







简介
Querying Transformer,在冻结的视觉模型和大语言模型间进行视觉-语言对齐。
为了使Q-Former的学习达到两个目标:
-
学习到和文本最相关的视觉表示。
-
这种表示能够为大语言模型所解释。
需要在Q-Former结构设计和训练策略上下功夫。具体来说,
-
Q-Former是一个轻量级的transformer,它使用一个可学习的query向量集,从冻结的视觉模型提取视觉特征。
-
采取两阶段预训练策略
-
阶段一:vision-language表示学习(representation learning),迫使Q-Former学习和文本最相关的视觉表示。
- 阶段二:vision-to-language生成式学习(generative learning),将Q-Former的输出连接到冻结的大语言模型,迫使Q-Former学习到的视觉表示能够为大语言模型所解释。
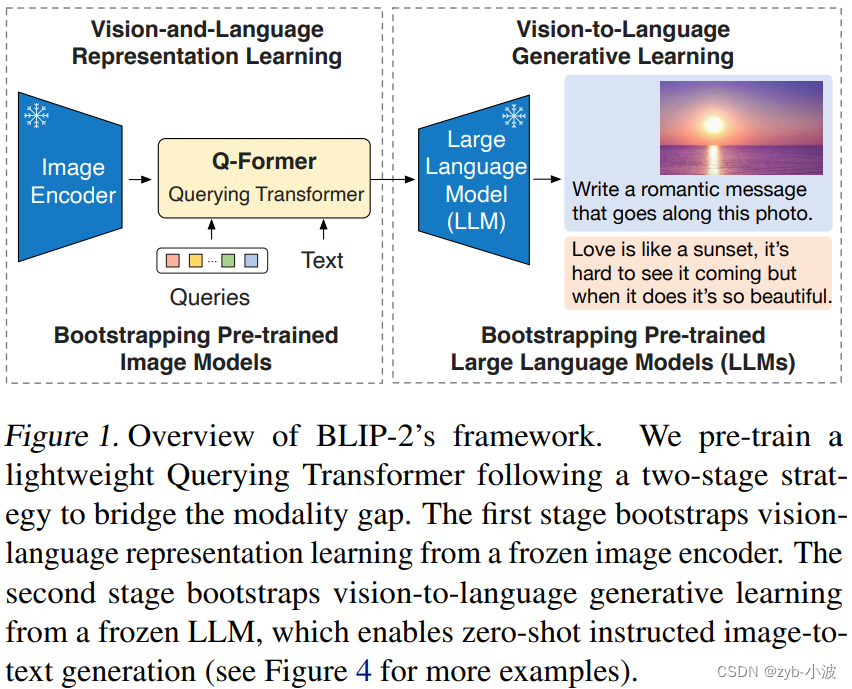
Q-former结构
https://zhuanlan.zhihu.com/p/649132737
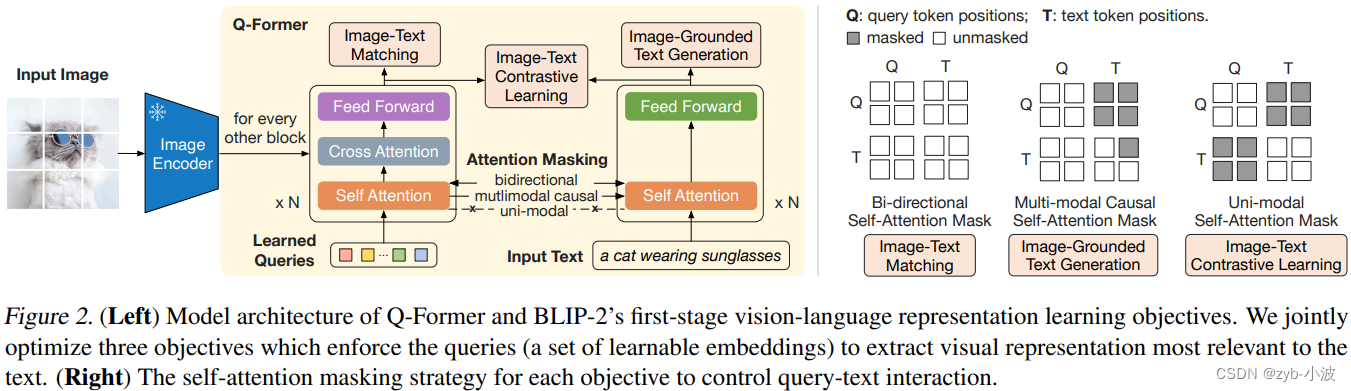
Q-Former由两个transfomer子模块组成,左边为(learnable) query encoder,右边为text encoder & decoder。记视觉模型的image encoder的输出为I。左边网络的(learnable) query为Q,右边网络的输入text为T。注意Q是一个向量集,非单个向量。它可以视为Q-Former的参数。
-
左边的transformer和视觉模型image encoder交互,提取视觉表征,右边的transformer同时作为text encoder和decoder。
-
左边的query encoder和右边的text encoder共享self-attention layer。
-
通过self attention layer,实现Q向量之间的交互。
-
通过cross attention layer,实现Q向量和I的交互。
-
Q和T之间的交互,也是通过共享的self attention layer实现的,不过根据训练目标的不同,通过不同的attention mask来实现不同的交互。
不同的交互任务如下:
-
ITC,使用单模态视觉和大语言模型各自的注意力掩码,Q向量和T之间没有交互。
-
ITM,使用双向注意力机制掩码(MLM),实现Q向量和T之间的任意交互。Q向量可以attention T,T也可以attention Q向量。
-
ITG,使用单向注意力机制掩码(CLM),实现Q向量和T之间的部分交互。Q向量不能attention T,T中的text token可以attention Q向量和前面的text tokens。
图文匹配任务与图文对比学习的主要区别是,引入了图文之间的cross attention,进行细粒度的图像和文本匹配用来预测,可以理解为单塔模型和双塔模型的区别
二阶段训练
阶段1
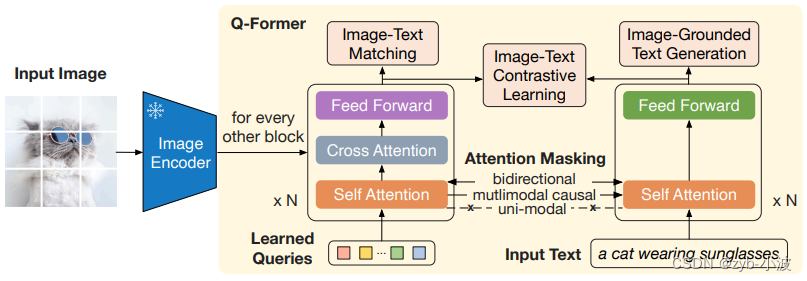 这个阶段使用image-text对进行多目标训练(ITC+ITM+ITG)。
这个阶段使用image-text对进行多目标训练(ITC+ITM+ITG)。
这三个目标都是将视觉表示和文本表示T进行对齐,学习到最匹配文本的视觉表示。
这个多目标训练是在BLIP论文中提出的。在BLIP论文中提到,之所以同时训练三个目标,是为了让学习到的视觉表示可以同时做理解和生成下游任务。
ITC和ITM主要是为了适应图片分类、图片检索、VQA等理解类任务。ITG主要是为了适应Captioning等生成类任务。
ITC是对比学习,通过最大化positive image-text pair,最小化negative image-text pair。而ITM是二分类模型,加入一个linear layer,直接给image-text pair打分。
由于训练ITC目标时,为了防止信息泄露,image和text不能attention彼此,捕捉到的image-text交互信息有限。训练ITM允许image和text互相attention,而且是双向的,来捕捉到更细粒度的image-text交互信息。同时训练ITC、ITM这两个目标,互补一下,以更好地进行image-text对齐。
ITG目标的作用是训练Q-Former,让它具有在给定图片的情况下,生成文本的能力。
右边transformer,在ITC和ITM目标训练中,作为encoder,在ITG目标训练中,作为decoder。
阶段2
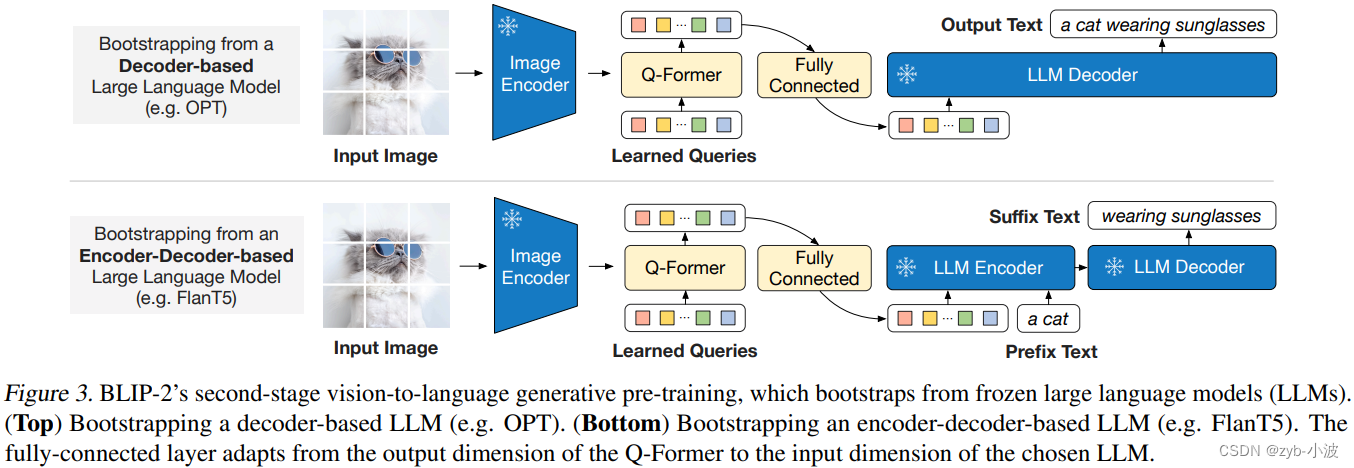 分别展示了对于decoder-only和encoder-decoder架构的大语言模型,预训练阶段二的示意图。
分别展示了对于decoder-only和encoder-decoder架构的大语言模型,预训练阶段二的示意图。
这个阶段是比较简单的,通过一个linear layer将Q-Former输出投射(project)成一个向量(和大语言模型的embedding一样维度),将它拼接到大语言模型的输入text的embedding前面,相当于一个soft prompt。
将Q-Former学习的文本和图像向量,加上一个全连接层(一个Linear,从768维到2560维),然后输入到大预言模型,预测文本输出。
-
Decoder only:将Q-former学到token直接输入,得到文本输出,论文中采用facebook的opt模型进行训练。
-
encoder-decoder:将Q-former学到token加上前缀词(如图中的a cat)一起输入,得到后续的文本输出,论文中采用FlanT5添加指令进行训练。
代码实现
-
Qformer初始化
encoder参考bert的encoder,偶数层增加cross_attention层
def init_Qformer(cls, num_query_token, vision_width, cross_attention_freq=2):
# encoder_config = BertConfig.from_pretrained("bert-base-uncased")
encoder_config = BertConfig.from_pretrained("./models/bert-base-uncased")
encoder_config.encoder_width = vision_width
# insert cross-attention layer every other block
encoder_config.add_cross_attention = True
encoder_config.cross_attention_freq = cross_attention_freq
encoder_config.query_length = num_query_token
Qformer = BertLMHeadModel(config=encoder_config)
query_tokens = nn.Parameter(
torch.zeros(1, num_query_token, encoder_config.hidden_size)
)
query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range)
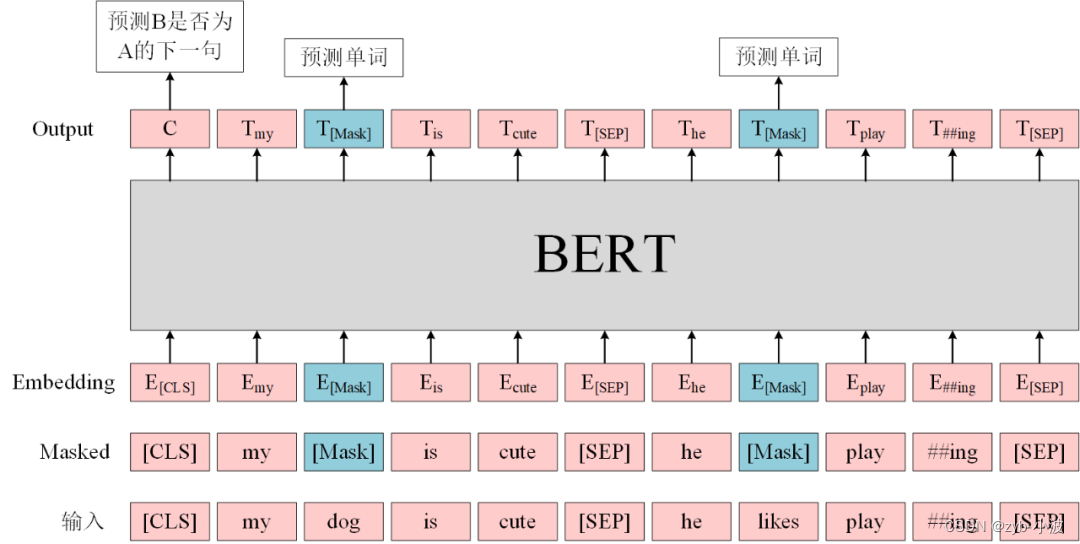
return Qformer, query_tokensBERT 预训练任务包括两个:
-
Masked Language Model(MLM):在句子中随机用
[MASK]替换一部分单词,然后将句子传入 BERT 中编码每一个单词的信息,最终用[MASK]的编码信息预测该位置的正确单词,这一任务旨在训练模型根据上下文理解单词的意思; -
Next Sentence Prediction(NSP):将句子对 A 和 B 输入 BERT,使用
[CLS]的编码信息进行预测 B 是否 A 的下一句,这一任务旨在训练模型理解预测句子间的关系。
 https://tianchi.aliyun.com/forum/post/336298
https://tianchi.aliyun.com/forum/post/336298
-
BertForMaskedLM:只进行 MLM 任务的预训练;
-
基于BertOnlyMLMHead,而后者也是对BertLMPredictionHead的另一层封装;
-
-
BertLMHeadModel:这个和上一个的区别在于,这一模型是作为 decoder 运行的版本;
-
同样基于BertOnlyMLMHead;
-
-
BertForNextSentencePrediction:只进行 NSP 任务的预训练。
-
基于BertOnlyNSPHead,内容就是一个线性层。
-


















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











