






# 昨日知识点回顾
使用API请求调用GitHub数据
# 今日知识点学习
17.2 使用Plotly可视化仓库
import requests
from plotly.graph_objs import Bar
from plotly import offline
# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code:{r.status_code}")
# 处理结果
response_dict = r.json()
repo_dicts = response_dict['items']
repo_names, stars = [], []
for repo_dict in repo_dicts:
repo_names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
# 可视化
data = [{
'type': 'bar',
'x':repo_names,
'y':stars,
}]
my_layout = {
'title':'GitHub上最受欢迎的Python项目',
'xaxis':{'title': 'Repository'},
'yaxis':{'title': 'Stars'},
}
print(f"Repositories returned:{len(repo_dicts)}")
fig = {'data':data, 'layout':my_layout}
offline.plot(fig, filename='python_repos.html')
# 运行结果:
# Status code:200
# Repositories returned:30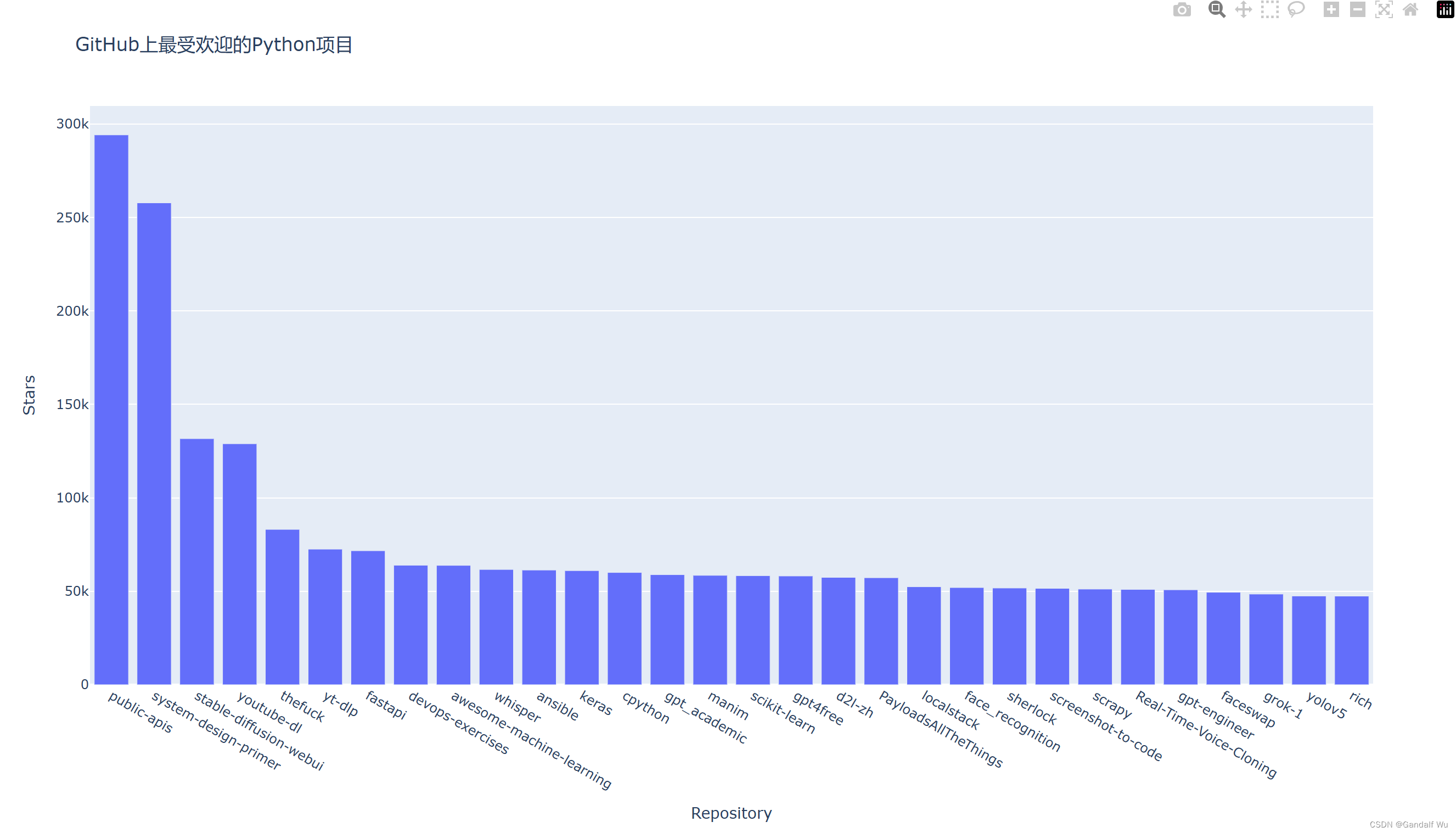
17.2.1 改进Plotly图表
import requests
from plotly.graph_objs import Bar
from plotly import offline
# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code:{r.status_code}")
# 处理结果
response_dict = r.json()
repo_dicts = response_dict['items']
repo_names, stars = [], []
for repo_dict in repo_dicts:
repo_names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
# 可视化
data = [{
'type': 'bar',
'x': repo_names,
'y': stars,
'marker': {
'color': 'rgb(60, 100, 150)',
'line': {'width': 1.5, 'color': 'rgb(25, 25, 25)'}
},
'opacity': 0.6,
}]
my_layout = {
'title': 'GitHub上最受欢迎的Python项目',
'titlefont': {'size': 28},
'xaxis': {
'title': 'Repository',
'titlefont': {'size': 24},
'tickfont': {'size': 14}
},
'yaxis': {
'title': 'Stars',
'titlefont': {'size': 24},
'tickfont': {'size': 14}
},
}
print(f"Repositories returned:{len(repo_dicts)}")
fig = {'data': data, 'layout': my_layout}
offline.plot(fig, filename='python_repos.html')
# 运行结果:
# Status code:200
# Repositories returned:30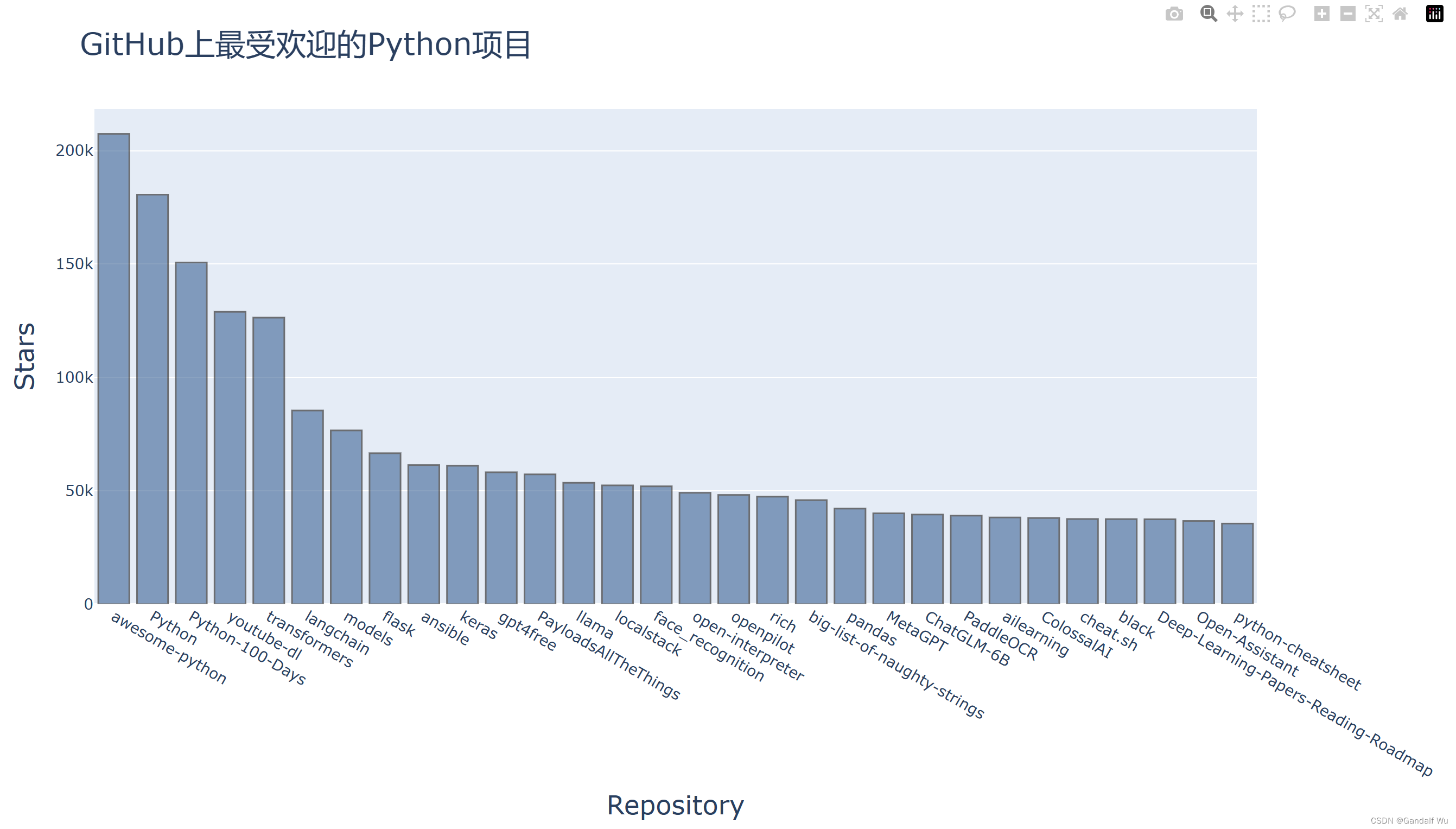
17.2.2 添加自定义工具提示
import requests
from plotly.graph_objs import Bar
from plotly import offline
# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code:{r.status_code}")
# 处理结果
response_dict = r.json()
repo_dicts = response_dict['items']
repo_names, stars, labels = [], [], []
for repo_dict in repo_dicts:
repo_names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
owner = repo_dict['owner']['login']
description = repo_dict['description']
# <br />换行符
label = f"{owner}<br />{description}"
labels.append(label)
# 可视化
data = [{
'type': 'bar',
'x': repo_names,
'y': stars,
'hovertext': labels,
'marker': {
'color': 'rgb(60, 100, 150)',
'line': {'width': 1.5, 'color': 'rgb(25, 25, 25)'}
},
'opacity': 0.6,
}]
my_layout = {
'title': 'GitHub上最受欢迎的Python项目',
'titlefont': {'size': 28},
'xaxis': {
'title': 'Repository',
'titlefont': {'size': 24},
'tickfont': {'size': 14}
},
'yaxis': {
'title': 'Stars',
'titlefont': {'size': 24},
'tickfont': {'size': 14}
},
}
print(f"Repositories returned:{len(repo_dicts)}")
fig = {'data': data, 'layout': my_layout}
offline.plot(fig, filename='python_repos.html')
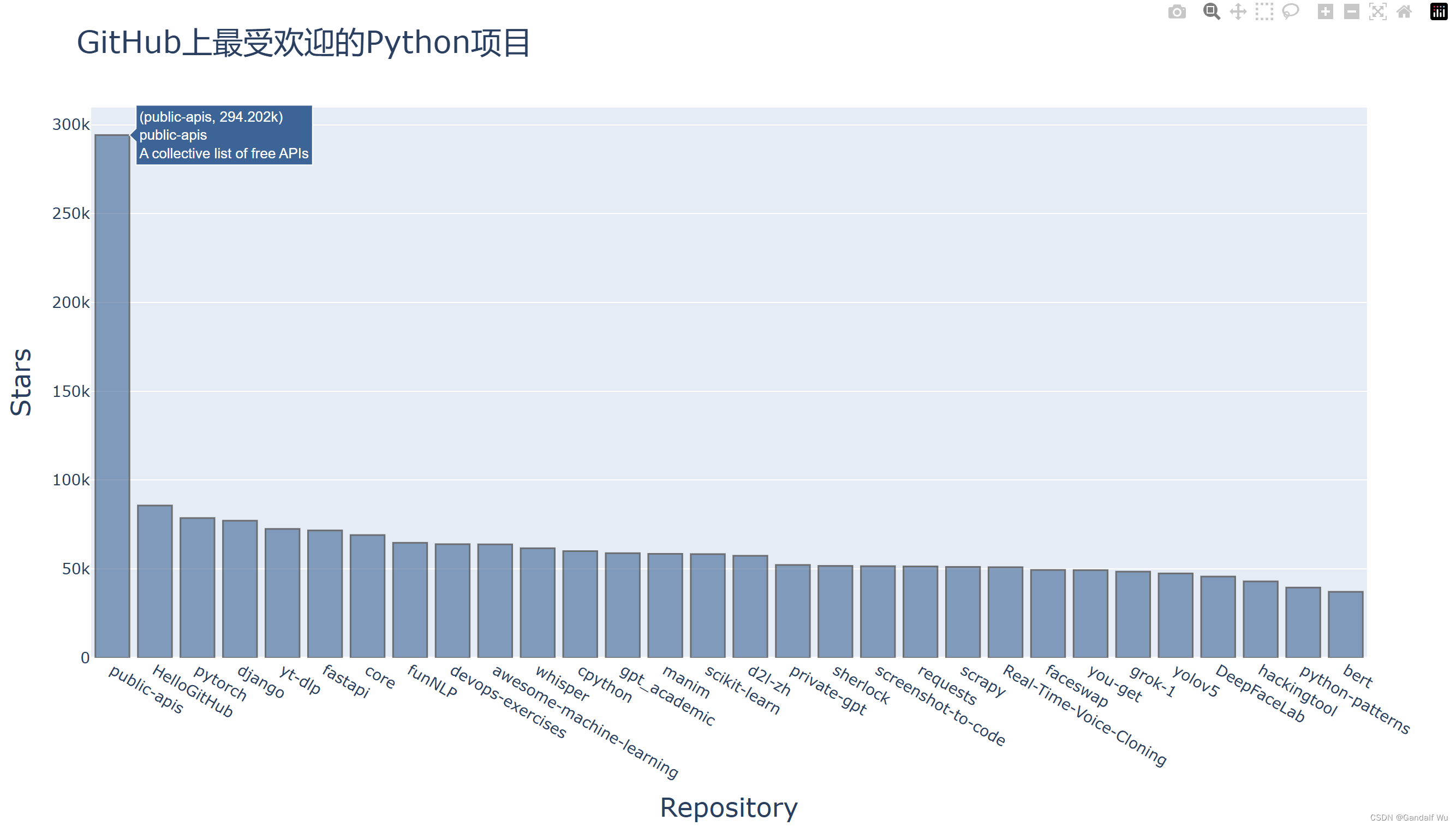
# 运行结果:
# Status code:200
# Repositories returned:30
17.2.3 在图表中添加可单击的链接
import requests
from plotly.graph_objs import Bar
from plotly import offline
# 执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
headers = {'Accept': 'application/vnd.github.v3+json'}
r = requests.get(url, headers=headers)
print(f"Status code:{r.status_code}")
# 处理结果
response_dict = r.json()
repo_dicts = response_dict['items']
repo_links, stars, labels = [], [], []
for repo_dict in repo_dicts:
repo_name = repo_dict['name']
repo_url = repo_dict['html_url']
repo_link = f"<a href = '{repo_url}'>{repo_name}</a>"
repo_links.append(repo_link)
stars.append(repo_dict['stargazers_count'])
owner = repo_dict['owner']['login']
description = repo_dict['description']
# <br />换行符
label = f"{owner}<br />{description}"
labels.append(label)
# 可视化
data = [{
'type': 'bar',
'x': repo_links,
'y': stars,
'hovertext': labels,
'marker': {
'color': 'rgb(60, 100, 150)',
'line': {'width': 1.5, 'color': 'rgb(25, 25, 25)'}
},
'opacity': 0.6,
}]
my_layout = {
'title': 'GitHub上最受欢迎的Python项目',
'titlefont': {'size': 28},
'xaxis': {
'title': 'Repository',
'titlefont': {'size': 24},
'tickfont': {'size': 14}
},
'yaxis': {
'title': 'Stars',
'titlefont': {'size': 24},
'tickfont': {'size': 14}
},
}
print(f"Repositories returned:{len(repo_dicts)}")
fig = {'data': data, 'layout': my_layout}
offline.plot(fig, filename='python_repos.html')
# 运行结果:
# Status code:200
# Repositories returned:30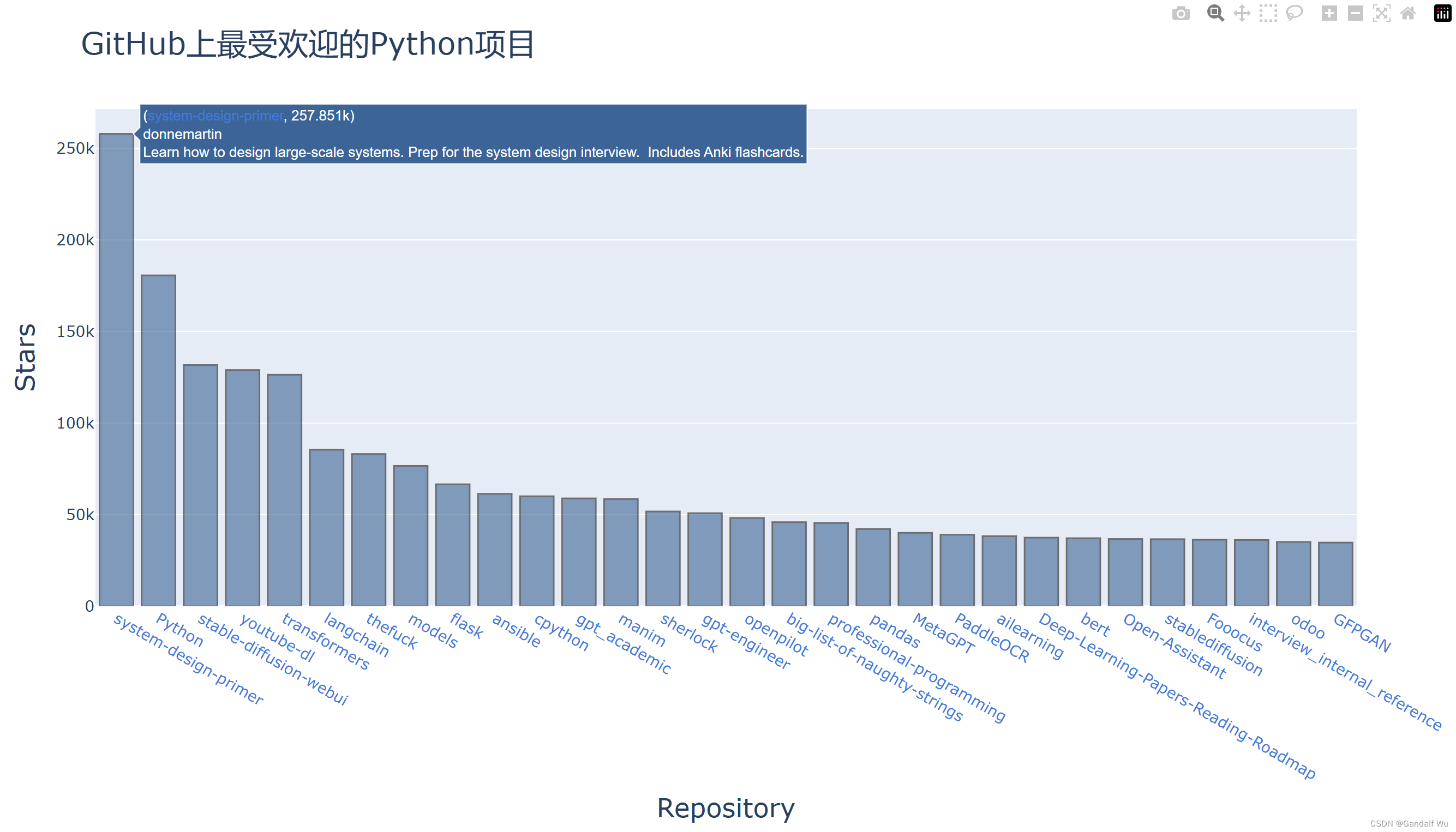
17.2.4 深入了解Plotly和GitHub API
深入了解如何生成Plotly图表:①Plotly User Guide in Python;②Plotly网站中的Python Figure Reference
深入了解 GitHub API:参阅官方文档
17.3 Hacker News API
浏览器地址栏输入:https://hacker-news.firebaseio.com/vo/item/19155826.json
# 没有访问权限
{
"error": "Permission denied"
}浏览器地址栏输入:https://hacker-news.firebaseio.com/v0/item/8863.json?print=pretty
{
"by": "dhouston",
"descendants": 71,
"id": 8863,
"kids": [
9224,
8917,
8884,
8887,
8952,
8869,
8873,
8958,
8940,
8908,
9005,
9671,
9067,
9055,
8865,
8881,
8872,
8955,
10403,
8903,
8928,
9125,
8998,
8901,
8902,
8907,
8894,
8870,
8878,
8980,
8934,
8943,
8876
],
"score": 104,
"time": 1175714200,
"title": "My YC app: Dropbox - Throw away your USB drive",
"type": "story",
"url": "http://www.getdropbox.com/u/2/screencast.html"
}import requests
import json
# 执行API调用并存储响应
# url = 'https://hacker-news.firebaseio.com/v0/item/8863.json?print=pretty'
url = 'https://hacker-news.firebaseio.com/vo/item/19155826.json'
r = requests.get(url)
print(f"Status code: {r.status_code}")
# 探索数据的结构
response_dict = r.json()
readable_file = 'data/readable_hn_data.json'
with open(readable_file, 'w') as f:
json.dump(response_dict, f, indent=4)
# 运行结果:
# Status code: 401
# readable_hn_data.json
{
"by": "jimktrains2",
"descendants": 221,
"id": 19155826,
"kids": [
19156572,
19158857,
19156773,
19157251,
19156415,
19159820,
19157154,
19156385,
19156489,
19158522,
19156755,
19156974,
19158319,
19157034,
19156935,
19158935,
19157531,
19158638,
19156466,
19156758,
19156565,
19156498,
19156335,
19156041,
19156704,
19159047,
19159127,
19156217,
19156375,
19157945
],
"score": 728,
"time": 1550085414,
"title": "Nasa\u2019s Mars Rover Opportunity Concludes a 15-Year Mission",
"type": "story",
"url": "https://www.nytimes.com/2019/02/13/science/mars-opportunity-rover-dead.html"
}# Hacker News上当前排名靠前文章ID
浏览器地址栏输入:ttps://hacker-news.firebaseio.com/v0/topstories.jsonfrom operator import itemgetter
import requests
# 执行API调用并存储响应
url = 'https://hacker-news.firebaseio.com/v0/topstories.json'
r = requests.get(url)
print(f"Status code: {r.status_code}")
# 处理每篇文章的信息
submission_ids = r.json()
submission_dicts = []
for submission_id in submission_ids[:30]:
# 对于每篇文章,都执行一个API调用
url = f"https://hacker-news.firebaseio.com/v0/item/{submission_id}.json"
r = requests.get(url)
print(f"id:{submission_id}\tstatus:{r.status_code}")
response_dict = r.json()
# 对于每篇文章创建一个字典
try:
submission_dict = {
'title': response_dict['title'],
'hn_link': f"https://news.ycombinator.com/item?id={submission_id}",
'comments': response_dict['descendants'],
}
submission_dicts.append(submission_dict)
except KeyError:
pass
submission_dicts = sorted(submission_dicts, key=itemgetter('comments'), reverse=True)
for submission_dict in submission_dicts:
print(f"\nTitle:{submission_dict['title']}")
print(f"Discussion link:{submission_dict['hn_link']}")
print(f"Comments:{submission_dict['comments']}")
# 运行结果:
# Status code: 200
# id:40426995 status:200
# id:40424304 status:200
# id:40426442 status:200
# id:40426382 status:200
# id:40406481 status:200
# id:40425905 status:200
# id:40424536 status:200
# id:40427195 status:200
# id:40404752 status:200
# id:40422940 status:200
# id:40426621 status:200
# id:40416109 status:200
# id:40419856 status:200
# id:40426099 status:200
# id:40425504 status:200
# id:40390941 status:200
# id:40394307 status:200
# id:40423082 status:200
# id:40419325 status:200
# id:40417347 status:200
# id:40396373 status:200
# id:40422997 status:200
# id:40395467 status:200
# id:40395105 status:200
# id:40418591 status:200
# id:40385562 status:200
# id:40426701 status:200
# id:40413869 status:200
# id:40426622 status:200
# id:40426894 status:200
#
# Title:Enlightenmentware
# Discussion link:https://news.ycombinator.com/item?id=40419856
# Comments:182
#
# Title:Rethinking Text Resizing on Web
# Discussion link:https://news.ycombinator.com/item?id=40418591
# Comments:147
#
# Title:Sierra was captured, then killed, by an accounting fraud (2020)
# Discussion link:https://news.ycombinator.com/item?id=40395105
# Comments:129
#
# Title:Going Dark: The war on encryption is on the rise
# Discussion link:https://news.ycombinator.com/item?id=40426701
# Comments:88
#
# Title:Shipbreaking
# Discussion link:https://news.ycombinator.com/item?id=40424304
# Comments:78
#
# Title:NoTunes is a macOS application that will prevent Apple Music from launching
# Discussion link:https://news.ycombinator.com/item?id=40426621
# Comments:68
#
# Title:pg_timeseries: Open-source time-series extension for PostgreSQL
# Discussion link:https://news.ycombinator.com/item?id=40417347
# Comments:58
#
# Title:The Reign of Alexander III of Macedon, the Great?
# Discussion link:https://news.ycombinator.com/item?id=40395467
# Comments:51
#
# Title:Bento3D
# Discussion link:https://news.ycombinator.com/item?id=40422940
# Comments:50
#
# Title:Chameleon: Meta's New Multi-Modal LLM
# Discussion link:https://news.ycombinator.com/item?id=40423082
# Comments:30
#
# Title:Building an AI game studio: what we've learned so far
# Discussion link:https://news.ycombinator.com/item?id=40426382
# Comments:23
#
# Title:An Ode to Deluxe Paint (2023)
# Discussion link:https://news.ycombinator.com/item?id=40406481
# Comments:23
#
# Title:How Might We Learn?
# Discussion link:https://news.ycombinator.com/item?id=40424536
# Comments:21
#
# Title:Regular expression matching can be simple and fast (2007)
# Discussion link:https://news.ycombinator.com/item?id=40422997
# Comments:21
#
# Title:City in a Bottle – A 256 Byte Raycasting System
# Discussion link:https://news.ycombinator.com/item?id=40416109
# Comments:18
#
# Title:How terminal works. Part 1: Xterm, user input (2021)
# Discussion link:https://news.ycombinator.com/item?id=40419325
# Comments:14
#
# Title:The Vietnamese Computer Scientist Who Made Toy Story Possible
# Discussion link:https://news.ycombinator.com/item?id=40390941
# Comments:11
#
# Title:We created the first open source implementation of Meta's TestGen–LLM
# Discussion link:https://news.ycombinator.com/item?id=40426995
# Comments:9
#
# Title:Gifski: Optimized GIF Encoder
# Discussion link:https://news.ycombinator.com/item?id=40426442
# Comments:9
#
# Title:When you're driving you're re-enacting an ancient space combat SIM
# Discussion link:https://news.ycombinator.com/item?id=40394307
# Comments:9
#
# Title:Formatted spreadsheets can still work in R
# Discussion link:https://news.ycombinator.com/item?id=40385562
# Comments:9
#
# Title:Waxolotl – A small language that compiles to WebAssembly text format
# Discussion link:https://news.ycombinator.com/item?id=40404752
# Comments:6
#
# Title:Reversing Choplifter
# Discussion link:https://news.ycombinator.com/item?id=40425905
# Comments:3
#
# Title:Show HN: Oracolo – A minimalist Nostr blog in a single HTML file
# Discussion link:https://news.ycombinator.com/item?id=40426099
# Comments:2
#
# Title:AI Needs Enormous Computing Power. Could Light-Based Chips Help?
# Discussion link:https://news.ycombinator.com/item?id=40425504
# Comments:2
#
# Title:Eudyptula Challenge (2014)
# Discussion link:https://news.ycombinator.com/item?id=40413869
# Comments:2
#
# Title:A fire 2,200 years ago preserved moment in Iron Age, down to a gold earring
# Discussion link:https://news.ycombinator.com/item?id=40396373
# Comments:0
#
# Title:Humans Who Are Not Concentrating Are Not General Intelligences (2019)
# Discussion link:https://news.ycombinator.com/item?id=40426622
# Comments:0
#
# Title:the engineerguy: The Engineering of Duct Tape [video]
# Discussion link:https://news.ycombinator.com/item?id=40426894
# Comments:0














 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









