






CLIP = Contrastive Language-Image Pre-training,顾名思义,这是一个基于对比学习的语言图像多模态学习方法。CLIP训练的目的其实主要还是获得通用的图像表征模型,因此在CLIP框架里,语言数据可以认为是作为监督信号存在的,类似图像分类任务中的类别信号,只是从一个one hot label扩展成了自然语言的形式。使用自然语言作为监督信号的好处是,自然语言信号更加灵活,可以支持扩展到zero-shot的推理,并且能够提供更加丰富的监督信息。
数据
其实在CLIP之前就有好些多模态训练的工作,但是效果没有这么好,原因主要是数据量不够大,另外就是对自然语言数据使用不够好,未能充分发挥自然语言的作用。因此一个很重要的工作就是构建数据集。CLIP是这么干的:
-
以英文维基百科中出现至少 100 次的所有单词为基础构建词集,并增加了双词组合和所有 WordNet 同义词
-
爬取网上的数据,试(图像,文本)数据对中的文本包含词集中的一个词
-
为了尽可能覆盖广泛的视觉概念,对结果进行平衡,每个概念最多包括 20,000 个(图像,文本)对
-
构建的 WIT(WebImageText) 数据集包含 4 亿个(图像,文本)对
WIT数据集比之前很多多模态数据集都大,包含的内容也更丰富。
训练框架
CLIP预训练框架如下图:
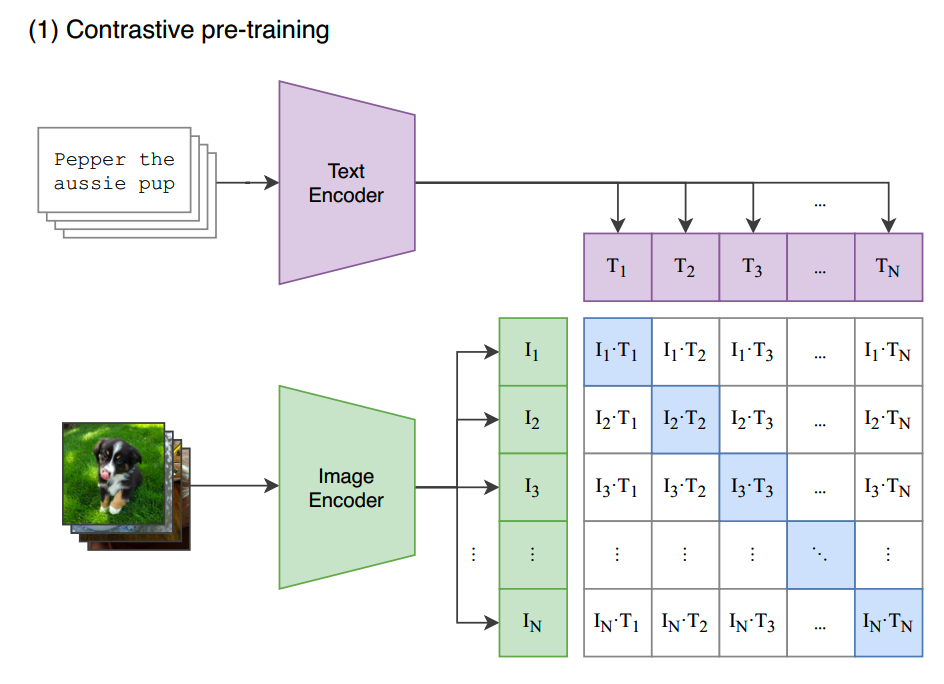
text encoder和image encoder分别对文本和图像进行编码。text encoder通过对比学习,把文本的表征向match的图像靠拢,而和batch内其他图像,也就是负样本的距离尽量拉大。image encoder也是同样地学习图像表征。
训练的pseudo-code如下:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
在clip的训练框架中,text encoder和image encoder的地位是对称的。
和之前的对比学习一样,为了提升学习的效果,负样本需要尽量多,因此实验中使用32,768的batch size。
理论上,text encoder和image encoder可以是任意模型。OpenAI选择了ResNet/EfficientNet-style的模型和几个ViT(ViT-B/32、ViT-B/16、ViT-L/14)作为image encoder进行实验,而text encoder则是使用GPT-2的结构,最后一层的 [EOS] token 就作为text representation。
训练中,image encoder和text encoder都是随机初始化的,不需要预先训练。
使用
完成预训练之后,一个常规的用法是基于image encoder进行微调,包括仅训练classifier,和完整模型的训练。
CLIP另一个强项就是可以做zero-shot predictor。比如我们想要知道让预训练模型对一张图片的类别进行预测,可以把所有可能的类别填进一个prompt里:“A photo of {object}”,然后让text encoder给出所有representation,并计算不同类别下的text representation和image representation的相似度,取最高的那个就是预测结果了:
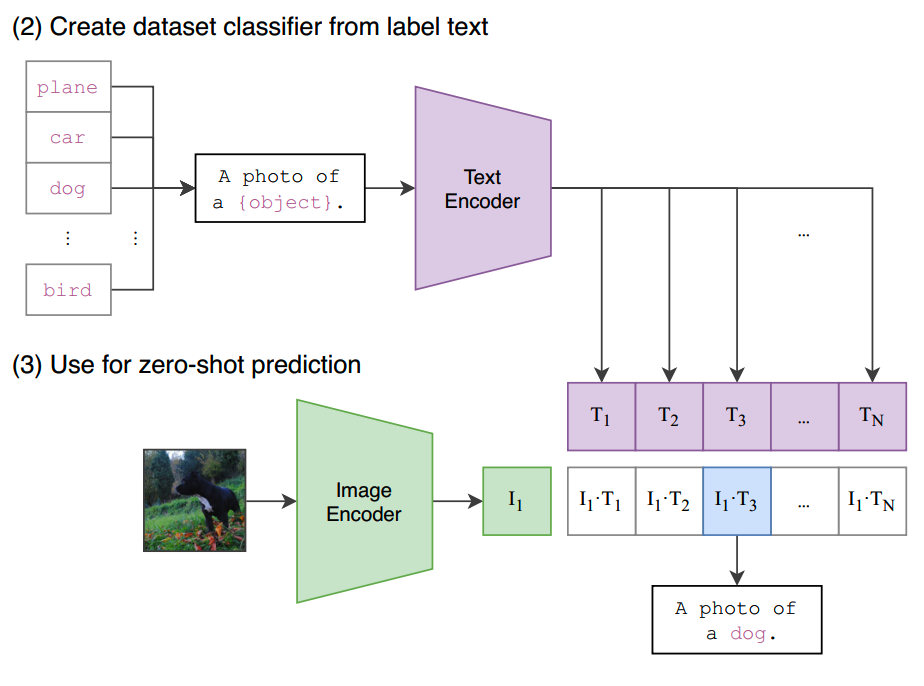
当然CLIP的用法不仅是可以做zero-shot的图像分类,后续还有很多其他应用方法,挖个坑后面来填。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









