






就在刚刚,Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!
Transformer和Diffusion,终于有了一次出色的融合。
自此,语言模型和图像生成大一统的时代,也就不远了!
这背后,正是Meta最近发布的Transfusion——一种训练能够生成文本和图像模型的统一方法。

论文地址:https://arxiv.org/abs/2408.11039
英伟达高级科学家Jim Fan盛赞:之前曾有很多尝试,去统一Transformer和Diffusion,但都失去了简洁和优雅。
现在,是时候来一次Transfusion,来重新激活这种融合了!

在X上,论文共一Chunting Zhou,为我们介绍了Transfusion其中的「玄机」。

为何它能让我们在一个模型中,同时利用两种方法的优势?
这是因为,Transfusion将语言建模(下一个token预测)与扩散相结合,这样,就可以在混合模态序列上训练单个Transformer。
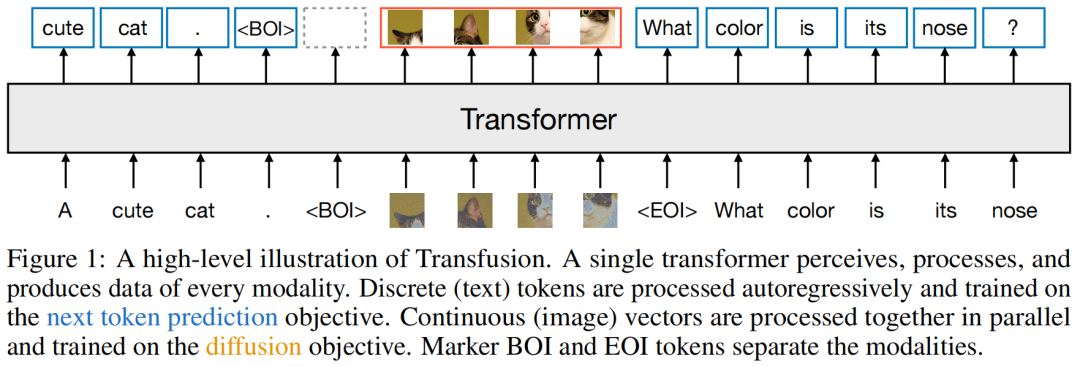
研究者从头开始,在混合文本和图像数据上预训练了参数量高达70亿的Transfusion模型。
使用文本和图像数据的混合,他们建立了一系列单模态和跨模态基准的缩放定律。
实验表明,Transfusion在单模态和多模态基准测试中,相较于对图像进行量化并在离散图像token上训练语言模型,很明显具有更好的扩展性。
研究者发现,Transfusion能够生成与相似规模的扩散模型相媲美的高质量图像,而且,它同时也保持了强大的文本生成能力。

作者强调,团队着重做了建模的创新。
首先,全局因果注意力加上每个图像内的双向注意力,是至关重要的。
另外,引入模态特定的编码和解码层后,可以提高性能,并且可以将每个图像压缩到64甚至16个块!
总之,研究者成功地证明了,将Transfusion方法扩展到70亿参数和2万亿多模态token后,可以生成与类似规模的扩散模型和语言模型相媲美的图像和文本。
这就充分利用了两者的优势!
最后,作者激动地畅想道——
Transfusion为真正的多模态AI模型开启了激动人心的可能性。
这些模型可以无缝处理任何离散和连续模态的组合!无论是长篇视频生成、与图像或视频的交互式编辑/生成会话,我们都可以期待了。
生图效果秒杀DALL-E 2和Stable Diffusion
Transfusion的生图效果如何?让我们来检验一下。
以下这些,都是用在2万亿多模态token上训练的70亿参数Transfusion生成的图像——
可以看出,它的生图质量非常之高。
在GenEval基准测试上,它直接超越了DALL-E 2和Stable Diffusion XL!




左右滑动查看(共四组)




左右滑动查看(共四组)




左右滑动查看(共四组)
研究者训练了一个具有U-Net编码/解码层(2×2潜在像素块)的70亿参数模型,处理相当于2T tokens的数据,其中包括1T文本语料库tokens和35亿张图像及其标注。
表9显示,Transfusion在性能上与高性能图像生成模型如DeepFloyd相当,同时超越了先前发布的模型,包括SDXL。
虽然Transfusion在SD 3后面稍显逊色,但该模型通过反向翻译利用合成图像标注,将其GenEval性能在小规模上提升了6.5%(0.433→0.498)。
此外,Transfusion模型也可以生成文本,并且其性能与在相同文本数据分布上训练的Llama模型相当。
图像编辑
以下这些,则是用微调后的70亿参数Transfusion模型编辑的图像——



左右滑动查看(共三组)



左右滑动查看(共三组)
研究者使用仅包含8000个公开可用图像编辑示例的数据集对70亿参数模型进行了微调,其中每个示例包括一个输入图像、一个编辑提示词和一个输出图像。
对EmuEdit测试集中随机示例的人工检查表明,微调的Transfusion模型可以按照指示进行图像编辑。也就是说,Transfusion模型确实可以适应并泛化到新的模态组合。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

让语言和图像大一统的模型来了
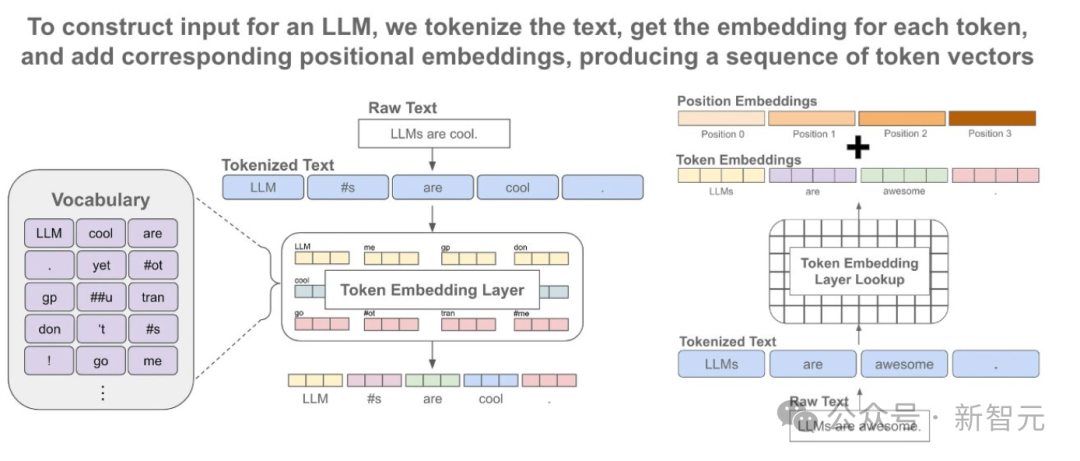
我们都知道,多模态生成模型需要能够感知、处理和生成离散元素(如文本或代码)和连续元素(例如图像、音频和视频数据)。
不过,离散元素和连续元素,却很难在同一个模型中大一统起来。
在离散模态中,是语言模型占主导地位,它靠的是在下一个token预测目标上训练的。
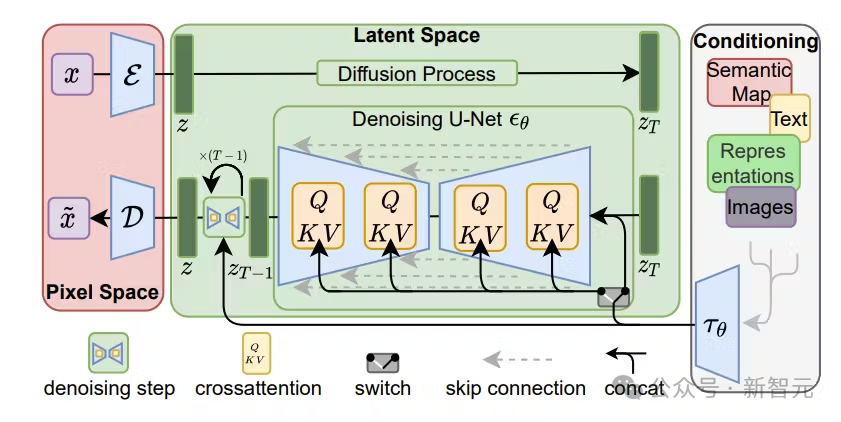
而在生成连续模态上,则是扩散模型及其泛化一直处于最前沿。
有没有可能将二者相结合呢?
此前,学界曾尝试了多种方法,包括扩展语言模型,以使用扩散模型作为工具,或者通过将预训练的扩散模型移植到语言模型上。
此外,还有人通过量化连续模态,在离散tokens上训练标准语言模型,从而简化模型架构。然而这样做的代价,就是信息的丢失。
而Meta的研究者在这项工作中,通过训练单个模型,来同时预测离散文本tokens和扩散连续图像,他们成功地做到了完全整合两种模态,而不丢失信息。
他们的方法就是——引入Transfusion。
这是一种训练单一统一模型的方法,可以无缝理解和生成离散和连续的模态。
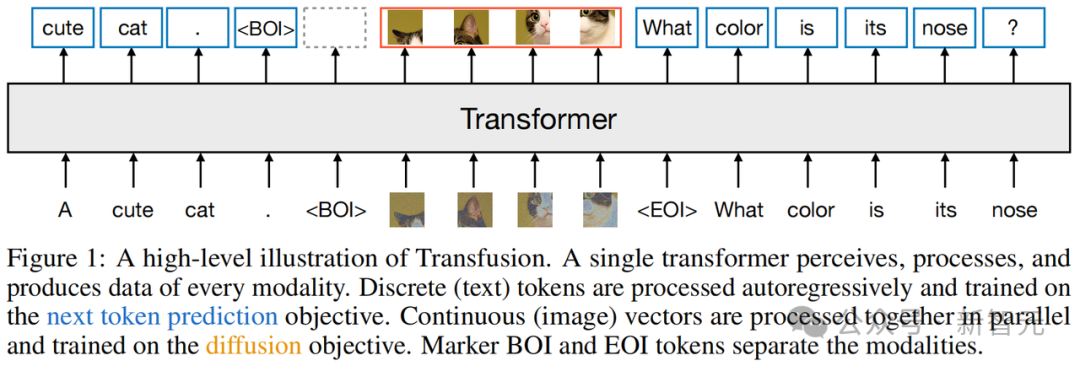
研究者的主要创新就在于,他们针对不同的模态使用了不同的损失——文本使用语言建模,图像使用扩散——从而在共享的数据和参数上进行训练
研究者在50%的文本和50%的图像数据上预训练了一个Transformer模型,不过对于两种模态来说,分别使用了不同的目标。
前者的目标是,预测文本的下一个token;而后者的目标,则是图像的扩散。
在每个训练步骤中,模型都会同时接触到这两种模态和损失函数。标准嵌入层将文本tokens转换为向量,而块化层(patchification layer)则将每个图像表征为一系列块向量。
随后,研究者对文本tokens应用因果注意力,对图像块应用双向注意力。
在推理时,他们引入了一种解码算法,它结合了语言模型的文本生成和扩散模型的图像生成的标准实践。
从此,有望训练真正的多模态模型
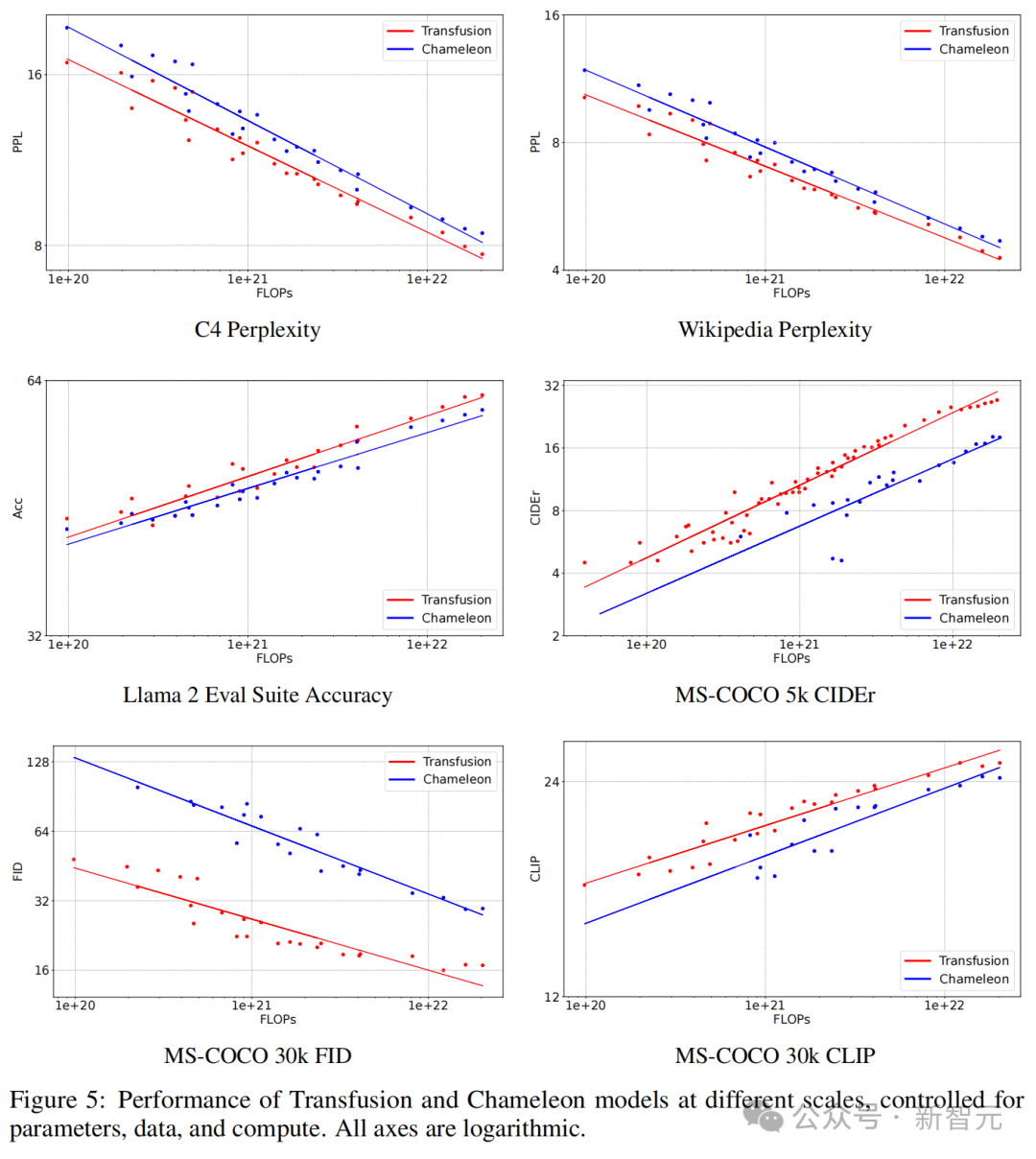
在文本到图像生成中,研究者发现:Transfusion在计算量不到三分之一的情况下,FID和CLIP分数均超过了Chameleon的离散化方法。
在控制FLOPs的情况下,Transfusion的FID分数比Chameleon模型低约2倍。
在图像到文本生成中,也可以观察到类似的趋势:Transfusion在21.8%的FLOPs下与Chameleon匹敌。
令人惊讶的是,Transfusion在学习文本到文本预测方面也更有效,在大约50%到60%的Chameleon FLOPs下实现了文本任务的困惑度平价。
同时,研究者观察到:图像内的双向注意力非常重要,如果用因果注意力替代它,就会损害文本到图像生成。
他们还发现,通过添加U-Net上下块来编码和解码图像,就可以使Transfusion在相对较小的性能损失下,压缩更大的图像块,从而能将服务成本降低到多达64倍。
最后,研究者证明了:Transfusion可以生成与其他扩散模型相似质量的图像。
他们在2万亿tokens上,从零开始训练了一个7B参数的Transformer,它增强了U-Net的下采样/上采样层(0.27B参数)。
在这2万亿tokens中,包含1万亿的文本tokens,以及大约5个周期的692M图像及标注,相当于另外1万亿个patches/tokens。
在GenEval基准上,Transfusion模型优于其他流行模型,如DALL-E 2和SDXL。
而且,与那些图像生成模型不同的是,它还可以生成文本,在文本基准上达到了Llama 1级别的性能水平。
总之,实验表明:Transfusion是一种十分有前途的方法,可以用于训练真正的多模态模型。
数据表征
研究者在两种模态上进行了数据实验:离散文本和连续图像。
每个文本字符串被标记化为来自固定词汇表的离散token序列,其中每个token被表征为一个整数。
每个图像被编码为使用VAE的潜在块,其中每个块被表征为一个连续向量;这些块从左到右、从上到下排序,以从每个图像创建一个块向量序列。
对于混合模态的例子,研究者在将图像序列插入文本序列之前,用特殊的图像开始(BOI)和图像结束(EOI)token包围每个图像序列。
因此,就得到了一个可能同时包含离散元素(表征文本token的整数)和连续元素(表征图像块的向量)的单一序列。
模型架构
模型的大部分参数属于一个单一的Transformer,它会处理每个序列,无论模态如何。
Transformer将一个高维向量序列作为输入,并生成类似的向量作为输出。
为了将数据转换到这个空间,研究者使用了具有不共享参数的轻量级模态组件。
对于文本,这些自己组件是嵌入矩阵,会将每个输入整数转换为向量空间,并将每个输出向量转换为词汇表上的离散分布。
对于图像,研究者则尝试了两种方法,将k×k块向量的局部窗口压缩为单个Transformer向量(反之亦然):(1)一个简单的线性层,以及(2)U-Net的上下块。
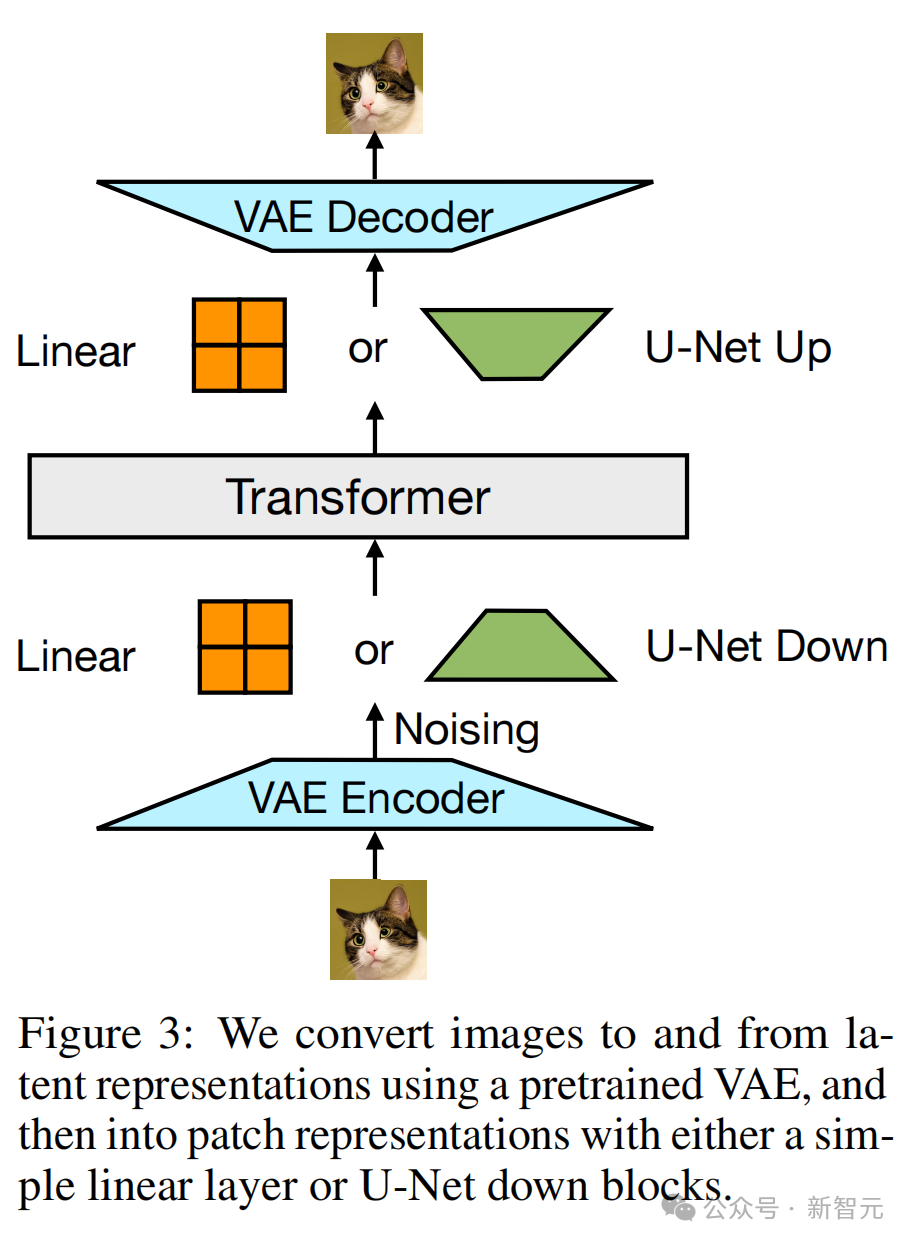
研究者使用预训练的VAE(变分自编码器)将图像和潜在表征进行互相转换,然后通过简单的线性层或U-Net下采样块,将其转换为patch表征
Transfusion注意力
语言模型通常使用因果掩码,来有效地计算整个序列的损失和梯度,只需一次前向-后向传递,而不会泄露未来token的信息。
相比之下,图像通常会使用不受限制的(双向)注意力来建模。
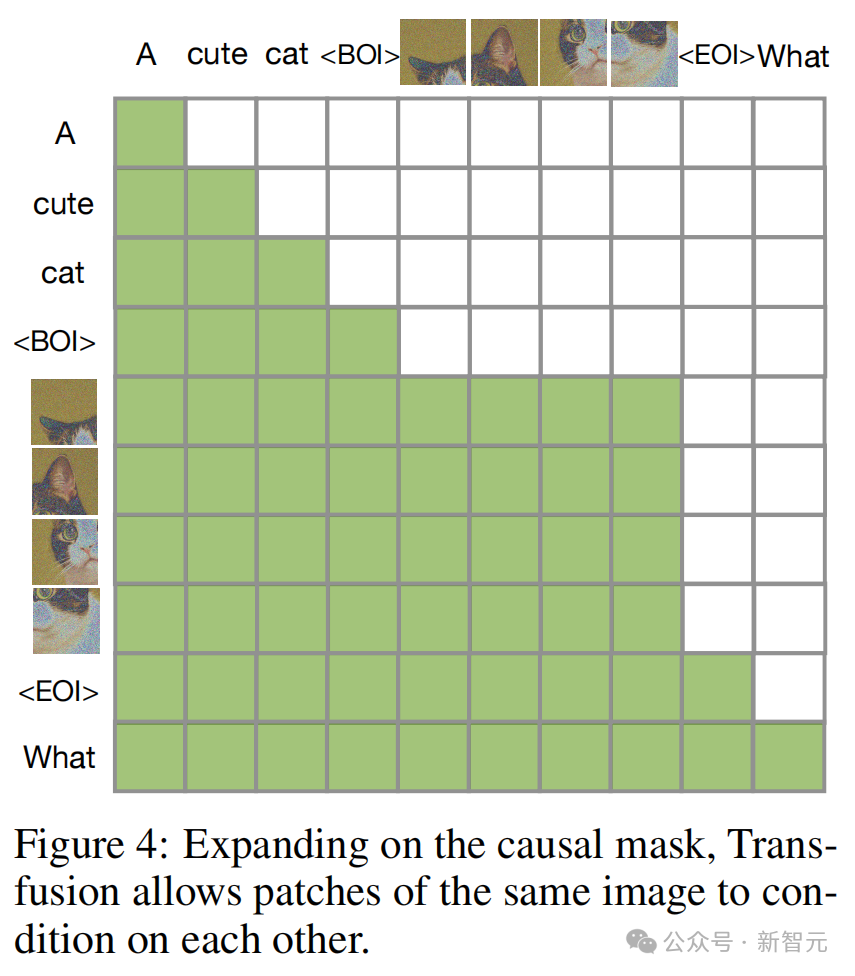
而Transfusion通过对序列中的每个元素应用因果注意力,并在每个单独图像的元素内应用双向注意力,来结合这两种注意力模式。
这样,每个图像块就可以在关注同一图像中其他块的同时,只关注序列中先前出现的文本或其他图像的块。
结果显示,启用图像内注意力显著提升了模型性能。

在因果掩码上扩展后,Transfusion就允许同一图像的patch相互为条件
训练目标
为了训练模型,研究者将语言建模目标LLM应用于文本token的预测,将扩散目标LDDPM应用于图像块的预测。
LM损失是逐个token计算的,而扩散损失是逐个图像计算的,这可能跨越序列中的多个元素(图像块)。
具体来说,他们根据扩散过程,向每个输入潜在图像x0添加噪声ε,以在块化之前产生xt,然后计算图像级别的扩散损失。
通过简单地将每种模态上计算出的损失与平衡系数λ结合,研究者合并了这两种损失:
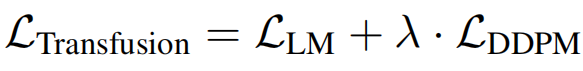
这个公式,也是一个更广泛想法的具体实例:将离散分布损失和连续分布损失结合,就可以优化同一模型。
推理
为了反映训练目标,解码算法也需要在两种模式之间切换:LM和扩散。
在LM模式中,从预测分布中逐个token进行采样。当采样到一个BOI token时,解码算法切换到扩散模式。
具体来说,这需要将形式为n个图像块的纯噪声xT附加到输入序列中(取决于所需的图像大小),并在T步内去噪。
在每一步t中,噪声会被预测并使用它生成x_(t−1),然后将其覆盖在序列中的x_t上。即,模型始终基于噪声图像的最后一个时间步进行条件处理,无法关注之前的时间步。
一旦扩散过程结束,就将一个EOI token附加到预测的图像上,并切换回LM模式。
如此一来,就可以生成任意混合的文本和图像模态。
实验
与Chameleon的比较
研究者在不同模型规模(N)和token计数(D)下,比较了Transfusion与Chameleon,并使用两者的组合作为FLOPs(6ND)的代理。
为了简化和参数控制,这些实验中的Transfusion变体使用简单的线性图像编码器/解码器,块大小为2×2,以及双向注意力。
如图5所示,在每个基准测试中,Transfusion始终表现出比Chameleon更好的scaling law。
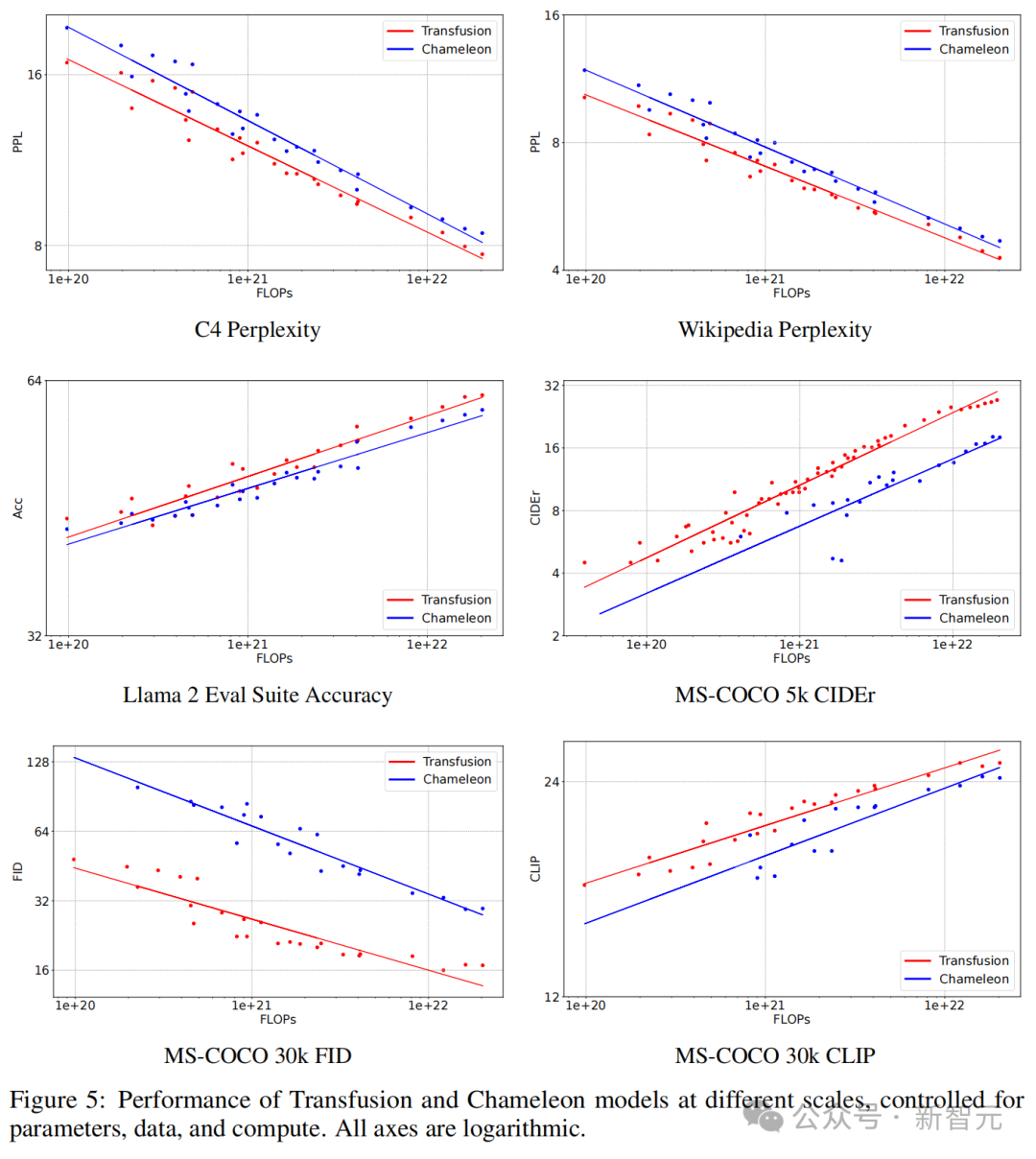
受参数、数据和计算控制的不同规模的Transfusion和Chameleon模型的性能,其中所有轴都是对数的
表3则显示了模型的评估结果,以及平价FLOP比率。
其中,平价FLOP比率用来估算相对计算效率:Transfusion和Chameleon达到相同性能水平所需的FLOPs数量之比。
计算效率的差异在图像生成中特别显著,其中FID Transfusion以1/34的计算量实现了与Chameleon的平价。
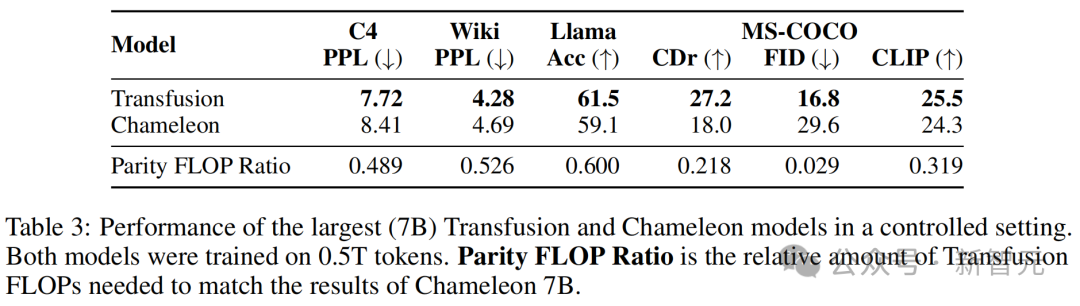
最大(7B)Transfusion和Chameleon模型在受控环境中的性能,两个模型均在0.5T token上进行训练
令人惊讶的是,纯文本基准测试也显示出Transfusion的更好性能,即使Transfusion和Chameleon以相同方式建模文本。
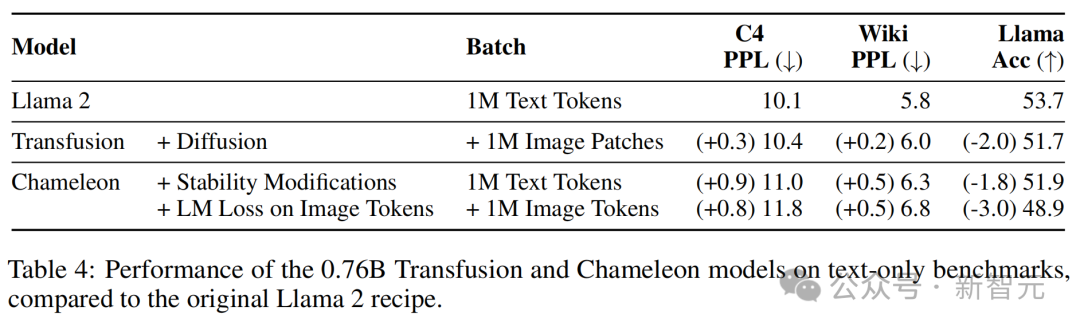
与原始Llama 2配方相比,0.76B Transfusion和Chameleon模型在纯文本基准上的性能
架构消融
- 注意力掩码
表5显示,在所有基准测试中,启用这种注意力模式比标准因果注意力效果更好,并且在使用图像编码/解码架构时也是如此。特别是,在使用线性编码层时,FID的改善最为显著(61.3→20.3)。
在仅因果的架构中,序列中后出现的块不会向前面的块传递信息;由于U-Net块内含有双向注意力,并独立于Transformer的注意力掩码,因此这种差距不太明显。
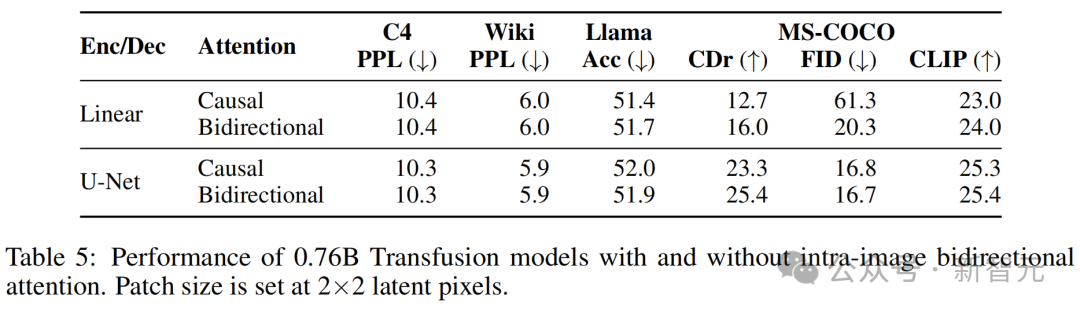
有/无图像内双向注意力的0.76B Transfusion模型的性能
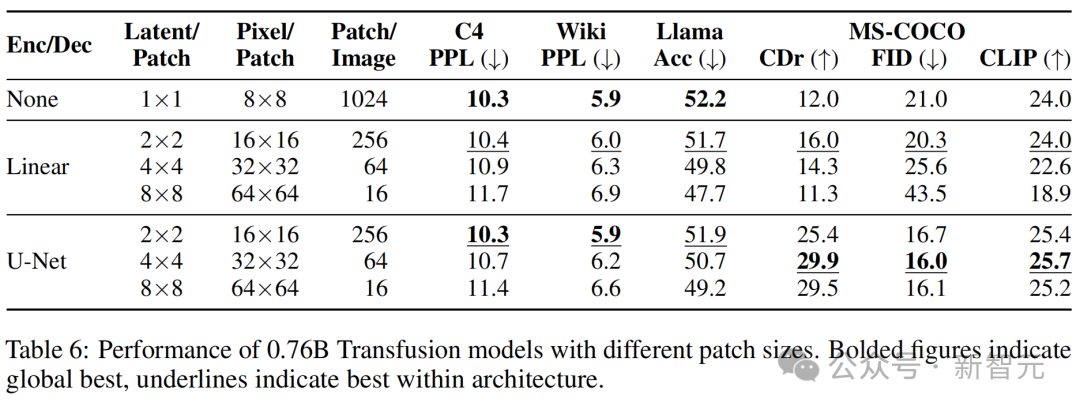
- 块大小
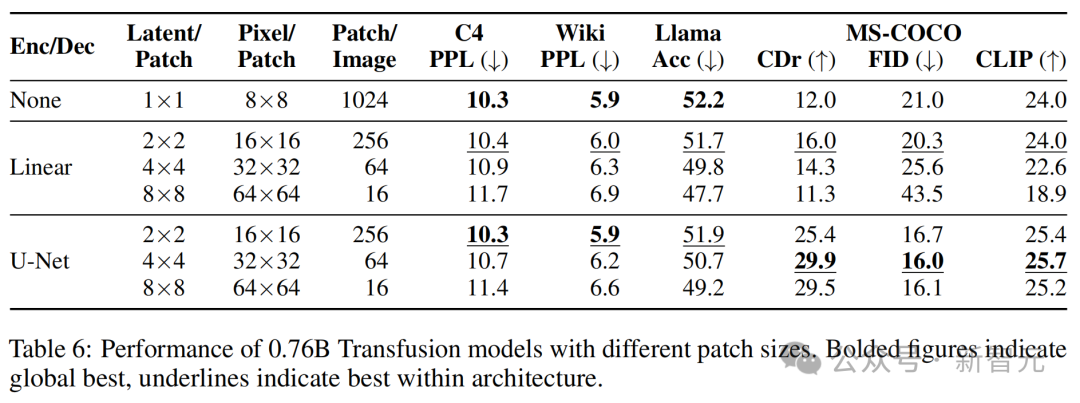
Transfusion模型可以在不同尺寸的潜在像素块上定义。较大的块大小允许模型在每个训练批次中打包更多图像,并显著减少推理计算量,但可能会带来性能损失。
表6显示,虽然随着每个图像由更少的线性编码块表征,性能确实一致下降,但使用U-Net编码的模型在涉及图像模态的任务中受益于较大的块。
这可能是因为训练期间看到的总图像(和扩散噪声)数量更大。
此外,随着块逐渐变大,文本性能也在变差。
这可能是因为Transfusion需要投入更多资源(即参数)来学习如何处理具有较少块的图像,从而减少推理计算。
- 块编码/解码架构
实验表明,使用U-Net的上升和下降块比使用简单的线性层有优势。
一个可能的原因是模型受益于U-Net架构的归纳偏置;另一种假设是,这种优势来自于U-Net层引入的整体模型参数的显著增加。
为了分离这两个混杂因素,研究者将核心Transformer扩展到70亿个参数,同时保持U-Net参数量(几乎)不变;在这种设置下,额外的编码器/解码器参数仅占总模型参数的3.8%增加,相当于token嵌入参数的量。
表7显示,尽管随着Transformer的增长,U-Net层的相对优势缩小,但并未消失。
例如,在图像生成中,U-Net编码器/解码器使得较小的模型能够获得比使用线性块化层的70亿模型更好的FID分数。
在图像描述中,也有类似的趋势——添加U-Net层让1.4B Transformer(总计1.67B)的CIDEr得分超过了线性70亿模型的性能。
总体而言,U-Net对图像的编码和解码确实具有归纳偏置的优势。
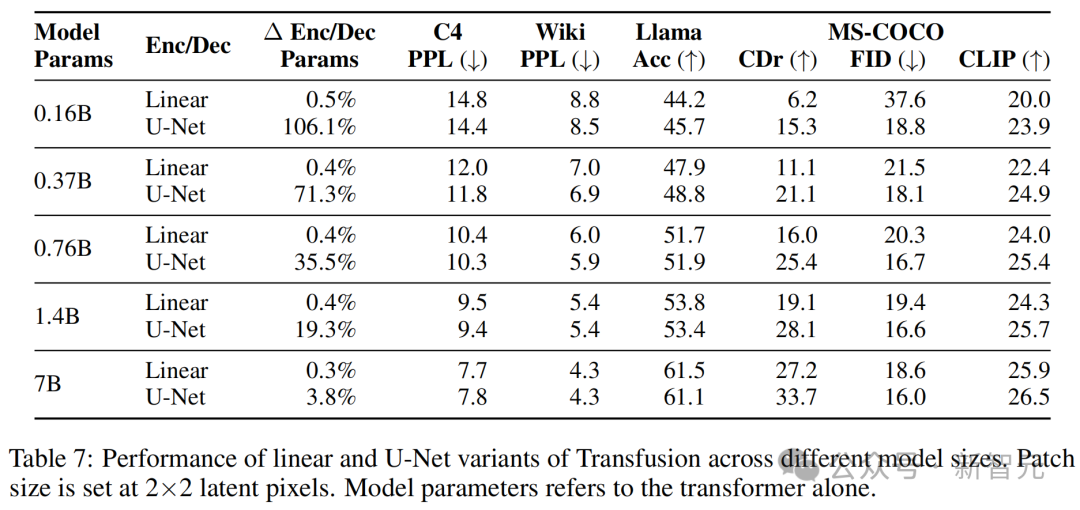
Transfusion的线性和U-Net变体在不同模型大小上的性能
- 图像加噪
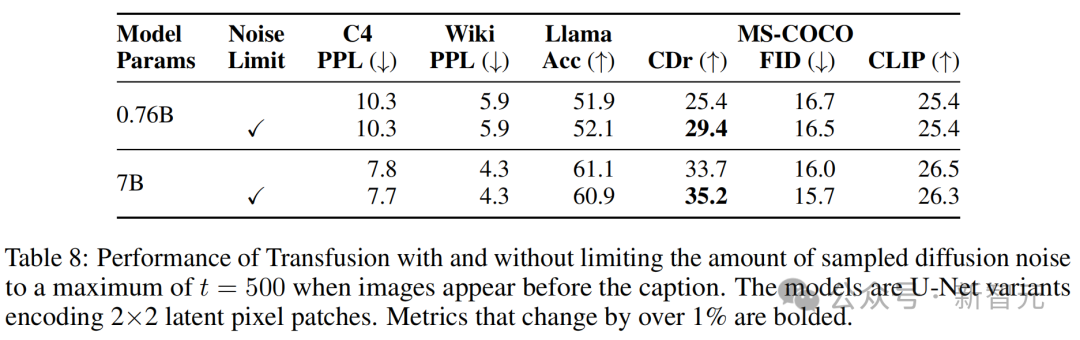
实验中,80%的图像-标注对按照标注优先的顺序排列,图像依赖于标注,这基于图像生成可能比图像理解更需要数据的直觉。剩下的20%对则是标注依赖于图像。
然而,这些图像需要作为扩散目标的一部分被加噪。
为此,研究者测量了在20%的情况下限制扩散噪声到最大t=500,即图像在标注之前出现时的效果。
表8显示,限制噪声显著改善了图像描述,CIDEr得分显著提高,同时对其他基准测试的影响相对较小(小于1%)。
结论
这项研究探讨了如何弥合离散序列建模(下一个token预测)与连续媒体生成(扩散)之间的差距。
研究者提出了一个简单但以前未被探索的解决方案:在两个目标上训练一个联合模型,将每种模态与其偏好的目标联系起来。
实验表明,Transfusion可以有效扩展,几乎没有参数共享成本,同时能够生成任何模态。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}