






问卷分析在整个研究中的占比和重要性很高,本文为大家梳理了常用的问卷分析框架,帮助大家有效收集和解读问卷数据。
一、初始问卷设计与预测试
通过一篇市调大赛的优秀论文《顾客为何不'粉'我---基于南京超级物种新零售模式的调查研究》,展示初始问卷大概包括哪些部分。
1、问卷标题与导语
这部分为受访者提供了调查的背景信息和目的,帮助他们理解参与的重要性,从而增强信任感,有效消除受访者的顾虑,使他们更愿意填写问卷。大概说明如下:
2、筛选题项
用于筛选符合研究条件的受访者。比如该调查样本需要是永辉超市的顾客,则设置以下筛选题进行后续样本筛选。
3、调查对象基本情况
这部分问题包括性别、年龄、受教育程度、婚恋状况、职业等人口统计学变量信息。
4、问卷主体部分
这是问卷的重要部分,包含用于测量主要研究变量的量表题项。使用量表对某个变量进行测量时,每个变量一般对应3~7个题目,不宜过少也不能过多。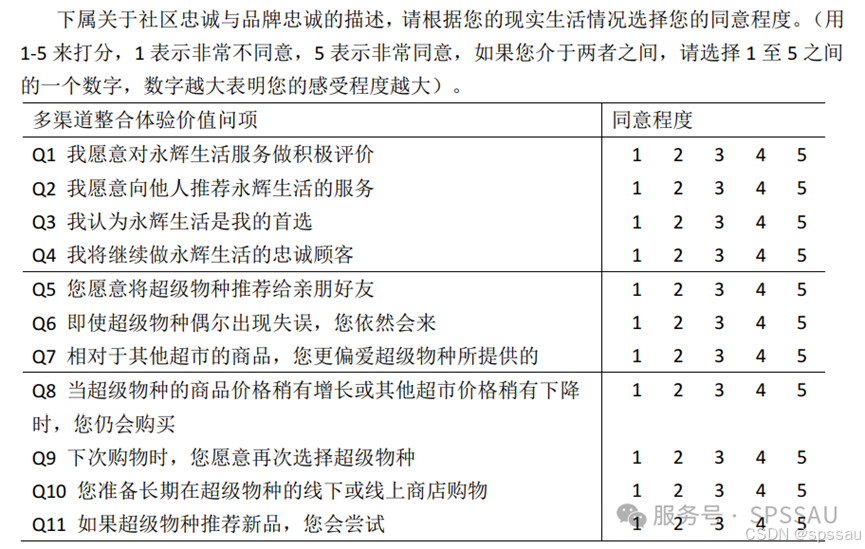
5、问卷预测试
为保证研究问卷质量,确保其能有效收集到需要的数据信息,一般会在目标人群的小样本中测试初步设计的问卷题项的适用性,收集反馈并进行必要的修改。
(1)信效度分析
- 信度分析:通过计算Cronbach's alpha值来评估量表的一致性。一般来说,alpha值大于0.7表示信度良好。
- 效度分析:通过内容效度、结构效度等方法评估问卷是否准确测量了所要研究的概念。
(2)问卷修改
- 根据预测试结果,对问卷进行必要的修订,包括:删除不必要或重复的问题、修改表达不清晰或引导性的问题、增加新的题目以补充遗漏的信息、调整问题顺序和选项设置等。
- 收集参与者/专家/导师的反馈,包括对问卷长度、题项的清晰度、题项歧义等。根据反馈对问卷进行修改,优化题项设计,提高问卷的质量。
二、正式问卷分析框架
问卷常用分析思路框架如下:
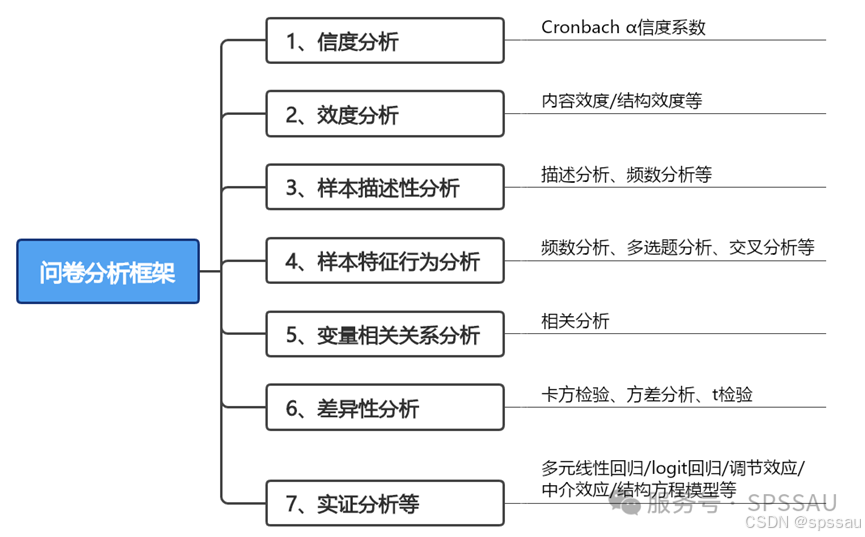
【提示】:以上列举的只是问卷分析中通用的一些分析方法,并不要求在每份问卷中使用所有分析方法或只局限于以上方法,研究者应根据具体情况,灵活选择适合自己问卷的分析方法。
1、信度分析
量表信度分析指测量结果的一致性或可靠性,用来验证测量样本回答的结果是否可靠以及可靠程度。常用的信度分析测量——克隆巴赫信度系数(Cronbach's α系数)。信度分析仅针对量表数据进行分析。
(1)信度系数评价标准

(2)SPSSAU软件操作
上传问卷数据至SPSSAU系统,在【问卷研究】模块选择【信度】,具体选择Cronbach α系数,操作如下图: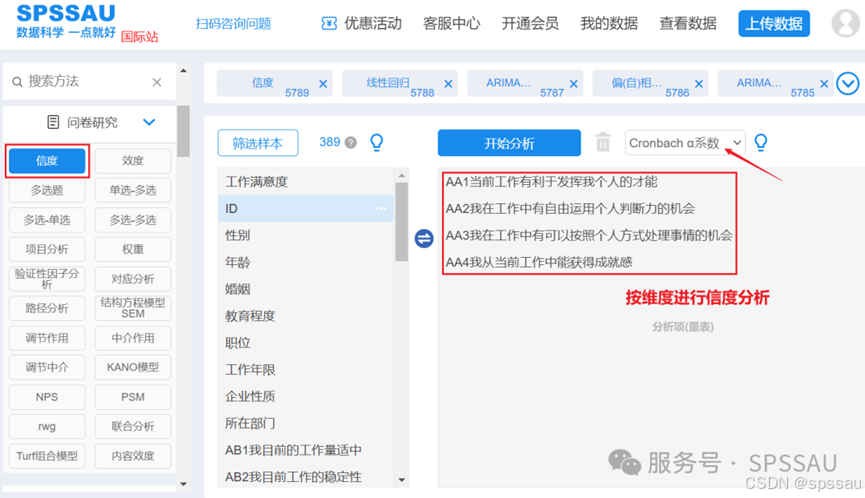
【提示】信度分析以维度为单位进行分析,最终需要将各维度α系数值进行汇总整理成表格输出。
(3)信度分析结果
SPSSAU输出Cronbach信度分析结果如下: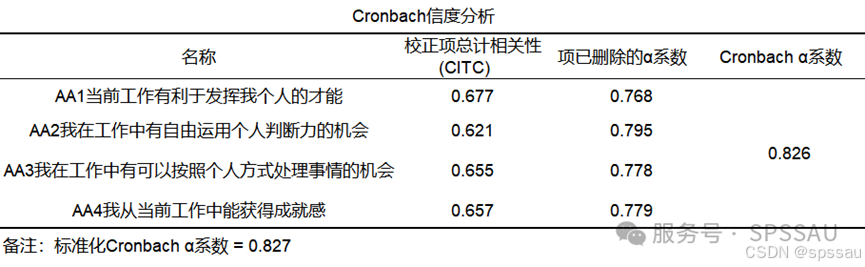
分析上表可知,该维度的Cronbach α系数为0.826,表明该维度的信度非常好。同样的操作将其他维度依次进行信度分析,最终整理成如下表格,汇报在论文中: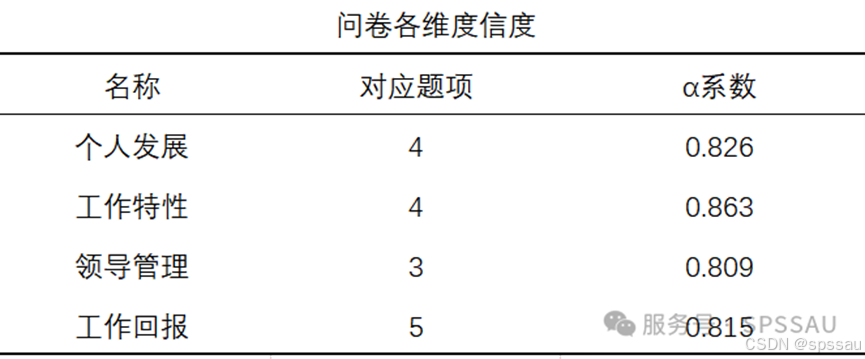
2、效度分析
信度达标后进行效度分析,效度主要评价量表的准确度、有效性,即量表是否真正反映了我们希望测量的东西,反映实际测量结果与预想结果的符合程度。
市场调查大赛中通常是进行结构效度分析(EFA),具体使用探索性因子分析进行研究。如果输出结果显示题项与变量对应关系基本与预期一致,则说明结构效度良好。
(1)结构效度评判标准
- KMO值大于0.6,且Bartlett 的检验p值小于0.05,适合进行因子分析。
- 旋转后累计方差解释率至少大于50%。
- 因子载荷系数大于0.4,因子与题项对应关系良好,不存在“张冠李戴”情况。
- 共同度(公因子方差)全部大于0.4
(2)SPSSAU软件操作
在【进阶方法】模块,选择【探索性因子分析】,将变量拖拽到右侧分析框中,设置因子个数,操作如下图: 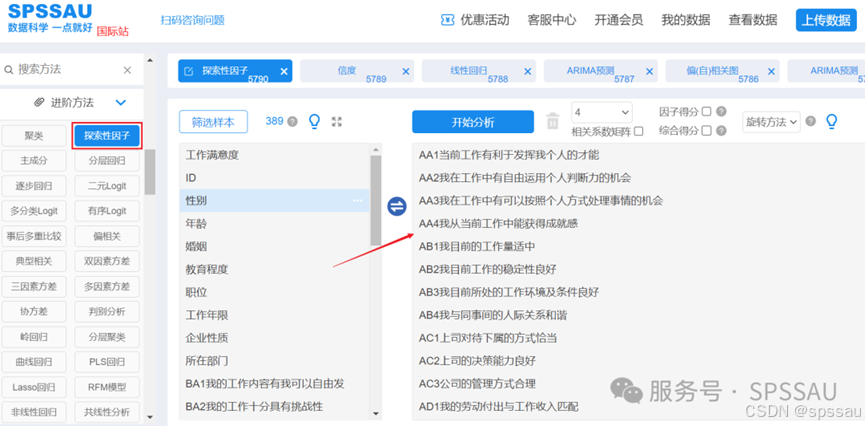
(3)效度分析结果

从上表可以看出:KMO为0.925,大于0.6,满足因子分析的前提要求,意味着数据可用于因子分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行因子分析。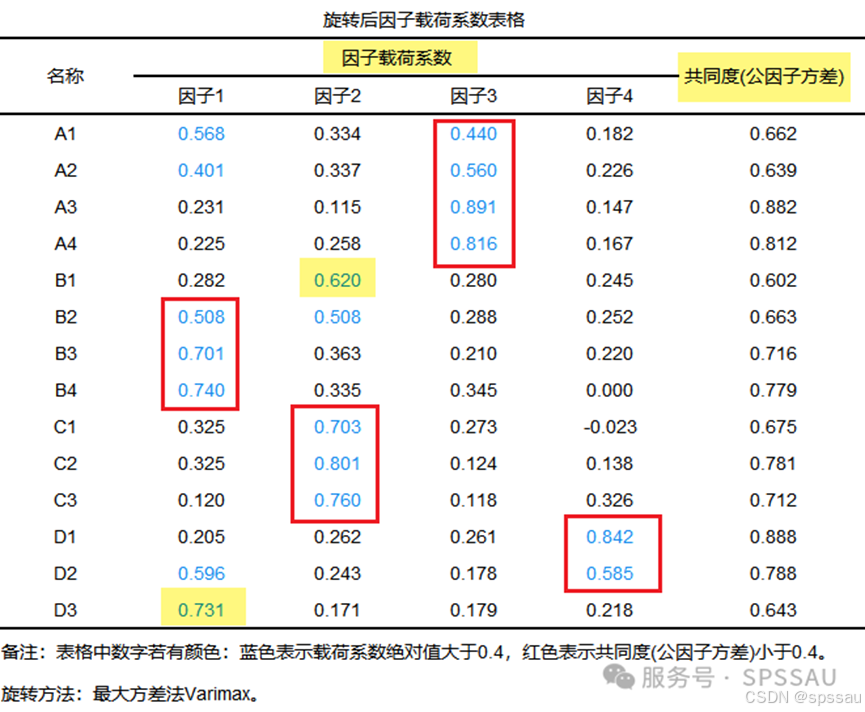
分析上表可知,变量B1和D3属于“张冠李戴”情况,比如理论上B1应该属于因子1,但却在因子2上载荷系数最大,D3变量分析类似;故可考虑将B1或D3删除后再次进行分析,直至题项与因子对应关系良好。
3、样本描述性分析
进行样本描述性分析,主要是为了了解和掌握样本的基本情况。通过报告样本分布情况,可以了解样本的年龄、性别、学历、职业等基本信息,从而对样本的结构和特点有初步的认识。
(1)SPSSAU软件操作
对人口统计学变量进行频数分析,操作如下图: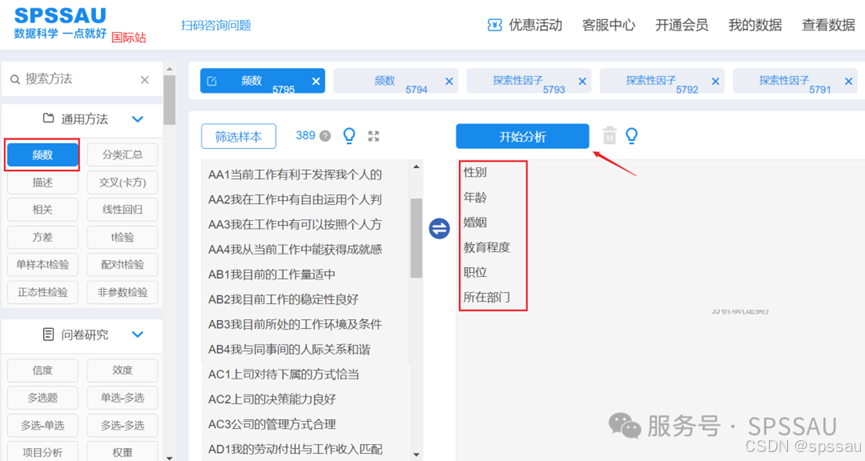
(2)频数分析结果
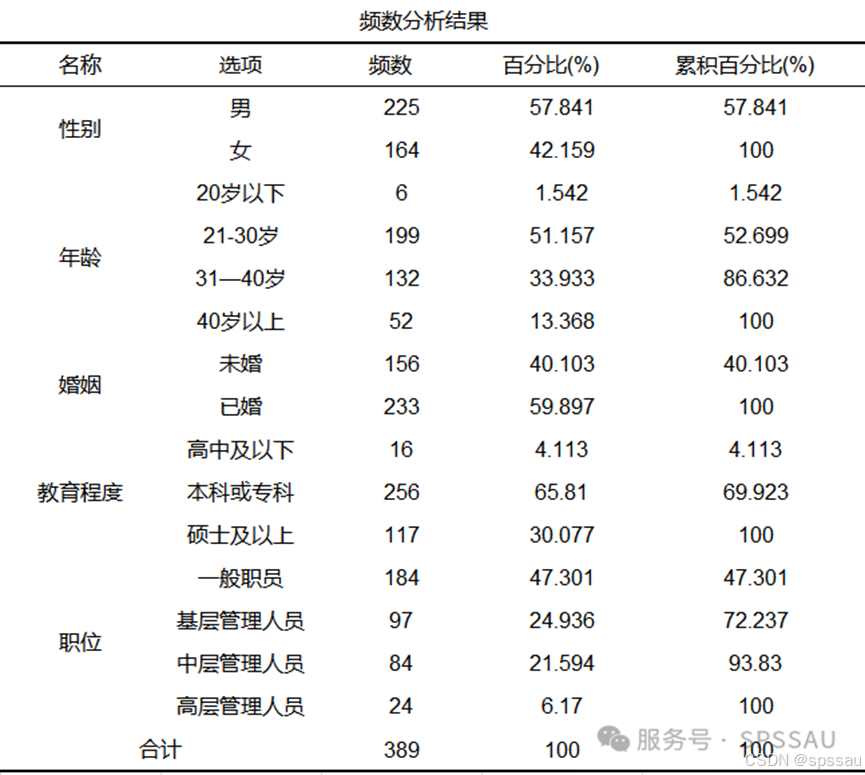
根据频数分析结果,发现本次调查样本中,男性占比57.84%,略多于女性的42.16%。年龄分布显示,21-30岁的年轻人群占比最高,达到51.15%,而40岁以上人群占比最低,仅为13.36%。在婚姻状况方面,已婚人群占据较大比例,达到59.89%。教育程度方面,本科或专科学历的受访者最多,占比65.81%。职位分布上,一般职员是主体,占比47.30%,而高层管理人员的比例最低,仅为6.17%。总体来看,样本呈现出年轻、已婚、中等教育程度和基层职位的特点。
4、样本特征行为分析
对量表各个维度进行描述统计,计算各个具体问题的最大值、最小值、平均值和标准差等。平均值代表被调查者对各项目满意程度看法。
 利用SPSSAU描述分析,可得到如下样本描述性分析结果:
利用SPSSAU描述分析,可得到如下样本描述性分析结果: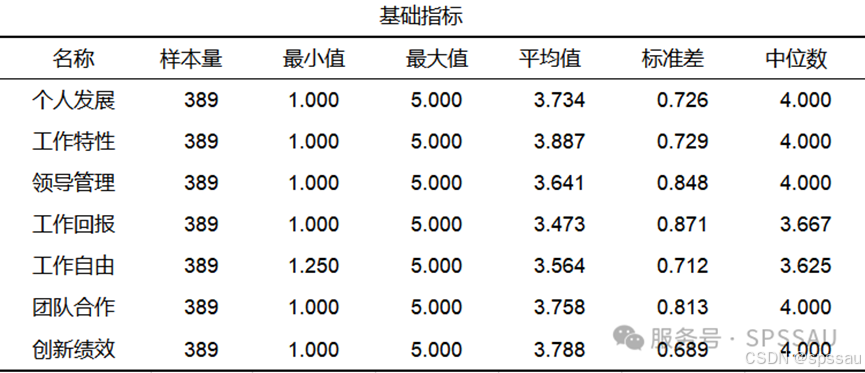
- 补充量表题维度合并
合并量表题项,使用平均值代表各个维度变量数据。量表的原始题目通常只用于分析信效度,其他如相关分析、差异性分析、描述分析、回归分析等均针对合并后的变量进行。SPSSAU对量表题项进行合并软件操作如下图:
5、变量相关关系分析
为了解变量之间的相关关系,可采用 Pearson 相关分析考察各变量的相关系数。利用SPSSAU相关分析,可得到如下变量相关分析结果: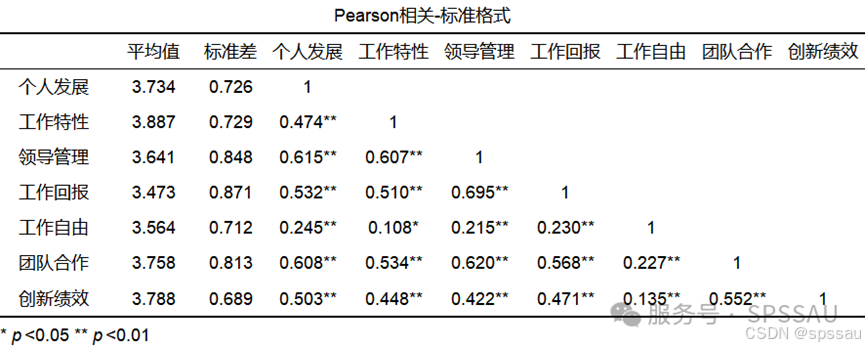
分析上表可知,个人发展与工作特性, 领导管理, 工作回报, 工作自由, 团队合作, 创新绩效之间全部均呈现出显著正相关关系(p值显著且相关系数大于0)。
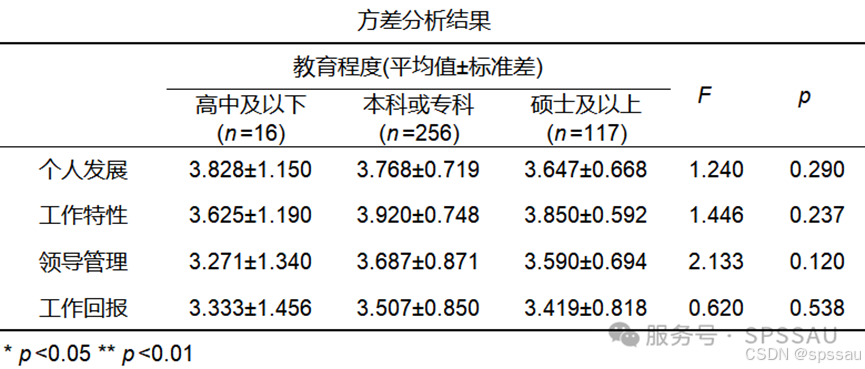
6、差异性分析
比较不同人口统计学变量在各个维度变量上的差异,即人口统计学变量差异性分析。利用SPSSAU独立样本t检验(二分类变量如性别)、单因素方差分析(多分类变量如学历、职业等),可得到差异性分析结果如下: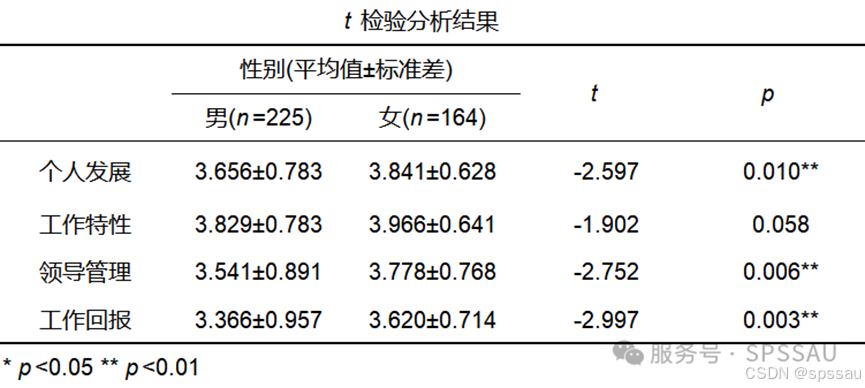
从t检验结果可知,在“个人发展”和“领导管理”“工作回报”三个变量上,男性和女性之间存在显著差异,其中女性的平均值均高于男性(p<0.01),而在“工作特性”这一变量上,尽管女性的平均值也略高于男性,但差异并不显著(p=0.058)。
(方差分析结果解读类似不再赘述)
7、实证分析等
基础分析完毕后,后面就需要根据自己的研究目的进行关键的实证分析。问卷常用的影响因素研究方法比如进行多元线性回归、logistic回归、调节效应、中介效应、结构方程模型等。
(1)结构方程模型
结构方程模型SEM包括测量关系和影响关系,可用于研究多个潜变量之间的关系情况。结构方程模型与路径分析主要区别就在于完整的结构方程模型包含了测量关系和影响关系,而路径分析仅包括影响关系。
例如:研究感知质量和感知价值对顾客满意的影响关系,顾客满意对顾客忠诚的影响关系,预期模型如下图: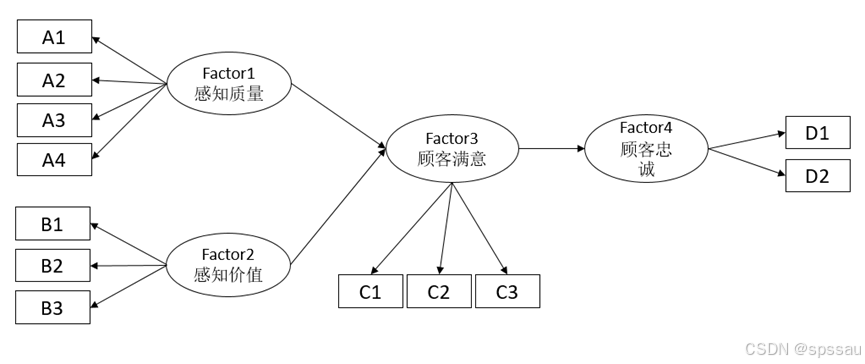
(2)SPSSAU软件操作
- 测量模型用于描述观测变量与潜变量之间的关系,在本案例中,A1~A4拖拽到Factor1,B1~B3拖拽到Factor2,C1~C3拖拽到Factor3,D1~D2拖拽到Factor4;
- 结构模型用于描述潜变量之间的关系,在本案例中“感知质量”和“感知价值”对于“顾客满意”产生影响关系;“顾客满意”对“顾客忠诚”产生影响关系,可以通过右侧“+,-”按钮增加或减少模型关系,以及点击选择影响关系或者相关关系,操作如下图:
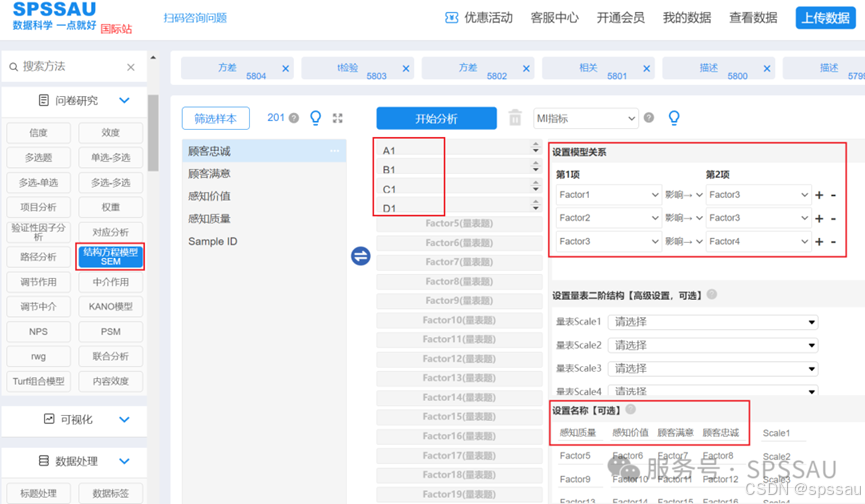
(3)结构方程模型结果
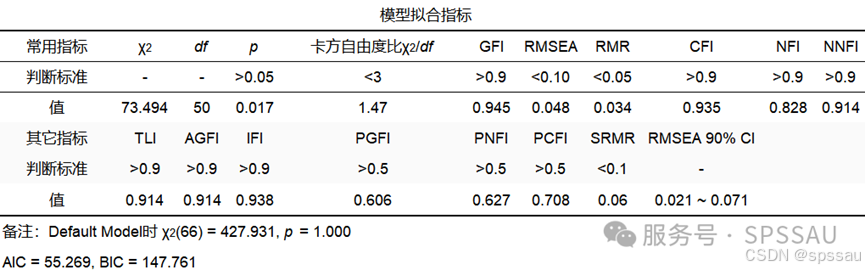
(结构方程模型部分结果)
分析上表模型拟合指标可知,卡方自由度比(𝜒2/𝑑𝑓)为1.47,小于建议的标准值3,表明模型与数据的拟合情况良好。GFI、CFI、NFI和NNFI等指数均大于0.9,进一步支持了模型的优良拟合性。RMSEA值为0.048,远低于临界值0.05,也表明模型具有较好的近似误差,其他指标解读类似。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









