









GB2312
收集了 7445 个字符组成 94 * 94 的方阵,每一行称为一个“区”,每一列称为一个“位”,区号位号的范围均为 01-94,区号和位号组成的代码称为“区位码”。将区号和位号分别加上 20H,得到的 4 位十六进制整数称为国标码,编码范围为 0x2121~0x7E7E。给国标码的每个字节加 80H,形成的编码称为机内码,是汉字在机器中实际的存储代码。GB2312-80 标准的内码范围是 0xA1A1~0xFEFE。
GBK
GBK编码是对GB2312编码的扩展,因此完全兼容GB2312-80标准。其编码范围:8140-FEFE,共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。GBK编码支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。
UNICODE
为了世界大统一,就出现了Unicode万国码,此方案的字符编号兼容ASCII编码,在Unicode中规定了中文范围为4E00-9FA5。 Unicode 字符集的编码范围是 0x0000 - 0x10FFFF。
UNICODE字符编码官网
UTF8
Unicode 出现了多种存储方式,常见的有 UTF-8、UTF-16、UTF-32,它们分别用不同的二进制格式来表示 Unicode 字符
UTF-8、UTF-16、UTF-32 中的 “UTF” 是 “Unicode Transformation Format” 的缩写,意思是"Unicode 转换格式"。
UTF-8 的编码规则:
1 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2 对于 n 字节的符号( n > 1),第一个字节的前 n 位都设为 1,第 n + 1 位设为 0,后面字节的前两位一律设为 10 。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
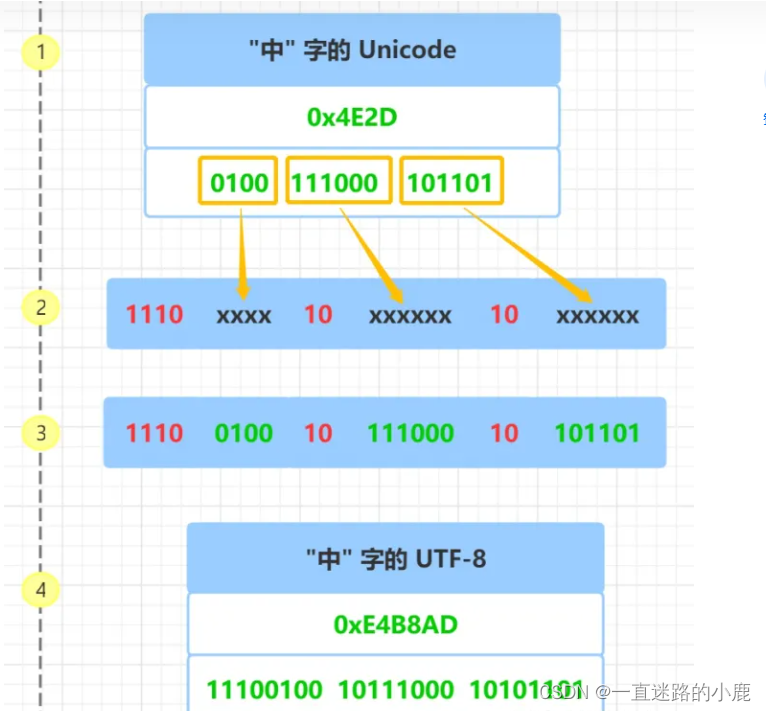
利用操作系统的api实现UTF8转码:
#include <windows.h>
unsigned char * Utf8ToGBK(unsigned char *strUtf8)
{
int len=MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)strUtf8, -1, NULL,0);
wchar_t * wszGBK = new wchar_t[len];
memset(wszGBK,0,len);
MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)strUtf8, -1, wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
char *szGBK=new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte (CP_ACP, 0, wszGBK, -1, szGBK, len, NULL,NULL);
delete[] wszGBK;
return (unsigned char*)szGBK;
}
unsigned char * GBKToUtf8(unsigned char * strGBK)
{
int len=MultiByteToWideChar(CP_ACP, 0, (LPCSTR)strGBK, -1, NULL,0);
wchar_t * wszUtf8 = new wchar_t [len];
memset(wszUtf8, 0, len);
len = MultiByteToWideChar(CP_ACP, 0, (LPCSTR)strGBK, -1, wszUtf8, len);
len = WideCharToMultiByte(CP_UTF8, 0, wszUtf8, -1, NULL, 0, NULL, NULL);
char *szUtf8=new char[len + 1];
memset(szUtf8, 0, len + 1);
WideCharToMultiByte (CP_UTF8, 0, wszUtf8, -1, szUtf8, len, NULL,NULL);
delete[] wszUtf8;
return (unsigned char*)szUtf8;
}
UTF-16
编码规则如下:
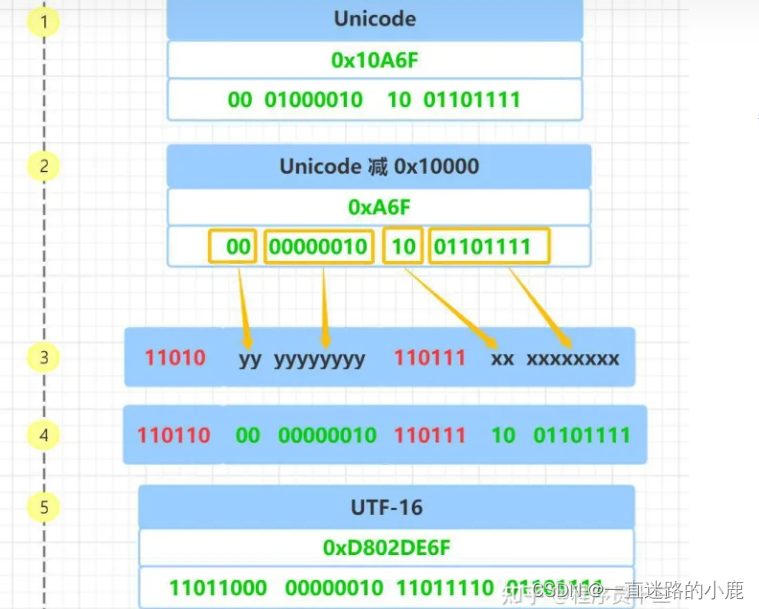
- 对于 Unicode 码小于 0x10000 的字符, 使用 2 个字节存储,并且是直接存储 Unicode 码,不用进行编码转换
- 对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为110111, 前后部分各剩余 10 位二进制表示符号的 Unicode 码 减去 0x10000 的结果
- 大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码
前面提到过,“中” 字的 Unicode 码是 4E2D, 它小于 0x10000,根据表格可知,它的 UTF-16 编码占两个字节,并且和 Unicode 码相同,所以 “中” 字的 UTF-16 编码为 4E2D
下面以这个Unicode 码 0x10A6F 为例来说明 UTF-16 4 字节的编码。
UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 码即可,不需要任何编码转换。虽然浪费了空间,但提高了效率。
URL
- 只有字母和数字[0-9a-zA-Z]、一些特殊符号$-_.+!*'()[不包括双引号]、以及某些保留字(空格转换为+),才可以不经过编码直接用于URL
- 将每一个非安全的ASCII字符都被替换为“%xx”格式,如"中文"使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6
0x96 0x87,经过Url编码之后得到"%E4%B8%AD%E6%96%87"。 - 特殊字符,如# %23, + %20 , / %2F, ? %3F , % %25 , & %26
URL转码代码:
#include<iostream>
#include<stdio.h>
static unsigned char char_to_hex( unsigned char x )
{
return (unsigned char)(x > 9 ? x + 55: x + 48);
}
static int is_alpha_number_char( unsigned char c )
{
if ( (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || (c >= '0' && c <= '9') )
return 1;
return 0;
}
void urlencode( unsigned char * src, int src_len, unsigned char * dest, int dest_len )
{
unsigned char ch;
int len = 0;
while (len < (dest_len - 4) && *src)
{
ch = (unsigned char)*src;
if (*src == ' ')
{
*dest++ = '+';
}
else if (is_alpha_number_char(ch) || strchr("=!~*'()", ch))
{
*dest++ = *src;
}
else
{
*dest++ = '%';
*dest++ = char_to_hex( (unsigned char)(ch >> 4) );
*dest++ = char_to_hex( (unsigned char)(ch % 16) );
}
++src;
++len;
}
*dest = 0;
return ;
}
int urldecode(unsigned char* encd,unsigned char* decd)
{
unsigned int j = 0,i = 0;
char *cd =(char*) encd;
char p[2];
for( i = 0; i < strlen(cd); i++ )
{
memset( p, 0, 2 );
if( cd[i] != '%' )
{
if (cd[i] == '+')
{
decd[j ++] = ' ';
continue;
}else{
decd[j++] = cd[i];
continue;
}
}else{
p[0] = cd[++i];
p[1] = cd[++i];
p[0] = p[0] - 48 - ((p[0] >= 'A') ? 7 : 0) - ((p[0] >= 'a') ? 32 : 0);
p[1] = p[1] - 48 - ((p[1] >= 'A') ? 7 : 0) - ((p[1] >= 'a') ? 32 : 0);
decd[j++] = (unsigned char)(p[0] * 16 + p[1]);
}
}
decd[j] = 0;
return j;
}
BASE64
将要编码的二进制按照每6位展开并当作索引,在查找表中“ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890+/"64个字母中,找到索引对应的字母并替换。例如”ab"被编码为“YWI=”。“ab” = “01100001 01100010” = “011000 010110 001000 000000”=“YWI=”。可见在将字节转化为6位时,高2位是0。并且如果长度不是3个字节为单位,末尾要补充0到长度为32位的长度,如果添加的长度是8位则末尾添加=,如果添加的长度是16位,则末尾添加==。
base64解码代码例子:
#include <iostream>
static const std::string base64_chars =
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789+/";
static inline bool is_base64(unsigned char c) {
return (isalnum(c) || (c == '+') || (c == '/'));
}
std::string base64_encode(unsigned char const* bytes_to_encode, unsigned int in_len) {
std::string ret;
int i = 0;
int j = 0;
unsigned char char_array_3[3];
unsigned char char_array_4[4];
while (in_len--) {
char_array_3[i++] = *(bytes_to_encode++);
if (i == 3) {
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
for(i = 0; (i <4) ; i++)
ret += base64_chars[char_array_4[i]];
i = 0;
}
}
if (i)
{
for(j = i; j < 3; j++)
char_array_3[j] = '\0';
char_array_4[0] = (char_array_3[0] & 0xfc) >> 2;
char_array_4[1] = ((char_array_3[0] & 0x03) << 4) + ((char_array_3[1] & 0xf0) >> 4);
char_array_4[2] = ((char_array_3[1] & 0x0f) << 2) + ((char_array_3[2] & 0xc0) >> 6);
char_array_4[3] = char_array_3[2] & 0x3f;
for (j = 0; (j < i + 1); j++)
ret += base64_chars[char_array_4[j]];
while((i++ < 3))
ret += '=';
}
return ret;
}
int base64_decode(unsigned char * encoded_string,int in_len,unsigned char * ret) {
//int in_len = encoded_string.size();
int i = 0;
int j = 0;
int in_ = 0;
int out_ = 0;
unsigned char char_array_4[4] = {0}, char_array_3[3] = {0};
//std::string ret;
while (in_len-- && ( encoded_string[in_] != '=') && is_base64(encoded_string[in_])) {
char_array_4[i++] = encoded_string[in_];
in_++;
if (i ==4) {
for (i = 0; i <4; i++){
char_array_4[i] = base64_chars.find(char_array_4[i]);
}
char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4);
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
for (i = 0; (i < 3); i++){
//ret += char_array_3[i];
ret[out_] = char_array_3[i];
out_ ++;
}
i = 0;
}
//memset(char_array_4,0,4);
//memset(char_array_3,0,3);
}
if (i) {
for (j = i; j <4; j++)
char_array_4[j] = 0;
for (j = 0; j <4; j++)
char_array_4[j] = base64_chars.find(char_array_4[j]);
char_array_3[0] = (char_array_4[0] << 2) + ((char_array_4[1] & 0x30) >> 4);
char_array_3[1] = ((char_array_4[1] & 0xf) << 4) + ((char_array_4[2] & 0x3c) >> 2);
char_array_3[2] = ((char_array_4[2] & 0x3) << 6) + char_array_4[3];
for (j = 0; (j < i - 1); j++){
//ret += char_array_3[j];
ret[out_] = char_array_3[j];
out_ ++;
}
}
*(ret + out_) = 0;
return out_;
}
BOM
BOM 是 byte-order mark 的缩写,是 “字节序标记” 的意思, 它常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32 编码的标记。
在 Unicode 编码中有一个叫做 “零宽度非换行空格” 的字符 ( ZERO WIDTH NO-BREAK SPACE ), 用字符 FEFF 来表示。
对于 UTF-16 ,如果接收到以 FEFF 开头的字节流, 就表明是大端字节序,如果接收到 FFFE, 就表明字节流 是小端字节序。
UTF-8 没有字节序问题,上述字符只是用来标识它是 UTF-8 文件,而不是用来说明字节顺序的。“零宽度非换行空格” 字符 的 UTF-8 编码是 EF BB BF, 所以如果接收到以 EF BB BF 开头的字节流,就知道这是UTF-8 文件。
gzip编码
gzip解码例子程序:
#include "zlib.h"
#include "zconf.h"
#pragma comment(lib,"zlib.lib")
/* HTTP gzip decompress */
int httpgzdecompress(Byte *zdata, uLong nzdata,Byte *data, uLong *ndata)
{
int err = 0;
z_stream d_stream = { 0 }; /* decompression stream */
static char dummy_head[2] =
{
0x8 + 0x7 * 0x10,
(((0x8 + 0x7 * 0x10) * 0x100 + 30) / 31 * 31) & 0xFF,
};
d_stream.zalloc = (alloc_func)0;
d_stream.zfree = (free_func)0;
d_stream.opaque = (voidpf)0;
d_stream.next_in = zdata;
d_stream.avail_in = 0;
d_stream.next_out = data;
//if (inflateInit2(&d_stream, -MAX_WBITS) != Z_OK) return -1;
if (inflateInit2(&d_stream, 47) != Z_OK) return -1;
while (d_stream.total_out < *ndata && d_stream.total_in < nzdata) {
d_stream.avail_in = d_stream.avail_out = 1; /* force small buffers */
if ((err = inflate(&d_stream, Z_NO_FLUSH)) == Z_STREAM_END) break;
if (err != Z_OK)
{
if (err == Z_DATA_ERROR)
{
d_stream.next_in = (Bytef*)dummy_head;
d_stream.avail_in = sizeof(dummy_head);
if ((err = inflate(&d_stream, Z_NO_FLUSH)) != Z_OK)
{
return -1;
}
}
else return -1;
}
}
if (inflateEnd(&d_stream) != Z_OK) return -1;
*ndata = d_stream.total_out;
return 0;
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









