







模型压缩大致分为:
- 剪枝
- 量化
- 蒸馏
- 参数共享
知识蒸馏
使用target 蒸馏
根据蒸馏方法不同可以分为soft-target蒸馏(confidence/Logits蒸馏)和基于特征的蒸馏.
- Hard-target:原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。
- Soft-target:Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。
Distilling the Knowledge in a Neural Network使用的蒸馏方式如下:
- 训练好teacher model
- 使用高温下的soft target 和T=1场景下的hard target同时训练student model.

同时使用soft target 和hard target蒸馏student model.
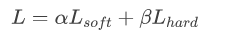
其中 L s o f t L_{soft} Lsoft定义如下:
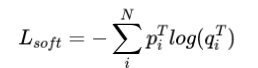
其中 p i T p_i^T piT和 q i T q_i^T qiT定义如下:
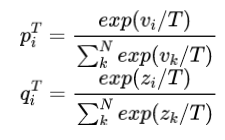
而 L h a r d L_{hard} Lhard loss和前面的soft loss类似, 只不过T=1, c i {c_i} ci为hard target.
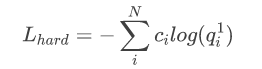
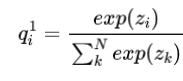
T >1时,负样本能发挥出作用, T==1时就是hart target了.所以训练初期会使用高温蒸馏一段时间, 保证负样本能被学习到.

- 使用kl散度做为损失函数
参考 Distilling the Knowledge in a Neural Network
代码:class SoftTarget(nn.Module): ''' Distilling the Knowledge in a Neural Network https://arxiv.org/pdf/1503.02531.pdf ''' def __init__(self, T): super(SoftTarget, self).__init__() self.T = T def forward(self, out_s, out_t): loss = F.kl_div(F.log_softmax(out_s/self.T, dim=1), F.softmax(out_t/self.T, dim=1), reduction='batchmean') * self.T * self.T return loss
使用logits蒸馏
直接将网络输出的logits(softmax的输入)作为soft target.使用MSE作为损失函数.
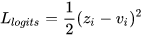
使用特征层蒸馏


把“宽”且“深”的网络蒸馏成“瘦”且“更深”的网络,需要进行两阶段的训练:
第一阶段使用特征蒸馏
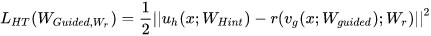
第二阶段使用soft target+hard target 知识蒸馏
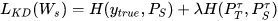
参考:
https://zhuanlan.zhihu.com/p/353472061
FITNETS:Hints for Thin Deep Nets
Knowledge-Distillation-Zoo
Comparing Kullback-Leibler Divergence and Mean Squared Error Loss
in Knowledge Distillation















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









