






LLM 支持的最强大的应用程序之一是复杂的问答 (Q&A) 聊天机器人。这些应用程序可以回答有关特定源信息的问题。这些应用程序使用一种称为[检索增强生成 (RAG)] 的技术。
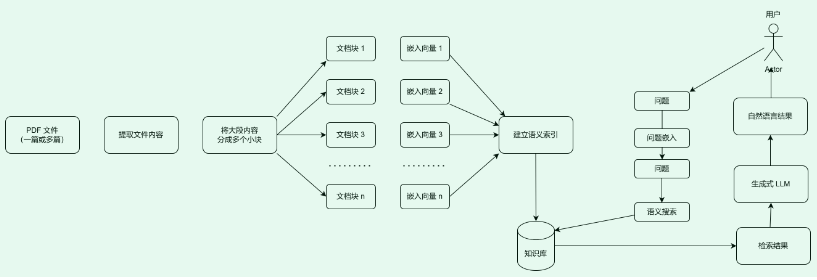
什么是 RAG?
RAG 是一种通过附加数据增强 LLM 知识的技术。
LLM 可以推理广泛的主题,但它们的知识仅限于它们接受训练的特定时间点的公共数据。如果你想构建能够推理私有数据或模型截止日期后引入的数据的 AI 应用程序,则需要使用模型所需的特定信息来增强模型的知识。将适当的信息插入模型提示的过程称为检索增强生成 (RAG)。
典型的 RAG 应用程序有两个主要组件:
-
索引:从源中提取数据并对其进行索引的管道。这通常是离线进行的。
-
检索和生成:实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案的最常见完整序列如下所示:
索引
-
加载:首先,我们需要加载数据。这是通过文档加载器完成的。
-
拆分:文本拆分器将大型文档拆分成较小的块。这对于索引数据和将其传递给模型都很有用,因为大块更难搜索,并且不适合模型的有限上下文窗口。
-
存储:我们需要一个地方来存储和索引我们的拆分,以便以后可以搜索它们。这通常使用 VectorStore 和 Embeddings 模型来完成。
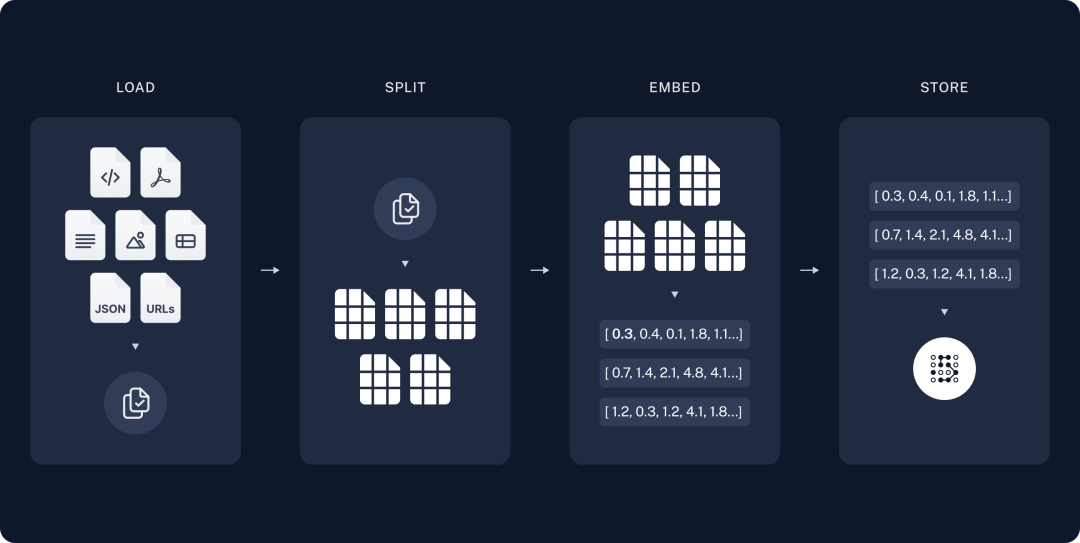
检索和生成
4. 检索:给定用户输入,使用检索器从存储中检索相关文档块。
5. 生成:ChatModel/LLM 使用包含问题和检索到的数据的提示生成答案。
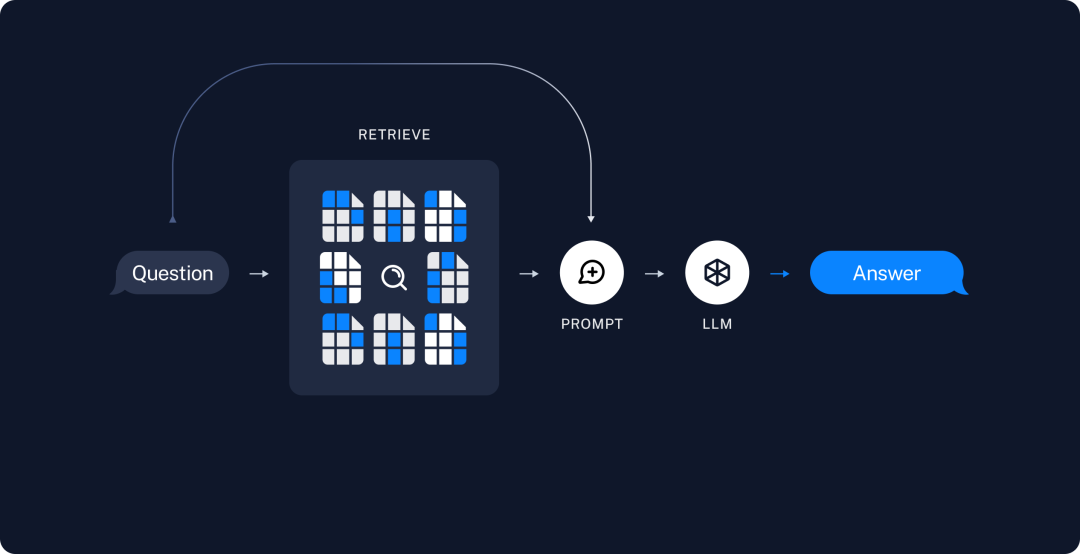
接下来我将按照上述步骤,使用 LangChain + OpenAI + Qdrant 实现一个简单的 RAG 应用。
Qdrant 是一种 VectorStore(向量数据库)。我们可以将文档块的嵌入表示存储在 VectorStore 中。
加载 & 拆分
我将使用 GPT4All 的技术报告来作为我们这个 RAG 应用的数据源,你可以在项目的 data 目录下看到名为《2023_GPT4All_Technical_Report》的 PDF 文件。
第一步是导入我在环境变量中设置的 OpenAI 的配置信息:
import os
OPENAI_API_BASE = os.environ.get('OPENAI_API_BASE')OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')
然后就可以配置 LLM 和 embedding 模型了:
from langchain_openai import ChatOpenAIfrom langchain_openai import OpenAIEmbeddings
llm = ChatOpenAI(model="gpt-3.5-turbo")embeddings = OpenAIEmbeddings()
1. 加载 PDF 文件
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/2023_GPT4All_Technical_Report.pdf")
pages = []async for page in loader.alazy_load(): pages.append(page)
2. 拆分
虽然我们加载的文档并不长,但是在你可能会加载更长的文档。当文档过长时,就无法放入许多模型的上下文窗口中(一般模型的上下文窗口只有 32k或者 64k)。
为了解决这个问题,我们将文档拆分成块以进行嵌入和向量存储。这应该有助于我们在运行时仅检索文档中最相关的部分。
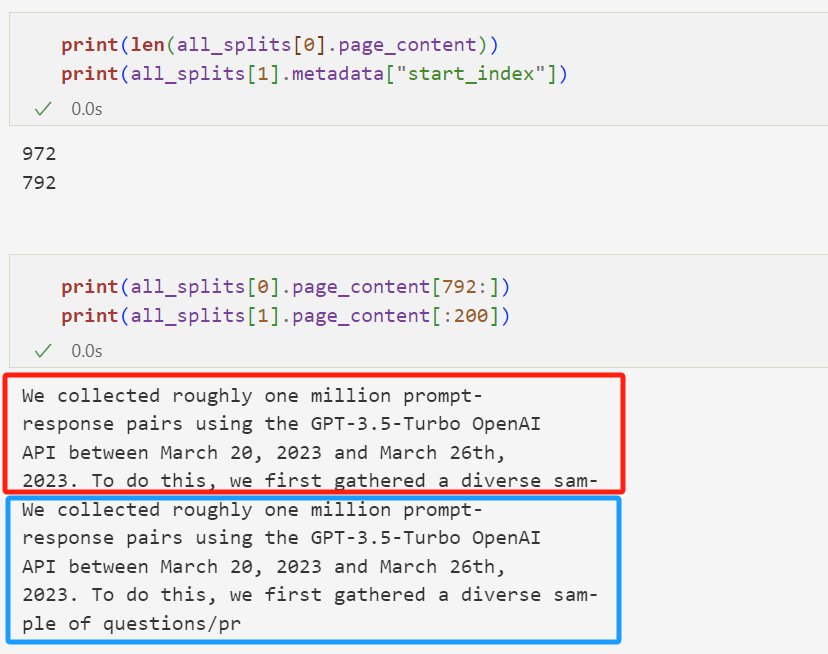
在这种情况下,我们将文档拆分成 1000 个字符的块,块之间有 200 个字符的重叠。重叠有助于减轻将语句与与其相关的重要上下文分离的可能性。我们使用 RecursiveCharacterTextSplitter,它将使用常用分隔符(如换行符)递归拆分文档,直到每个块的大小合适。这是针对一般文本用例的推荐文本拆分器。
我们设置 add_start_index=True,以便每个拆分文档在初始文档中开始的字符索引保留为元数据属性“start_index”。
可以看到是两个块之间是有重叠的:
存储
3. 存储
我们将使用语义搜索实现检索功能,所以最常见的方法是嵌入每个文档拆分的内容,并将这些嵌入插入到 VectorStore 中。
当用户输入查询后,查询也会被转成嵌入向量,然后执行某种“相似性”搜索,以识别与我们的查询嵌入最相似的嵌入的文档块。最简单的相似性度量是余弦相似性:测量每对嵌入(高维向量)之间角度的余弦。
现在我们将使用 OpenAIEmbeddings 模型在单个命令中嵌入所有文档块。并使用 Qdrant 存储。
默认使用的 OpenAI 嵌入模型是 text-embedding-ada-002,它将文本转成 1536 维的向量。所以我们可以这样初始化 Qdrant:

我们创建了一个名为 demo_collection 的 VectorStore,现在我们将文档块加进去:

检索 & 生成
现在让我们编写实际的应用程序逻辑。我们想要创建一个简单的应用程序,它接受用户问题:
-
搜索与该问题相关的文档,
-
将检索到的文档和初始问题传递给模型,并返回答案。
4. 检索
首先,我们需要定义搜索文档的逻辑。LangChain 定义了一个 Retriever 接口,它包装了一个索引,可以根据字符串查询返回相关文档。
最常见的 Retriever 类型是 VectorStoreRetriever,它使用向量存储的相似性搜索功能来促进检索。任何 VectorStore 都可以通过 VectorStore.as_retriever() 轻松转换为 Retriever:
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 6})
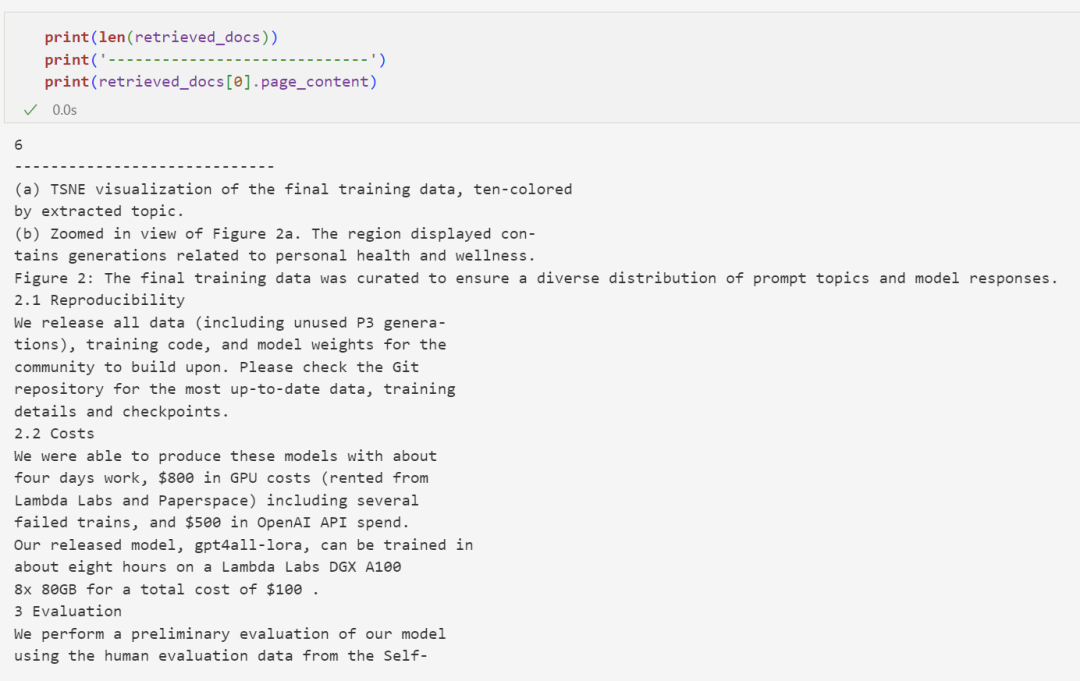
retrieved_docs = retriever.invoke("What was the cost of training the GPT4all-lora model?")
当我们检索训练 GPT4all-lora 模型花费了多少时,我们可以得到 6 段与这个问题在语义上相似的文档块:
5. 生成
让我们将所有内容整合成一个链条,该链条接收问题、检索相关文档、构造提示、将其传递给模型并解析输出。
我们将使用 gpt-3.5-turbo OpenAI 聊天模型,但你可以替换成任何 LangChain LLM 或 ChatModel。
import textwrapfrom langchain.chains import create_retrieval_chainfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_core.prompts import ChatPromptTemplate
system_prompt = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer " "the question. If you don't know the answer, say that you " "don't know. Use three sentences maximum and keep the " "answer concise." "\n\n" "{context}")
prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), ("human", "{input}"), ])
question_answer_chain = create_stuff_documents_chain(llm, prompt)rag_chain = create_retrieval_chain(retriever, question_answer_chain)
response = rag_chain.invoke({"input": "What was the cost of training the GPT4all-lora model?"})print(textwrap.fill(response["answer"], 80))

我们可以从原文看到答案其实应该只需要红框内的就行了:

我们再问该技术报告的作者是谁?
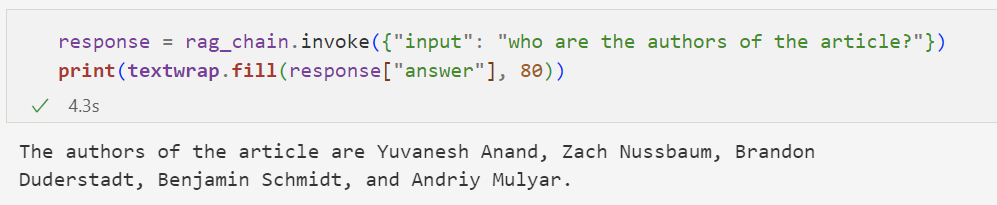
这次是完全正确的:

那么我们再问一下从文档中查不到答案的问题:

这个回复还算友好。
源码链接:
https://github.com/realyinchen/RAG/blob/main/ChatGPT%20for%20YOUR%20OWN%20PDF%20files%20with%20LangChain.ipynb
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 74
74

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}