






卷友们好,我是rumor。
前段时间分享过开放域问答的研究进展,虽然这些榜单的分数都在不断提升,但真要提到应用的话,实验室产品和工业级产品还是有很大差距的。我在公众号后台放了一个机器人,基本90%以上的同学都是两轮内识破,虽然每单句话拿出来都还行,但放到上下文里就显得很突兀。
那怎么样才能做一个真正的、应用级别的对话系统呢?现在大模型效果这么好,能否帮助我们告别繁琐的pipeline,实现端到端问答呢?
看了最近谷歌放出的LaMDA方案,我觉得稍微有点那么个意思了。
在最近两年的谷歌大会上,都有对话技术上的迭代,前年是当场跟Google Assistant打了个电话、推出了Meena,去年是推出了LaMDA模型,展示了一段关于冥王星的知识型对话,直到最近才放出具体论文。
LaMDA: Language Models for Dialog Applications
https://arxiv.org/abs/2201.08239
工业级的对话产品?
要打造实际能用的对话产品,我们的思维就要先转换一下:
不再是我要用什么方法解决这个问题,而是:我要解决什么问题?
这跟我们做模型的思路是一样的,先把objective定好,然后只要用差不多的网络结构去拟合就完了。在实际落地时更要定好这个目标,而现在的一些benchmark和对话系统,评估维度都太单一了,大部分问答里都是准确率/F1这种,直接忽略掉机器人的人性化部分。
要往更智能的对话系统走,首先要想清楚怎么样才算是「智能的对话系统」,我们还差在哪里。
(翻回去看了18年小冰的论文,发现它对机器人EQ、IQ、Personality的定义也很多维度,只可惜当时的我太年轻眼里只有复杂的模型,希望看到这篇文章的同学能意识到这个问题)
再去看谷歌的Meena和LaMDA,前面很大一部分篇幅都在讲评估指标的定义,分为三个维度:
Sensibleness, Specificity, Interestingness:是否合理、符合上下文、有创造力
Safety:是否有风险、不公正
Groundedness、Informativeness:在知识型问答中,是否包含真实的信息、并引用相关链接
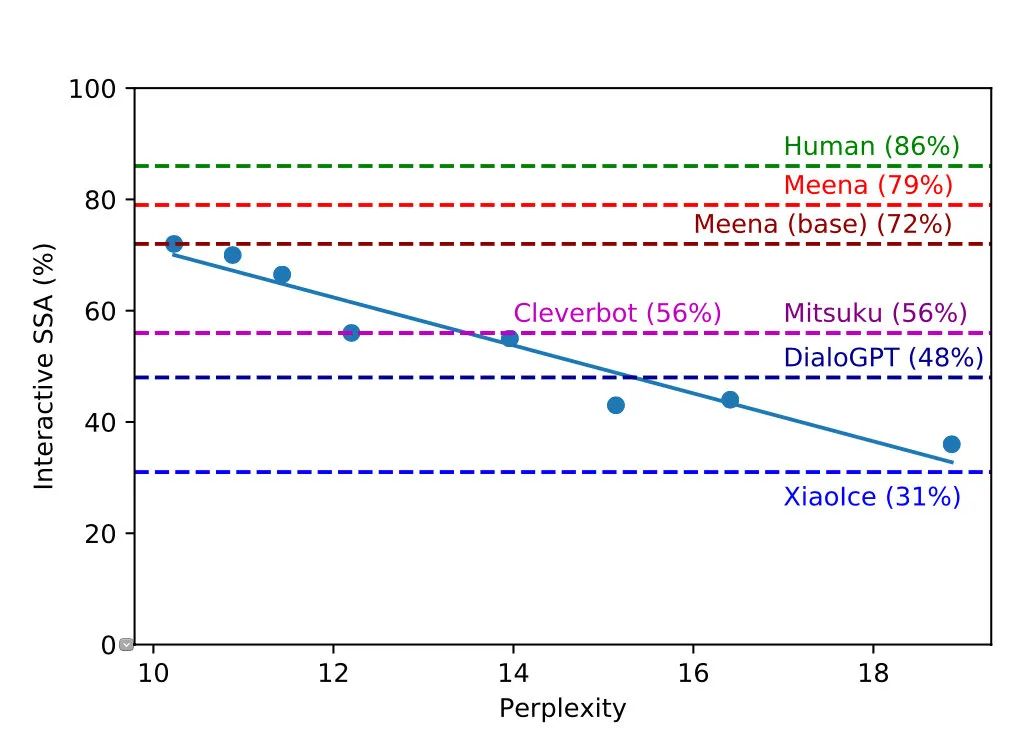
定义完指标后,第二步是评估一下baseline和天花板,看到差距在哪里,从Meena的评估结果来看,各个机器人比起人类还是相差甚远:
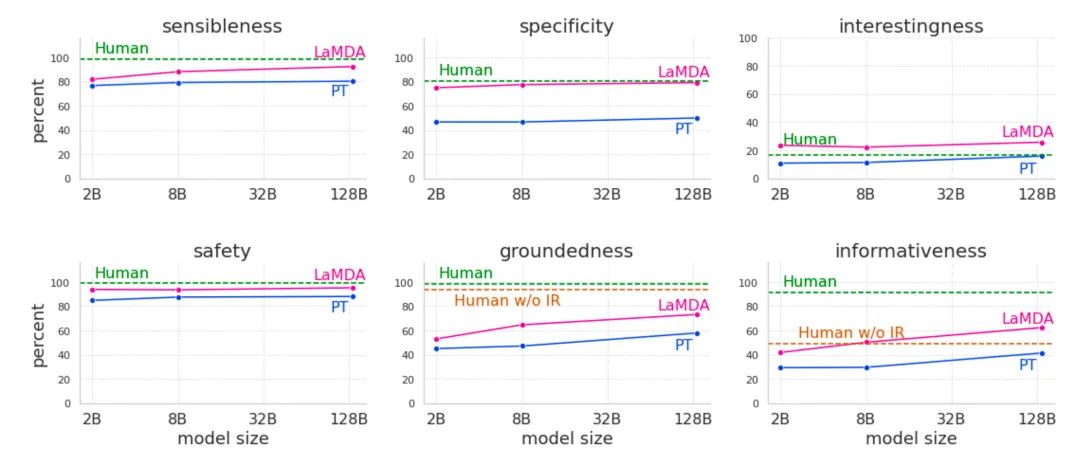
LaMDA的结果:
差这么多怎么办?没事,最难的问题定义已经搞完了,剩下的标数据就完了!
在优化过程中,谷歌并没有用什么高端的技术,只是把Sensibleness、Specificity、Interestingness、Safety分别当成分类任务去标0/1,把知识问答当作生成任务让标注同学去编辑答案,然后精调就完了。可以看到精调之后的LaMDA比纯在对话数据上预训练的PT有提升了不少。
对话+大模型+知识?
除了上面提到的指标定义外,LaMDA还可以给我们一些小启示,就是怎么更好地在对话任务中利用大模型。
首先是模型的选型,LaMDA用的是纯自回归预训练,这里我还是有些疑惑的,因为Meena用的是Seq2Seq结构(虽然不是相同的作者),作者也没有明说原因,但我认为模型结构的选择还是很重要的,T5和GPT还是有些diff的。
第二点,是个比较巧妙的地方。在业界目前的对话系统中,都是跟搜索一样召回+排序的逻辑,这就需要两个模型。而LaMDA做到了单模型同时生成+排序,而且由于语言模型的任务形式,这个排序分数是直接在生成结果后面加prompt完成的。也就是生成完结果的最后一个字后,直接继续预测分数,一气呵成。
从输入上看就是:<context> <sentinel> <response> <attribute-name> <rating>
第三点,也是LaMDA在Meena上的大改进:融入知识。作者们为了让大模型学会答知识类问题,设计了两个任务:
输入对话上下文,输出知识查询语句:这个查询语句是主要是
TS, Query的形式,作者开发了一套检索系统用来囊括各类知识输入知识查询语句,输出生成的最终结果:通过标注同学编辑的文本进行精调,让模型学会整合知识
经过上述两个任务的训练,模型就会判断什么时候该去查询数据知识,并且返回整合的结果了:

总结
总结来说,LaMDA的文章虽然在技术上没什么新突破,但却给我们提供了很有价值的落地方案参考:
首先指标一定要定义清楚,然后向着指标优化就完了
如何用单个大模型实现整个端到端的问答
纯粹依靠模型记忆知识是不行的,知识型问答还需要其他系统辅助
以上就是我的收获了,希望同学们不光只关注纯技术,也多往应用方便去思考,毕竟技术的价值最终还是体现在应用上。
话不多说,我去看「开端」大结局了。

欢迎对NLP感兴趣的朋友加入我们的「NLP卷王养成」群,一起学习讨论~
扫码添加微信备注「NLP」即可⬇️


大家好我是rumor
一个热爱技术,有一点点幽默的妹子
欢迎关注我
带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「快上车!」

















 164
164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









