,向系统中的每个进程提供最大的公正性。或者从另一个角度来说,它试图确保没有进程被亏待。这听起来不错,但就CPU时间而论,公平与否意味着什么呢?考虑一台理想计算机,可以并行运行任意数目的进程。如果系统上有N个进程,那么每个进程得到总计算能力的1/N,所有的进程在物理上真实地并行执行。假如一个进程需要10分钟完成其工作。如果5个这样的进程在理想CPU上同时运行,每个会得到计算能力的20%,这意味着每个进程需要运行50分钟,而不是10分钟。但所有的5个进程都会刚好在该时间段之后结束其工作,没有哪个进程在此段时间内处于不活动状态!
在真正的硬件上这显然是无法实现的。如果系统只有一个CPU,至多可以同时运行一个进程。只能通过在各个进程之间高频率来回切换,来实现多任务。对用户来说,由于其思维比转换频率慢得多,切换造成了并行执行的错觉,但实际上不存在并行执行。虽然多CPU系统能改善这种情况并完美地并行执行少量进程,但情况总是CPU数目比要运行的进程数目少,这样上述问题又出现了。如果通过轮流运行各个进程来模拟多任务,那么当前运行的进程,其待遇显然好于哪些等待调度器选择的进程,即等待的进程受到了不公平的对待。不公平的程度正比于等待时间。
每次调用调度器时,它会挑选具有最高等待时间的进程,把CPU提供给该进程。如果经常发生这种情况,那么进程的不公平待遇不会累积,不公平会均匀分布到系统中的所有进程。
下图说明了调度器如何记录哪个进程已经等待了多长时间。 由于可运行进程是排队的,该结构称之为就绪队列。
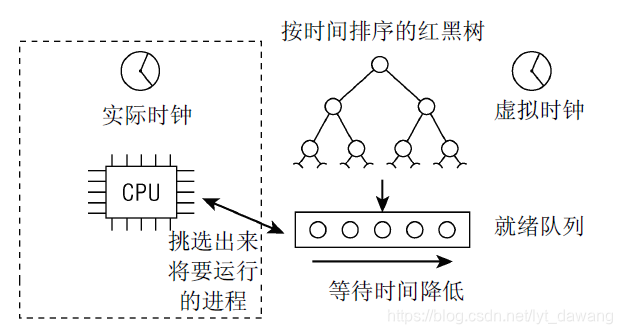
所有的可运行进程都按时间在一个红黑树中排序,所谓时间即其等待时间。等待CPU时间最长的进程是最左侧的项,调度器下一次会考虑该进程。等待时间稍短的进程在该树上从左至右排序。
**调度器**
**1、核心调度器**
调度器的实现基于两个函数:周期性调度器函数和主调度器函数。这些函数根据现有进程的优先级分配CPU时间。这也是为什么整个方法称之为优先调度的原因。
b.周期性调度器函数
周期性调度器在scheduler_tick中实现,如果系统正在活动中,内核会按照频率HZ自动调用该函数。该函数主要有两个任务如下:
(1) 更新相关统计量:管理内核中与整个系统和各个进程的调度相关的统计量。其间执行的主要操作是对各种计数器加1。
(2) 激活负责当前进程的调度类的周期性调度方法。
源码如下,内核版本4.12
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}
更新统计量函数:update_rq_clock()/calc_global_load_tick()
<update_rq_clock>
void update_rq_clock(struct rq *rq)
{
s64 delta;
lockdep_assert_held(&rq->lock);
if (rq->clock_update_flags & RQCF_ACT_SKIP)
return;
#ifdef CONFIG_SCHED_DEBUG
if (sched_feat(WARN_DOUBLE_CLOCK))
SCHED_WARN_ON(rq->clock_update_flags & RQCF_UPDATED);
rq->clock_update_flags |= RQCF_UPDATED;
#endif
delta = sched_clock_cpu(cpu_of(rq)) - rq->clock;
if (delta < 0)
return;
rq->clock += delta;
update_rq_clock_task(rq, delta);
}
<calc_global_load_tick函数>
/*
* Called from scheduler_tick() to periodically update this CPU's
* active count.
*/
void calc_global_load_tick(struct rq *this_rq)
{
long delta;
if (time_before(jiffies, this_rq->calc_load_update))
return;
delta = calc_load_fold_active(this_rq, 0);
if (delta)
atomic_long_add(delta, &calc_load_tasks);
this_rq->calc_load_update += LOAD_FREQ;
}
主调度器函数
在内核中的许多地方,如果要将CPU分配给与当前活动进程不同的另一个进程,都会直接调用主调度器函数(schedule)。
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
主调度器负责将CPU的使用权从一个进程切换到另一个进程。周期性调度器只是定时更新调度相关的统计信息。cfs队列实际上是用红黑树组织的,rt队列是用链表组织的。
2、调度类及运行队列
a.调度类
为方便添加新的调度策略,Linux内核抽象一个调度类sched_class,目前为止实现5种调度类:

b.运行队列
每个处理器有一个运行队列,结构体是rq,定义的全局变量如下:
#define CREATE_TRACE_POINTS
#include <trace/events/sched.h>
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
rq是描述就绪队列,其设计是为每一个CPU就绪队列,本地进程在本地队列上排序:
3、调度进程
主动调度进程的函数是schedule() ,它会把主要工作委托给__schedule()去处理。源码如下
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPT=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPT is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
local_irq_disable();
rcu_note_context_switch(preempt);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
rq_lock(rq, &rf);
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
prev->on_rq = 0;
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev);
if (to_wakeup)
try_to_wake_up_local(to_wakeup, &rf);
}
}
switch_count = &prev->nvcsw;
}
next = pick_next_task(rq, prev, &rf);//调用pick_next_task()以选择下一个进程
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);//调用context_switch()以切换进程
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unlock_irq(rq, &rf);
}
balance_callback(rq);
}
函数__shcedule的主要处理过程如下:
调用pick_next_task()以选择下一个进程。
调用context_switch()以切换进程。
代码如下:
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can
* call that function directly, but only if the @prev task wasn't of a
* higher scheduling class, because otherwise those loose the
* opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
again:
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
/* The idle class should always have a runnable task: */
BUG();
}
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) {
next->active_mm = oldmm;
mmgrab(oldmm);
enter_lazy_tlb(oldmm, next);
} else
switch_mm_irqs_off(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
rq_unpin_lock(rq, rf);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
a、切换用户虚拟地址空间,ARM64架构使用默认的switch_mm_irqs_off,其内核源码定义如下:
/* Architectures that care about IRQ state in switch_mm can override this. */
#ifndef switch_mm_irqs_off
# define switch_mm_irqs_off switch_mm
#endif
switch_mm函数内核源码处理如下:
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
if (prev != next)
__switch_mm(next);
/*
* Update the saved TTBR0_EL1 of the scheduled-in task as the previous
* value may have not been initialised yet (activate_mm caller) or the
* ASID has changed since the last run (following the context switch
* of another thread of the same process). Avoid setting the reserved
* TTBR0_EL1 to swapper_pg_dir (init_mm; e.g. via idle_task_exit).
*/
if (next != &init_mm)
update_saved_ttbr0(tsk, next);
}
static inline void __switch_mm(struct mm_struct *next)
{
unsigned int cpu = smp_processor_id();
/*
* init_mm.pgd does not contain any user mappings and it is always
* active for kernel addresses in TTBR1. Just set the reserved TTBR0.
*/
if (next == &init_mm) {
cpu_set_reserved_ttbr0();
return;
}
check_and_switch_context(next, cpu);
}
b、切换寄存器,宏switch_to把这项工作委托给函数__switch_to:
#define switch_to(prev, next, last) \
do { \
ARC_FPU_PREV(prev, next); \
last = __switch_to(prev, next);\
ARC_FPU_NEXT(next); \
mb(); \
} while (0)
#endif
/*
* Thread switching.
*/
__notrace_funcgraph struct task_struct *__switch_to(struct task_struct *prev,
struct task_struct *next)
{
struct task_struct *last;
fpsimd_thread_switch(next);
tls_thread_switch(next);
hw_breakpoint_thread_switch(next);
contextidr_thread_switch(next);
entry_task_switch(next);
uao_thread_switch(next);
/*
* Complete any pending TLB or cache maintenance on this CPU in case
* the thread migrates to a different CPU.
*/
dsb(ish);
/* the actual thread switch */
last = cpu_switch_to(prev, next);
return last;
}
4、调度时机
调度进程的时间如下:
进程主动调用schedule()函数。
周期性地调度,抢占当前进程,强迫当前进程让出处理器。
唤醒进程的时候,被唤醒的进程可能抢占当前进程。
创建新进程的时候,新进程可能抢占当前进程。
a、主动调度
进程在用户模式下运行的时候,无法直接调用schedule()函数,只能通过系统调用进入内核模式,如果系统调用需要等待某个资源,如互斥锁或信号量,就会把进程的状态设置为睡眠状态,然后调用schedule()函数来调度进程。
b、周期调度
有些“地痞流氓”进程不主动让出处理器,内核只能依靠周期性的时钟中断夺回处理器的控制权,时钟中断是调度器的脉博。时钟中断处理程序检查当前进程的执行时间有没有超过限额,如果超过限额,设置需要重新调度的标志。当时钟中断处理程序准备返点处理器还给被打断的进程时,如果被打断的进程在用户模式下运行,就检查有没有设置需要重新调度的标志,如果设置了,调用schedule函数以调度进程。
**二、SMP调度**
在SMP系统中,进程调度器必须支持如下:
**需要使用每个处理器的负载尽可能均衡。
可以设置进程的处理器亲和性,即允许进程在哪些处理器上执行。
可以把进程从一个处理器迁移到另一个处理器。**
**1、进程的处理器亲和性**
设置进程的处理器亲和性,通俗就是把进程绑定到某些处理器,只允许进程在某些处理器上执行,默认情况是进程可以在所有处理器上执行。应用编程接口和使用cpuset配置具体详解分析。
**2、期限调度类的处理器负载均衡**
限期调度类的处理器负载均衡简单,调度选择下一个限期进程的时候,如果当前正在执行的进程是限期进程,将会试图从限期进程超载的处理器把限期进程搞过来。
**限期进程超载定义:**
限期运行队列至少有两个限期进程。
至少有一个限期进程绑定到多个处理器。
源码如下
static void pull_dl_task(struct rq *this_rq)
{
int this_cpu = this_rq->cpu, cpu;
struct task_struct *p;
bool resched = false;
struct rq *src_rq;
u64 dmin = LONG_MAX;
if (likely(!dl_overloaded(this_rq)))
return;
/*
* Match the barrier from dl_set_overloaded; this guarantees that if we
* see overloaded we must also see the dlo_mask bit.
*/
smp_rmb();
for_each_cpu(cpu, this_rq->rd->dlo_mask) {
if (this_cpu == cpu)
continue;
src_rq = cpu_rq(cpu);
/*
* It looks racy, abd it is! However, as in sched_rt.c,
* we are fine with this.
*/
if (this_rq->dl.dl_nr_running &&
dl_time_before(this_rq->dl.earliest_dl.curr,
src_rq->dl.earliest_dl.next))
continue;
/* Might drop this_rq->lock */
double_lock_balance(this_rq, src_rq);
/*
* If there are no more pullable tasks on the
* rq, we're done with it.
*/
if (src_rq->dl.dl_nr_running <= 1)
goto skip;
p = pick_earliest_pushable_dl_task(src_rq, this_cpu);
/*
* We found a task to be pulled if:
* - it preempts our current (if there's one),
* - it will preempt the last one we pulled (if any).
*/
if (p && dl_time_before(p->dl.deadline, dmin) &&
(!this_rq->dl.dl_nr_running ||
dl_time_before(p->dl.deadline,
this_rq->dl.earliest_dl.curr))) {
WARN_ON(p == src_rq->curr);
WARN_ON(!task_on_rq_queued(p));
/*
* Then we pull iff p has actually an earlier
* deadline than the current task of its runqueue.
*/
if (dl_time_before(p->dl.deadline,
src_rq->curr->dl.deadline))
goto skip;
resched = true;
deactivate_task(src_rq, p, 0);
set_task_cpu(p, this_cpu);
activate_task(this_rq, p, 0);
dmin = p->dl.deadline;
/* Is there any other task even earlier? */
}
skip:
double_unlock_balance(this_rq, src_rq);
}
if (resched)
resched_curr(this_rq);
}
3、实时调度类的处理器负载均衡
实时调度类的处理器负载均衡和限期调度类相似。调度器选择下一个实时进程时,如果当前处理器的实时运行队列中的进程的最高调度优先级比当前正在执行的进程的调度优先级低,将会试图从实时进程超载的处理器把可推送实时进程拉过来。
实时进程超载的定义:
实时运行队列至少有两个实时进程。
至少有一个可推送实时进程。
static void pull_rt_task(struct rq *this_rq)
{
int this_cpu = this_rq->cpu, cpu;
bool resched = false;
struct task_struct *p;
struct rq *src_rq;
if (likely(!rt_overloaded(this_rq)))
return;
/*
* Match the barrier from rt_set_overloaded; this guarantees that if we
* see overloaded we must also see the rto_mask bit.
*/
smp_rmb();
#ifdef HAVE_RT_PUSH_IPI
if (sched_feat(RT_PUSH_IPI)) {
tell_cpu_to_push(this_rq);
return;
}
#endif
for_each_cpu(cpu, this_rq->rd->rto_mask) {
if (this_cpu == cpu)
continue;
src_rq = cpu_rq(cpu);
/*
* Don't bother taking the src_rq->lock if the next highest
* task is known to be lower-priority than our current task.
* This may look racy, but if this value is about to go
* logically higher, the src_rq will push this task away.
* And if its going logically lower, we do not care
*/
if (src_rq->rt.highest_prio.next >=
this_rq->rt.highest_prio.curr)
continue;
/*
* We can potentially drop this_rq's lock in
* double_lock_balance, and another CPU could
* alter this_rq
*/
double_lock_balance(this_rq, src_rq);
/*
* We can pull only a task, which is pushable
* on its rq, and no others.
*/
p = pick_highest_pushable_task(src_rq, this_cpu);
/*
* Do we have an RT task that preempts
* the to-be-scheduled task?
*/
if (p && (p->prio < this_rq->rt.highest_prio.curr)) {
WARN_ON(p == src_rq->curr);
WARN_ON(!task_on_rq_queued(p));
/*
* There's a chance that p is higher in priority
* than what's currently running on its cpu.
* This is just that p is wakeing up and hasn't
* had a chance to schedule. We only pull
* p if it is lower in priority than the
* current task on the run queue
*/
if (p->prio < src_rq->curr->prio)
goto skip;
resched = true;
deactivate_task(src_rq, p, 0);
set_task_cpu(p, this_cpu);
activate_task(this_rq, p, 0);
/*
* We continue with the search, just in
* case there's an even higher prio task
* in another runqueue. (low likelihood
* but possible)
*/
}
skip:
double_unlock_balance(this_rq, src_rq);
}
if (resched)
resched_curr(this_rq);
}
4、公平调度类的处理器负载均衡
目前多处理器系统有两种体系结构:NUMA和SMP。
处理器内部的拓扑如下:
a.核(core):一个处理器包含多个核,每个核独立的一级缓存,所有核共享二级缓存。
b.硬件线程:也称为逻辑处理器或者虚拟处理器,一个处理器或者核包含多个硬件线程,硬件线程共享一级缓存和二级缓存。MIPS处理器的叫法是同步多线程(Simultaneous Multi-Threading,SMT),英特尔对它的叫法是超线程。















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









