







QwQ-32B是一个强大的大语言模型,展示了令人印象深刻的推理能力。本指南将引导您通过vLLM在本地机器上部署和使用QwQ-32B,创建简单的API服务器,并构建Web界面进行交互。
QwQ-32B简介
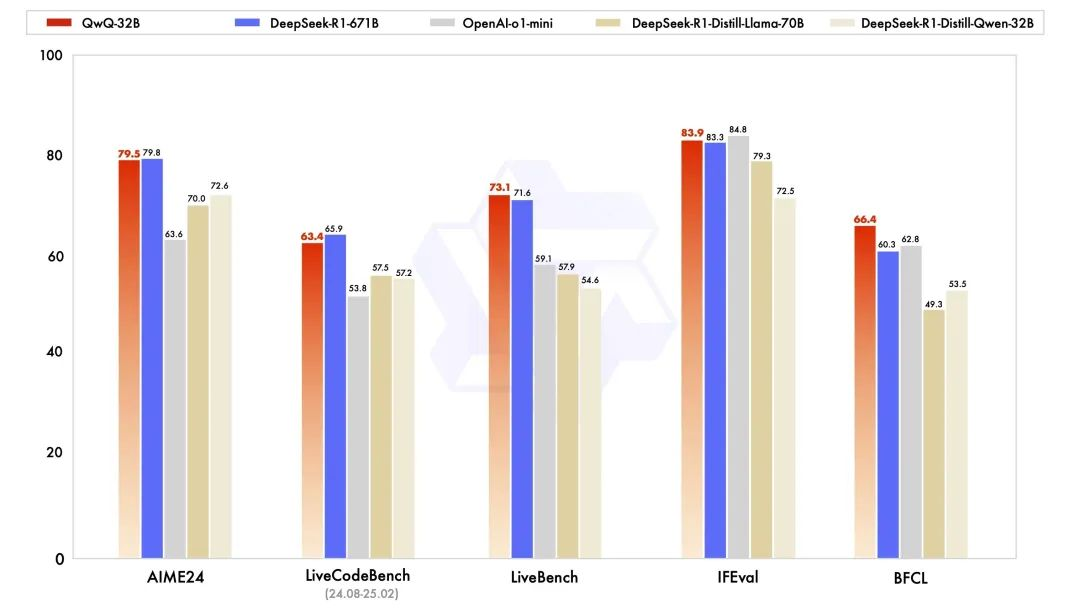
QwQ-32B是来自Qwen的一个320亿参数的推理模型,擅长复杂问题求解。根据原始材料中的用户反馈,它在以下方面表现出色:
- 数学推理
- 玩井字棋等游戏
- 利用推理能力解决复杂问题
- 生成具有真实物理模拟的代码
环境搭建
在开始之前,让我们设置环境。本指南假设您使用的是配备一张4090 GPU的AutoDL实例。
# 基础环境
# Ubuntu 22.04
# Python 3.12
# CUDA 12.1
# PyTorch 2.3.0
# 设置pip并安装依赖
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.22.3
pip install openai==1.61.0
pip install tqdm==4.67.1
pip install transformers==4.48.2
pip install vllm==0.7.1
pip install streamlit==1.41.1
下载模型(4位量化版本)
我们将使用ModelScope下载4位量化模型,以便在消费级GPU上高效推理:
# model_download.py
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/QwQ-32B-AWQ', cache_dir='/root/autodl-tmp', revision='master')运行下载脚本:
python model_download.py使用vLLM部署推理
vLLM为模型推理提供了出色的性能。让我们创建一个脚本来测试我们的模型:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











