







K倍交叉验证是对模型的性能进行评估,可以用来防止过拟合,比如对决策树节点数目的确定或是回归模型参数个数地决定等情况。
1.对于一些特殊数据来说,在调用glm()方法时候,会出现两种常见错误
Warning: glm.fit: algorithm did not converge
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning messages:
1: glm.fit:算法没有聚合
2: glm.fit:拟合機率算出来是数值零或一
针对第一种,一般是因为在回归拟合的时候次数少,control=list(maxit=100)修改次数为100即可;
第二种一般就是数据已经分散好了,可以理解为一种过拟合,由于数据的原因,在回归系数的优化搜索过程中,使得分类的种类属于某一种类(y=1)的线性拟合值趋于大,分类种类为另一 类(y=0)的线性拟合值趋于小。
以鸢尾花数据为例子,
这里写代码片
testdata$y <- c(1:80)
qplot(pl,y,data =testdata,colour =factor(species));
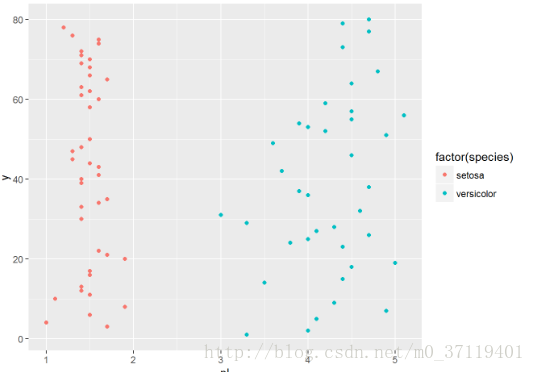
这种情况直接就
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















07-18
 2万+
2万+
2万+
11-02
2938
2938
08-11
2326
2326
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









