






难度等级:中级 🎖️🎖️

本文将要涵盖的主要内容:
-
为什么 RAG 重要?
-
RAG 实际是如何工作的
-
应用 RAG 构建一个“与多个 PDF 聊天”的应用
1. 为什么 RAG 重要?
在使用像 GPT、Claude、BERT 等 LLM 模型时,您可能遇到以下问题:
-
模型虚构信息并生成不真实的答案 (幻觉效应)
-
您希望模型 在您自己的数据源上运行,从文本数据(pdf、doc 等)到各种类型的媒体数据(视频、音频、照片等)
-
有时,您处理非常长的内容,导致 昂贵的处理成本 或您的账户简单地被封锁 1-2 小时(影响您的生产力)
如果您对上述问题感同身受,是时候了解 RAG 了。
什么是 RAG?
RAG (检索增强生成) 是一种通过从外部资源获取事实来提高生成 AI 模型准确性和可靠性的技术。RAG 是一种重要的技术,因为:
-
几乎每个 LLM 都可以使用 RAG 连接几乎任何外部资源。
-
RAG 使您的应用程序对我们的用户更可靠(“信任”)。为什么?因为 RAG 为模型提供了可以引用的来源,就像研究论文中的脚注一样,因此用户可以检查任何声明。这建立了信任。
-
减少模型错误猜测的可能性,这种现象有时称为幻觉。
-
最后,RAG 使得这种方法 比使用额外数据集重新训练模型更快且成本更低。并且它允许用户动态更换新的来源。
2. RAG 实际工作原理
从高层次来看,整个 RAG 过程分为两个阶段:
-
阶段 1(预处理): 将外部源加载到我们的系统中
-
阶段 2(推理): 在 LLM 的支持下为用户的查询生成答案

让我们深入了解这两个阶段
阶段 1:预处理阶段
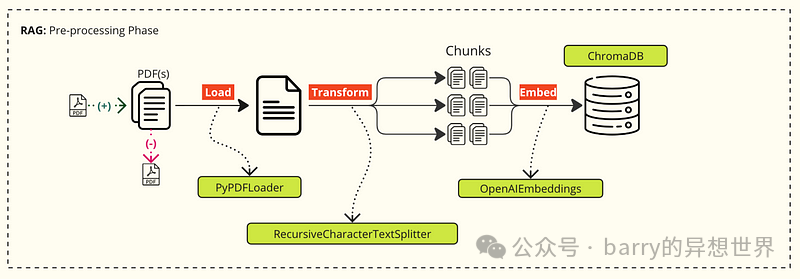
1. 从外部源加载数据到文本: 这个过程在 langchain 框架的支持下很容易完成。
-
在上面的例子中,我使用 PyPDFLoader 从 PDF 文件加载数据
-
在实践中,我还使用其他文档加载器从 YouTube、CSV、Confluence 等加载数据
-
你可以访问 langchain 官方网站 获取所有文档加载器的列表
2. 将文本转换为块: 将文本拆分为小块,以优化信息的处理、存储和检索,同时提高 AI 系统的质量和准确性。
3. 将块嵌入向量数据库: 向量数据库被认为是 RAG 实现堆栈中最常见的方式(在本文中,我也选择了一个可以轻松在本地磁盘上运行的向量数据库,即 Chroma)。选择最佳向量数据库的内容在本文中未涉及。如果你想深入了解这个主题,请查看 SuperLinked 的列表****。
阶段 2:推理运行时阶段
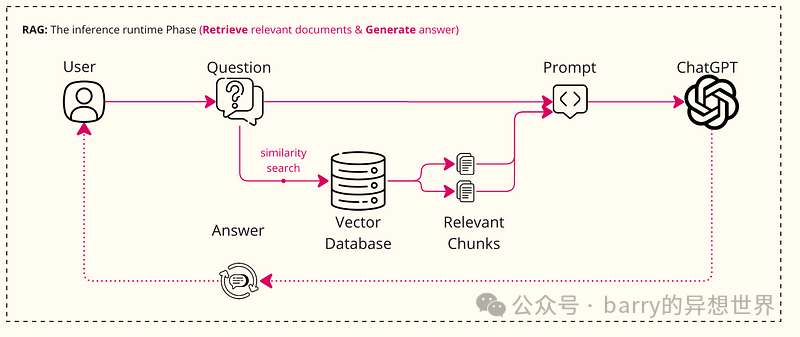
1. 输入查询(问题): 输入查询的用户需要得到回答或处理。
2. 嵌入查询: 使用嵌入模型将查询转换为嵌入。
3. 信息检索: 使用查询的向量表示从包含嵌入文本的大型数据库中查找相关文本。
4. 文本生成器: 提取的文本将与原始查询一起用于生成新的答案或文本。生成器(通常是大型语言模型)将结合这些文本段落中的信息生成反馈。
5. 输出(答案): 创建的文本将作为完整答案返回给用户。
3. 应用 RAG 构建“与多个 PDF 聊天”应用
一旦你了解了 RAG 的工作原理,就该和我一起构建一个“与多个 PDF 聊天”的应用了。并看看我如何将 RAG 应用到实际应用中。
设置
首先,我们需要安装所有包
import streamlit as st
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain_community.vectorstores import Chroma
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
将 OPENAI_API_KEY 替换为您自己的密钥,在示例中,我使用了 streamlit secret:
# Replace it with your OPENAI API KEY if you use streamlit secrets
OPENAI_API_KEY = st.secrets["OPENAI_API_KEY"]
在 ChromaDB 中创建名为 “chat-with-pdf” 的集合
# Load Vector datasse
native_db = chromadb.PersistentClient("./chroma_db")
db = Chroma(client=native_db, collection_name="chat-with-pdf", embedding_function=OpenAIEmbeddings())
为了与集合一起工作,我们将使用函数 get_collection
@st.cache_resource
def get_collection():
print("DEBUG: call get_collection()")
collection = None
try:
# Delete all documents
native_db.delete_collection("chat-with-pdf")
except:
pass
finally:
collection = native_db.get_or_create_collection("chat-with-pdf", embedding_function=OpenAIEmbeddingFunction(api_key=OPENAI_API_KEY))
return collection
阶段 1:预处理阶段
当用户上传一些新文件时:
-
加载所有新上传的文件
-
将其内容拆分为块
-
将块嵌入到 ChromaDB 中,并保存到 ChromaDB
# Load, transform and embed new files into Vector Database
def add_files(uploaded_files):
collection = get_collection()
# old_filenames: contains a list of names of files being used
# uploaded_filenames: contains a list of names of uploaded files
old_filenames = st.session_state.old_filenames
uploaded_filename = [file.name for file in uploaded_files]
new_files = [file for file in uploaded_files if file.name not in old_filenames]
for file in new_files:
# Step 1: load uploaded file
temp_file = f"./temp/{file.name}.pdf"
with open(temp_file, "wb") as f:
f.write(file.getvalue())
loader = PyPDFLoader(temp_file)
pages = loader.load()
# Step 2: split content in to chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
chunks = text_splitter.split_documents(pages)
# Step 3: embed chunks into Vector Store
# collection.add(ids=file.name,documents=chunks)
for index, chunk in enumerate(chunks):
collection.upsert(
ids=[chunk.metadata.get("source") + str(index)], metadatas=chunk.metadata,
documents=chunk.page_content
)
否则,当用户从列表中删除文件时,我们需要删除所有相关的块
# Remove all relevant chunks of the removed files
def remove_files(uploaded_files):
collection = get_collection()
# old_filenames: contains a list of names of files being used
# uploaded_filenames: contains a list of names of uploaded files
old_filenames = st.session_state.old_filenames
uploaded_filename = [file.name for file in uploaded_files]
# Step 1: Get the list of file that was removed from upload files
deleted_filenames = [name for name in old_filenames if name not in uploaded_filename]
# Step 2: Remove all relevant chunks of the removed files
if len(deleted_filenames) > 0:
all_chunks = collection.get()
ids = all_chunks["ids"]
metadatas = all_chunks["metadatas"]
if len(metadatas) > 0:
deleted_ids = []
for name in deleted_filenames:
for index, metadata in enumerate(metadatas):
if metadata['source'] == f"./temp/{name}.pdf":
deleted_ids.append(ids[index])
collection.delete(ids=deleted_ids)
将两个方法合并为一个函数
# Return chunks after having any change in the file list
def refresh_chunks(uploaded_files):
# old_filenames: contains a list of names of files being used
# uploaded_filenames: contains a list of names of uploaded files
old_filenames = st.session_state.old_filenames
uploaded_filename = [file.name for file in uploaded_files]
if len(old_filenames) < len(uploaded_filename):
add_files(uploaded_files)
elif len(old_filenames) > len(uploaded_filename):
remove_files(uploaded_files)
# Step 3: Save the state
st.session_state.old_filenames = uploaded_filename
第2阶段:推理运行时阶段
-
创建一个与ChromaDB协作的检索器。检索器是一个接口,能够根据非结构化查询返回文档。
-
创建一个链条将所有内容连接在一起
# Init langchain
llm = ChatOpenAI(api_key=OPENAI_API_KEY)
prompt = ChatPromptTemplate.from_template("""
Based on the provided context only, find the best answer for my question. Format the answer in markdown format
<context>
{context}
</context>
Question:{input}
""")
document_chain = create_stuff_documents_chain(llm, prompt)
retriever = db.as_retriever()
retriever_chain = create_retrieval_chain(retriever, document_chain)
每当你想使用 retriever_chain 时,可以调用 invoke. 例如:
response = retriever_chain.invoke({"input": "How to create a prompt for a new digital product"})
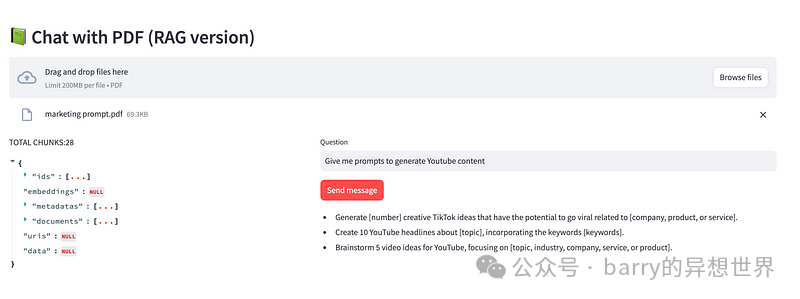
最终结果:
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}