







1.环境、模型、数据准备
1.1环境:使用之前教程配置好文件
conda activate llama3`
1.2模型准备
InternStudio软连接
Llama3-8B-Instruct模型
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct .
Visual Encoder 权重
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/openai/clip-vit-large-patch14-336 .
Image Projector 权重
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/xtuner/llama3-llava-iter_2181.pth .
1.3 数据准备
cd ~
git clone https://github.com/InternLM/tutorial -b camp2
python ~/tutorial/xtuner/llava/llava_data/repeat.py \
-i ~/tutorial/xtuner/llava/llava_data/unique_data.json \
-o ~/tutorial/xtuner/llava/llava_data/repeated_data.json \
-n 200
2.微调过程
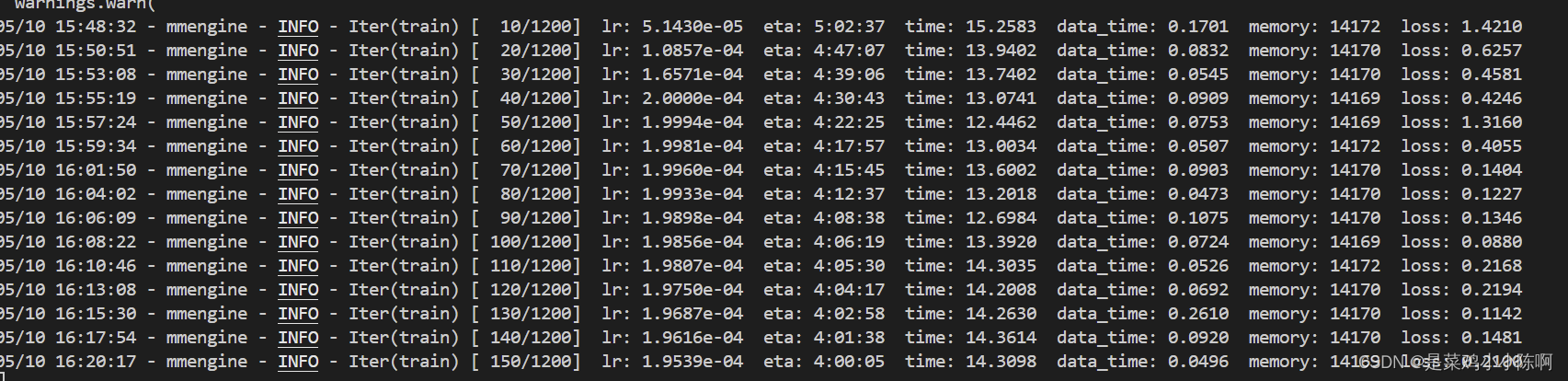
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2
训练报错,先安装deepspeed,重试
30%的A100不够用,加上offload
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2_offload
3.效果体验
问题1:Describe this image.
问题2:What is the equipment in the image?
Pretrain 模型
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
--visual-encoder /root/model/clip-vit-large-patch14-336 \
--llava /root/llama3_llava_pth/pretrain_iter_2181_hf \
--prompt-template llama3_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg
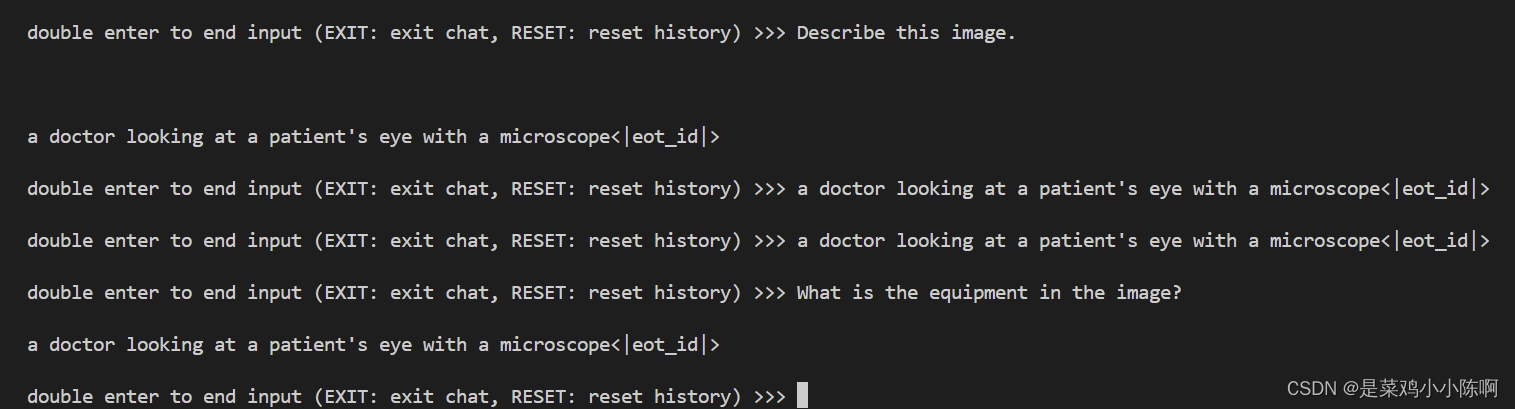
Finetune 后 模型
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
--visual-encoder /root/model/clip-vit-large-patch14-336 \
--llava /root/llama3_llava_pth/iter_1200_hf \
--prompt-template llama3_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg

















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









